This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
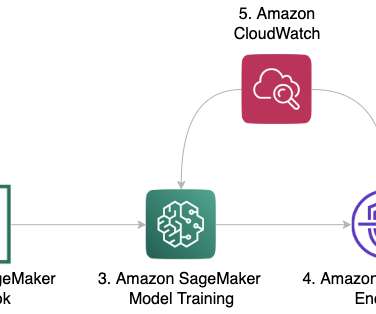
Analyze results through metrics and evaluation. Model customization in Amazon Bedrock involves the following actions: Create training and validation datasets. Set up IAM permissions for data access. Configure a KMS key and VPC. Create a fine-tuning or pre-training job with hyperparameter tuning. Use the custom model for tasks like inference.
The Amazon Bedrock single API access, regardless of the models you choose, gives you the flexibility to use different FMs and upgrade to the latest model versions with minimal code changes. Amazon Titan FMs provide customers with a breadth of high-performing image, multimodal, and text model choices, through a fully managed API.
This process enhances task-specific model performance, allowing the model to handle custom use cases with task-specific performance metrics that meet or surpass more powerful models like Anthropic Claude 3 Sonnet or Anthropic Claude 3 Opus. Under Output data , for S3 location , enter the S3 path for the bucket storing fine-tuning metrics.
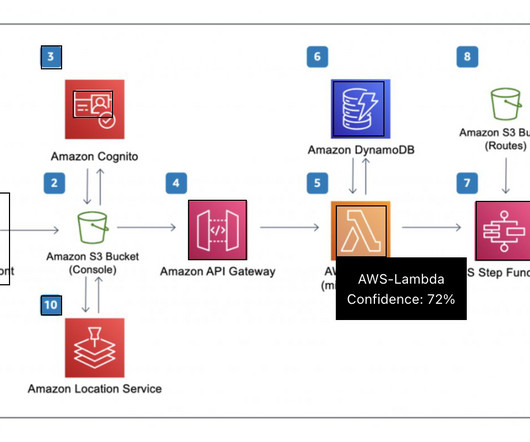
In this post, we address these limitations by implementing the access control outside of the MLflow server and offloading authentication and authorization tasks to Amazon API Gateway , where we implement fine-grained access control mechanisms at the resource level using Identity and Access Management (IAM). Adds an IAM authorizer.
The input data is a multi-variate time series that includes hourly electricity consumption of 321 users from 2012–2014. Amazon Forecast is a time-series forecasting service based on machine learning (ML) and built for business metrics analysis. For HPO, we use the RRSE as the evaluation metric for all the three algorithms.
By uploading a small set of training images, Amazon Rekognition automatically loads and inspects the training data, selects the right ML algorithms, trains a model, and provides model performance metrics. For more details on the different metrics such as precision, recall, and F1, refer to Metrics for evaluation your model.
Upon a new model version registration, someone with the authority to approve the model based on the metrics should approve or reject the model. You can use Boto3 APIs as shown the following example, or you can use the AWS Management Console to create the model package. We combine both policies to get the following final policy.
You can also detect many common issues that affect the readability, reproducibility, and correctness of computational notebooks, such as misuse of ML library APIs, invalid run order, and nondeterminism. To use the CodeWhisperer extension, ensure that you have the necessary permissions.
Members of Generation Z, people born between 1995 and 2012, are entering the workforce and bringing their own ideas about how the workplace should function. Cloud workforce management systems that provide real-time visibility to key metrics enable supervisors to see what agents are doing and if they’re adhering to schedules.
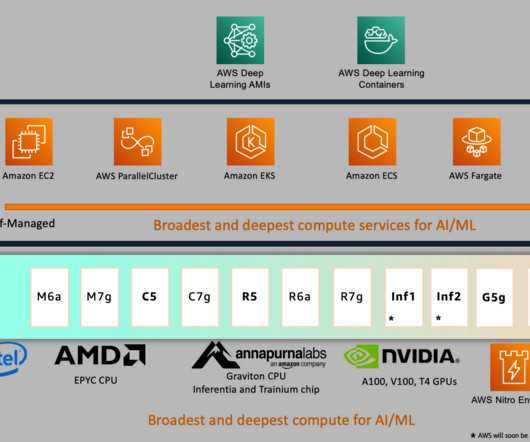
When selecting the AMI, follow the release notes to run this command using the AWS Command Line Interface (AWS CLI) to find the AMI ID to use in us-west-2 : #STEP 1.2 - This requires AWS CLI credentials to call ec2 describe-images api (ec2:DescribeImages). We added the following argument to the trainer API in train_sentiment.py
And, as its mode of operation broadens and becomes more proactive, its success will have to be measured by new metrics, reflecting its critical role in overall business performance. In fact this number increased from 67% in 2012 to 84% in 2015. In 2011 Gartner predicted that. However, in 2016 Forrester has already reported that.
And in 2012, I decided to make the jump to the indirect or referral partner channels, where a lot of these big Gartner ranked vendors across contact center and unified communications and networking have these really robust programs that enable partners, or referral brokers, or agents to basically add value around the purchasing process.
In terms of resulting speedups, the approximate order is programming hardware, then programming against PBA APIs, then programming in an unmanaged language such as C++, then a managed language such as Python. in 2012 is now widely referred to as ML’s “Cambrian Explosion.” The CUDA API and SDK were first released by NVIDIA in 2007.
You can call the specific container directly in the API call and get the prediction from that model. Now we can call the endpoint for inference and define the TargetContainerHostname as either englishModel or germanModel depending on the client making the API call: sm.invoke_endpoint(. response = runtime.invoke_endpoint(.
if there are multiple, you can fetch available pipelines using boto3 api #and trigger the appropriate one based on your logic. The following piece of code illustrates the scenario where two different SageMaker pipeline runs are triggered: import boto3 def lambda_handler(event, context): items = [1, 2] #sagemaker client sm_client = boto3.client("sagemaker")
The Amazon Bedrock Knowledge Bases API also simplified our operations by combining embedding and retrieval functionality into a single API call. This optimization reduced our token usage and minimized unnecessary API calls, resulting in lower latency for each query.
Amazon Bedrock makes it straightforward to adopt any of these choices by providing a common set of APIs, industry-leading embedding models, security, governance, and observability. In this post, we discuss use cases, features, and steps to set up and retrieve information using these vector databases.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
























Let's personalize your content