This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
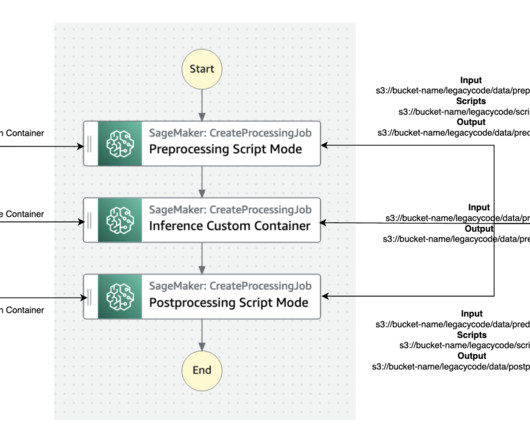
The best practice for migration is to refactor these legacy codes using the Amazon SageMaker API or the SageMaker Python SDK. SageMaker runs the legacy script inside a processing container. Step Functions is a serverless workflow service that can control SageMaker APIs directly through the use of the Amazon States Language.
Amazon Bedrock is a fully managed service that makes FMs from leading AI startups and Amazon available through an API, so you can choose from a wide range of FMs to find the model that is best suited for your use case. Solution overview The solution comprises two main steps: Generate synthetic data using the Amazon Bedrock InvokeModel API.
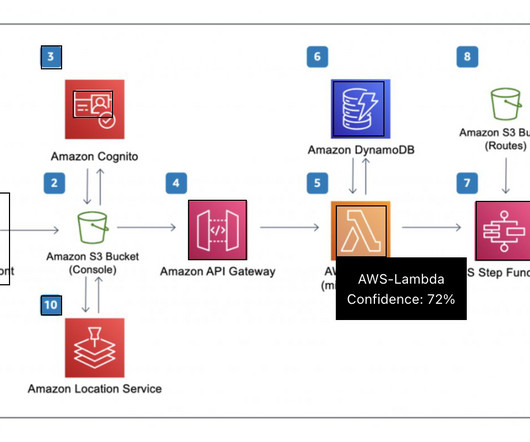
In this post, we address these limitations by implementing the access control outside of the MLflow server and offloading authentication and authorization tasks to Amazon API Gateway , where we implement fine-grained access control mechanisms at the resource level using Identity and Access Management (IAM). Adds an IAM authorizer.
You only consume the services through their API. To understand better how Amazon Cognito allows external applications to invoke AWS services, refer to refer to Secure API Access with Amazon Cognito Federated Identities, Amazon Cognito User Pools, and Amazon API Gateway. We discuss this later in the post.
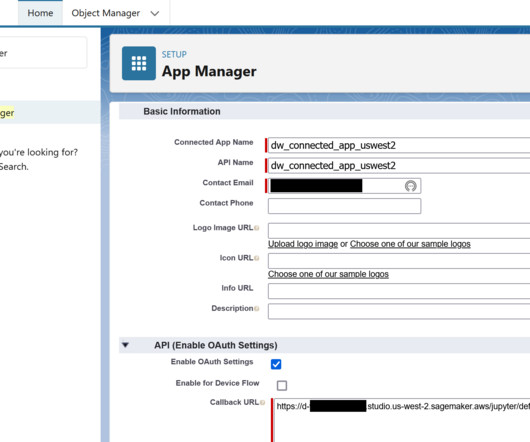
When a version of the model in the Amazon SageMaker Model Registry is approved, the endpoint is exposed as an API with Amazon API Gateway using a custom Salesforce JSON Web Token (JWT) authorizer. frameworks to restrict client access to your APIs. For API Name , leave as default (it’s automatically populated).
In this tutorial, we’ll use a Nexmo Voice number to create a callback script that interacts with a caller to prompt for a voice message. Though the built-in web server should not be used in a production environment, it is fine for sample scripts like this. Make sure to replace {bucket_name} with the actual bucket name.
Therefore, users without ML expertise can enjoy the benefits of a custom labels model through an API call, because a significant amount of overhead is reduced. A Python script is used to aid in the process of uploading the datasets and generating the manifest file. then((response) => { resolve(Buffer.from(response.data, "binary").toString("base64"));
However, if you want to update existing resources to facilitate resource isolation, administrations can use the add-tag SageMaker API call in a script. Since the launch of the multi-domain capability, new resources are automatically tagged with aws:ResourceTag/sagemaker:domain-arn. experiments=`aws --region $REGION.
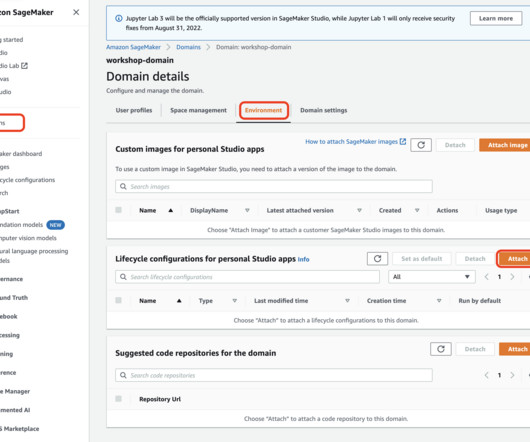
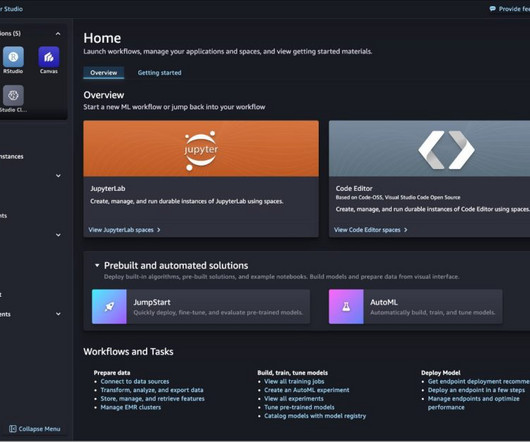
When you open a notebook in Studio, you are prompted to set up your environment by choosing a SageMaker image, a kernel, an instance type, and, optionally, a lifecycle configuration script that runs on image startup. The main benefit is that a data scientist can choose which script to run to customize the container with new packages.
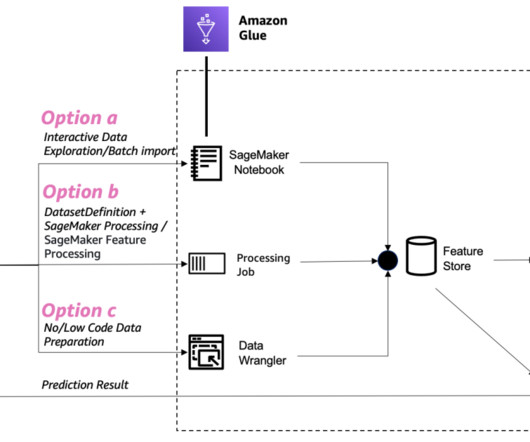
Option B: Use a SageMaker Processing job with Spark In this option, we use a SageMaker Processing job with a Spark script to load the original dataset from Amazon Redshift, perform feature engineering, and ingest the data into SageMaker Feature Store. The environment preparation process may take some time to complete.
Complete the following steps: Download the bootstrap script from s3://emr-data-access-control- /customer-bootstrap-actions/gcsc/replace-rpms.sh , replacing region with your region. Your Studio user’s execution role needs to be updated to allow the GetClusterSessionCredentials API action. SNAPSHOT20221121212949.noarch.rpm. noarch.rpm.
Run your DLC container with a model training script to fine-tune the RoBERTa model. After model training is complete, package the saved model, inference scripts, and a few metadata files into a tar file that SageMaker inference can use and upload the model package to an Amazon Simple Storage Service (Amazon S3) bucket.
The input data is a multi-variate time series that includes hourly electricity consumption of 321 users from 2012–2014. JumpStart features aren’t available in SageMaker notebook instances, and you can’t access them through SageMaker APIs or the AWS Command Line Interface (AWS CLI). Launch the solution.
After you stop the Space, you can modify its settings using either the UI or API via the updated SageMaker Studio interface and then restart the Space. This setup enables you to centrally store notebooks, scripts, and other project files, accessible across all your SageMaker Studio sessions and instances.
Amazon Kendra Intelligent Ranking application programming interface (API) – The functions from this API are used to perform tasks related to provisioning execution plans and semantic re-ranking of your search results. Create and start OpenSearch using the Quickstart script. Download the search_processing_kendra_quickstart.sh
You can run the script by choosing Run in Code Editor or using the CLI in a JupyterLab terminal. The only way to access and interact with Docker images is via the exposed Docker API operations. LCCs are scripts that SageMaker runs during events like space creation. API version: 1.41 (downgraded from 1.43) Go version: go1.20.10
You can then use a script (process.py) to work on a specific portion of the data based on the instance number and the corresponding element in the list of items. if there are multiple, you can fetch available pipelines using boto3 api #and trigger the appropriate one based on your logic. 1", instance_type="ml.m5.xlarge",
The data science team can, for example, use the shared EFS directory to store their Jupyter notebooks, analysis scripts, and other project-related files. You should have an AWS CloudTrail log file that logs the SageMaker API CreateUserProfile. Refer to Creating a trail for your AWS account for additional information.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





















Let's personalize your content