This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Source: Human Resource Management; Issue: 51(4); 2012; Pages 535-548. Metrics, Measure, and Monitor – Make sure your metrics and associated goals are clear and concise while aligning with efficiency and effectiveness. Make each metric public and ensure everyone knows why that metric is measured. Jeff Greenfield.
The pandemic only accelerated the growth of the subscription economy, which has seen an incredible 437% growth since 2012—and a 66% increase from 2019 to 2020. That means sharing policy changes, marketing or sales objectives, goals, and metrics, and ensuring the team understands how their roles impact each of these things.
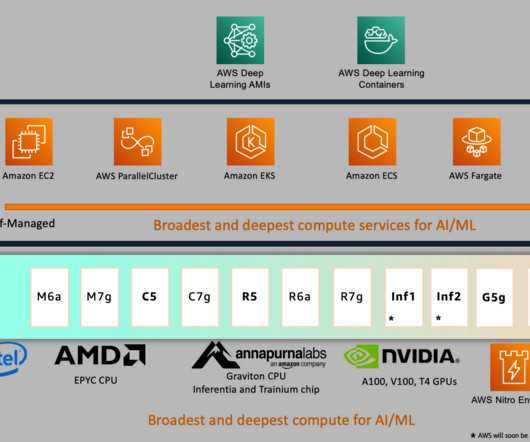
in 2012 is now widely referred to as ML’s “Cambrian Explosion.” Accelerator benchmarking When considering compute services, users benchmark measures such as price-performance, absolute performance, availability, latency, and throughput. There are various types of representative benchmark commonly seen.
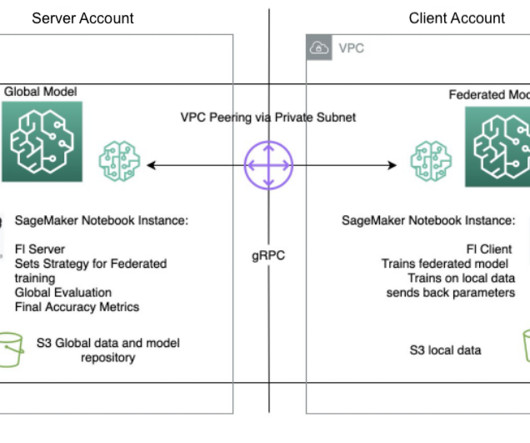
The evaluation takes place on a testing dataset existing only on the server, and the new improved accuracy metrics are produced. She is also part of the Technical Field Community dedicated to hardware acceleration and helps with testing and benchmarking AWS Inferentia and AWS Trainium workloads.
The pandemic only accelerated the growth of the subscription economy, which has seen an incredible 437% growth since 2012—and a 66% increase from 2019 to 2020. That means sharing policy changes, marketing or sales objectives, goals, and metrics, and ensuring the team understands how their roles impact each of these things.
Forrester has found that FAQ page use is on the rise, increasing from 67% to 76% between 2012 and 2014. Free Download] Live Chat Benchmark Report 2018. The latest version of live chat benchmark report is based on real world data and with suggestions from customer service experts. Let us know in the comments below. Download Now.
Spreadsheets Are Still the Most Common Way to Produce Metrics. Over two-thirds of Contact Centers (67.7%) are still using spreadsheets to produce metric results and provide key performance insights into the life of the Contact Center. of Contact Centers still do. Call Centre Helper). Frustrations in the Voice Channel: . Forrester).
The following figure shows a performance benchmark of fine-tuning a RoBERTa model on Amazon EC2 p4d.24xlarge inference with AWS Graviton processors for details on AWS Graviton-based instance inference performance benchmarks for PyTorch 2.0. Training and evaluation metrics are reported at the end of each epoch. DLAMI + DLC.
We’ve shared before that Millennial (born between 1981 and 1996) and Gen Z (born between 1997 and 2012) agents are having major impact on the way today’s contact centers operate. By giving agents visibility into their performance, they can benchmark their efforts against other agents and themselves. billion total people).
And in 2012, I decided to make the jump to the indirect or referral partner channels, where a lot of these big Gartner ranked vendors across contact center and unified communications and networking have these really robust programs that enable partners, or referral brokers, or agents to basically add value around the purchasing process.
These responses are your benchmark. But knowledge retention isn’t the only metric worth looking at. 2012 Allied Workforce Mobility Survey: Onboarding and Retention. Set goals for the next round of new hires and tweak your onboarding structure to help meet those goals. Need ideas? Allied HR IQ. Allied Van Lines. Seibert, S.
As the focus of contact center turns to creating value rather than reducing expenses, KPIs like customer satisfaction and service level will become increasingly favored over metrics like Average Handling Time. FCR is the Most Important Metric. The Value of Metrics. contactcenter #2020trends Click To Tweet. Social Media ?
Vision Instruct models demonstrated impressive performance on the challenging DocVQA benchmark for visual question answering. ANLS is a metric used to evaluate the performance of models on visual question answering tasks, which measures the similarity between the model’s predicted answer and the ground truth answer. The Meta Llama 3.2
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






















Let's personalize your content