This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Using its enterprise software, FloTorch conducted an extensive comparison between Amazon Nova models and OpenAIs GPT-4o models with the Comprehensive Retrieval Augmented Generation (CRAG) benchmark dataset. OpenAI launched GPT-4o in May 2024, and Amazon introduced Amazon Nova models at AWS re:Invent in December 2024.
Sonnet currently ranks at the top of S&P AI Benchmarks by Kensho , which assesses large language models (LLMs) for finance and business. For example, there could be leakage of benchmark datasets’ questions and answers into training data. Anthropic Claude 3.5 Kensho is the AI Innovation Hub for S&P Global. Anthropic Claude 3.5
We are delighted to share that Totango was recognized in the G2 Winter 2024 reports for its exemplary performance in the customer success software category. Totango’s high score from G2 users not only underscores our efficient implementation but also sets a best-in-class benchmark for other software in the customer success category.
Learn how they created specialized agents for different tasks like account management, repos, pipeline management, and more to help their developers go faster. Explore the significant productivity gains and efficiency improvements achieved across the organization.
The analyst may ask questions such as “Show me all wells that produced oil on June 1st 2024,” “What well produced the most oil in June 2024?”, or “Plot the monthly oil production for well XZY for 2024.” has 92% accuracy on the HumanEval code benchmark. Each question requires different treatment, with varying complexity.
By our math, that means nine out of 10 revenue-accountable leaders need a hand getting on the same page as their fellow go-to-market (GTM) counterparts. That way, both teams can use those outcomes as a benchmark of success throughout the customer journey. This doesn’t just provide a useful shared goal.
The 2024 B2B SaaS Benchmarking Survey by SaaS Capital is the most comprehensive and up-to-date source of its kind for SaaS and customer success leaders who want to know where they stand compared to peers and competitors. We’re operating under the concept of rule of 60, with growth account ing for 20% and margins for 40%.
We published a follow-up post on January 31, 2024, and provided code examples using AWS SDKs and LangChain, showcasing a Streamlit semantic search app. A common way to select an embedding model (or any model) is to look at public benchmarks; an accepted benchmark for measuring embedding quality is the MTEB leaderboard.
With GraphStorm, you can build solutions that directly take into account the structure of relationships or interactions between billions of entities, which are inherently embedded in most real-world data, including fraud detection scenarios, recommendations, community detection, and search/retrieval problems. Dataset Num. of nodes Num.
The 2501 version follows previous iterations (Mistral-Small-2409 and Mistral-Small-2402) released in 2024, incorporating improvements in instruction-following and reliability. The model is deployed in a secure AWS environment and under your VPC controls, helping to support data security for enterprise security needs.
Take a mid-2024 dive into these hot CS topics with ChurnZero CEO You Mon Tsang , who recently joined ESG’s Michael Harnum , and Melissa Langworthy for an in-depth discussion on how to retain and grow customers this year and beyond. The post Five essential truths for customer success leaders in mid-2024 appeared first on ChurnZero.
The buffer was implemented after benchmarking the captioning model’s performance. The benchmarking revealed that the model performed optimally when processing batches of images, but underperformed when analyzing individual images. AWS enables us to scale the innovations our customers love most.
Our field organization includes customer-facing teams (account managers, solutions architects, specialists) and internal support functions (sales operations). Personalized content will be generated at every step, and collaboration within account teams will be seamless with a complete, up-to-date view of the customer.
Figure 1: Examples of generative AI for sustainability use cases across the value chain According to KPMG’s 2024 ESG Organization Survey , investment in ESG capabilities is another top priority for executives as organizations face increasing regulatory pressure to disclose information about ESG impacts, risks, and opportunities.
In 2024 alone, 11x more AI models were put into production than last year, showing a clear shift from experimentation to real-world application. These five pillars will help you maximize your return on investment (ROI): Quality Standards Set high benchmarks for accuracy and consistency.
Prerequisites To build the solution yourself, there are the following prerequisites: You need an AWS account with an AWS Identity and Access Management (IAM) role that has permissions to manage resources created as part of the solution (for example AmazonSageMakerFullAccess and AmazonS3FullAccess ).
Laying the groundwork: Collecting ground truth data The foundation of any successful agent is high-quality ground truth data—the accurate, real-world observations used as reference for benchmarks and evaluating the performance of a model, algorithm, or system. None What is the balance for the account 1234? Your appointment ID is XXXX.
What is Mixtral 8x22B Mixtral 8x22B is Mistral AI’s latest open-weights model and sets a new standard for performance and efficiency of available foundation models , as measured by Mistral AI across standard industry benchmarks. making the model available for exploring, testing, and deploying. Therefore, she sold the car for $18,248.33.
Although existing large language model (LLM) benchmarks like MT-bench evaluate model capabilities, they lack the ability to validate the application layers. Begin by creating and testing the agent in your development account. You want to make sure the agent provides correct and reliable information about existing claims to end-users.
On Hugging Face, the Massive Text Embedding Benchmark (MTEB) is provided as a leaderboard for diverse text embedding tasks. It currently provides 129 benchmarking datasets across 8 different tasks on 113 languages. She helps key enterprise customer accounts on their data, generative AI and AI/ML journeys.
In March 2024, AWS announced it will offer the new NVIDIA Blackwell platform, featuring the new GB200 Grace Blackwell chip. Both Inferentia2 and Trainium use the same basic components, but with differing layouts, accounting for the different workloads they are designed to support.
In 2024 alone, hospitality saw a 20% decrease in already troubling customer retention rates. But larger trends like these do not account for all customer attrition. Think about the impact of benchmarking performance, processes, procedures, and even product and experience design and development to customer retention.
In 2024, the fintech industry finds itself at the forefront of technological evolution, driven by the unprecedented surge in digital transactions. Transparency in AI algorithms and governance mechanisms ensures accountability, promoting trust among your users.
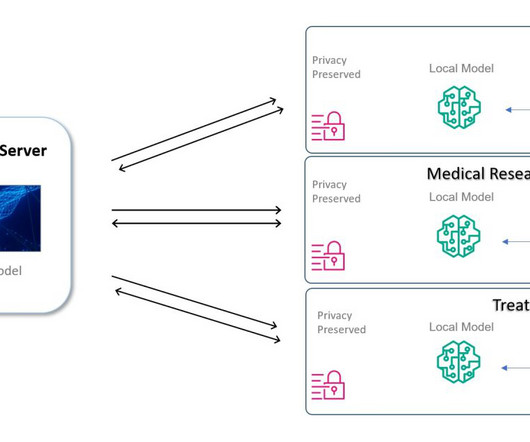
Policies and regulations like General Data Protection Regulation (GDPR), Health Insurance Portability and Accountability Act (HIPPA), and California Consumer Privacy Act (CCPA) put guardrails on sharing data from the medical domain, especially patient data.
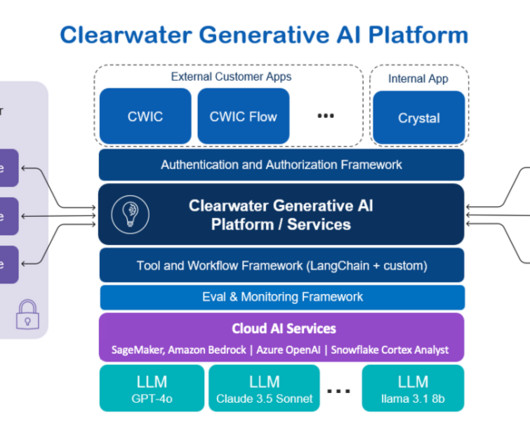
trillion in assets across thousands of accounts worldwide. As of September 2024, the AI solution supports three core applications: Clearwater Intelligent Console (CWIC) Clearwaters customer-facing AI application. Multiple investment policies can be applied to individual accounts and aggregates of accounts.
Enable a data science team to manage a family of classic ML models for benchmarking statistics across multiple medical units. These capabilities are essential for demonstrating compliance with regulatory standards and ensuring transparency and accountability in AI/ML workflows.
More than 80% of business leaders see customer experience as a growing priority in 2024. Every interaction with your business has the power to build or damage the relationship with your customer – and can directly impact your revenue. 78% of customers have backed out of a purchase due to a poor customer experience (CX).
Rocketlane helps SaaS providers provide an accelerated onboarding journey that holds customers accountable, shortens time-to-value, and helps begin expansion conversations earlier (which increases Net Revenue Retention), right from the first touchpoint. This growth follows another significant milestone for the company.
According to FairTest’s website , there are currently 1,900 colleges in the US that offer test-optional or test-blind policies for students seeking to enroll in Fall 2024 or beyond. Objective benchmark : Standardized tests provide schools with a consistent measure that can be compared across all students.
Using the OGSM framework, QBRs focus on quantifiable benchmarks, indicating whether the client is on the right track to achieving their goals. Customer success managers will handle a broader range of accounts with a focus on scaled activities. Predictive analytics will aid in understanding usage patterns and goal alignment.
Using the OGSM framework, QBRs focus on quantifiable benchmarks, indicating whether the client is on the right track to achieving their goals. Customer success managers will handle a broader range of accounts with a focus on scaled activities. Predictive analytics will aid in understanding usage patterns and goal alignment.
Small business proprietors tend to prioritize the operational aspects of their enterprises over administrative tasks, such as maintaining financial records and accounting. While hiring a professional accountant can provide valuable guidance and expertise, it can be cost-prohibitive for many small businesses.
Pixtral 12B overview Pixtral 12B represents Mistrals first VLM and demonstrates strong performance across various benchmarks, outperforming other open models and matching larger models, according to Mistral. Also, make sure that you have the account-level service limit for using ml.p4d.24xlarge 24xlarge or ml.pde.24xlarge
On our SASE management console, the central events page provides a comprehensive view of the events occurring on a specific account. 2024-10-{01/00:00:00--02/00:00:00}. To validate this approach, weve created a benchmark with hundreds of text queries and their corresponding expected JSON outputs.
models demonstrate state-of-the-art performance on a wide range of industry benchmarks and introduce features to help you build a new generation of AI experiences. The maximum concurrency that you can expect for each model will be 16 per account. The default import quota for each account is three models.
This post and the subsequent code implementation were inspired by one of the International Conference on Machine Learning (ICML) 2024 best papers on LLM debates Debating with More Persuasive LLMs Leads to More Truthful Answers. It uses a different dataset, TofuEval. Details on the exact dataset can be found in the GitHub repository.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content