This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
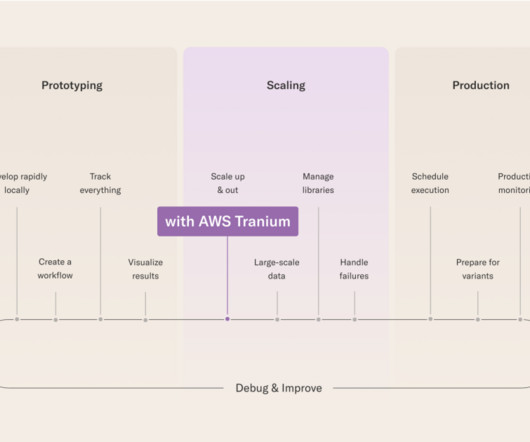
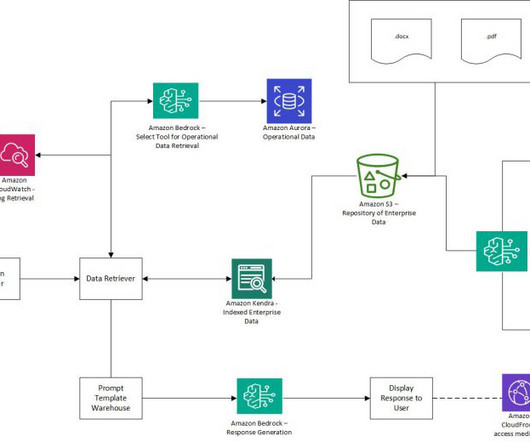
Solution overview Our solution implements a verified semantic cache using the Amazon Bedrock Knowledge Bases Retrieve API to reduce hallucinations in LLM responses while simultaneously improving latency and reducing costs. Lets assume that the question What date will AWS re:invent 2024 occur? is within the verified semantic cache.
Today at AWS re:Invent 2024, we are excited to announce a new feature for Amazon SageMaker inference endpoints: the ability to scale SageMaker inference endpoints to zero instances. You can retrieve the number of copies of an inference component at any time by making the DescribeInferenceComponent API call and checking the CurrentCopyCount.
Seamlessly bring your fine-tuned models into a fully managed, serverless environment, and use the Amazon Bedrock standardized API and features like Amazon Bedrock Agents and Amazon Bedrock Knowledge Bases to accelerate generative AI application development.
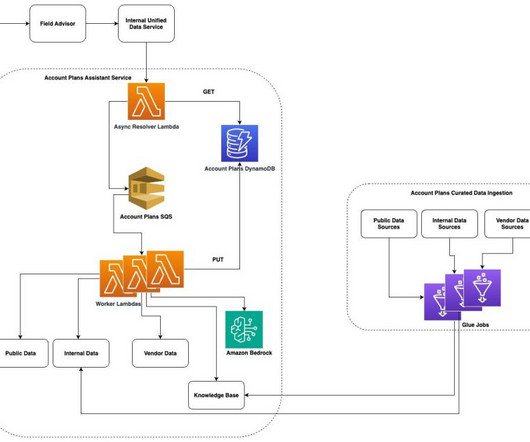
In 2024, this activity took an account manager (AM) up to 40 hours per customer. To help improve this process, in October 2024 we launched an AI-powered account planning draft assistant for our sales teams, building on the success of Field Advisor , an internal sales assistant tool.
OpenAI launched GPT-4o in May 2024, and Amazon introduced Amazon Nova models at AWS re:Invent in December 2024. Amazon Bedrock APIs make it straightforward to use Amazon Titan Text Embeddings V2 for embedding data. The growing need for cost-effective AI models The landscape of generative AI is rapidly evolving.
adds new APIs to customize GraphStorm pipelines: you now only need 12 lines of code to implement a custom node classification training loop. To help you get started with the new API, we have published two Jupyter notebook examples: one for node classification, and one for a link prediction task. Specifically, GraphStorm 0.3
An alternative approach to routing is to use the native tool use capability (also known as function calling) available within the Bedrock Converse API. In this scenario, each category or data source would be defined as a ‘tool’ within the API, enabling the model to select and use these tools as needed.
Programmatic setup Alternatively, you can create your labeling job programmatically using the CreateLabelingJob API. Whether you choose the SageMaker console or API approach, the result is the same: a fully configured labeling job ready for your annotation team.
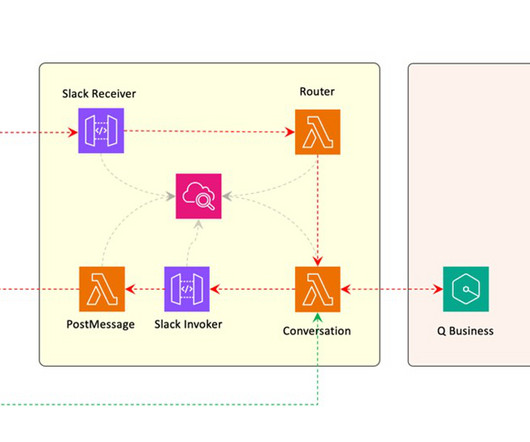
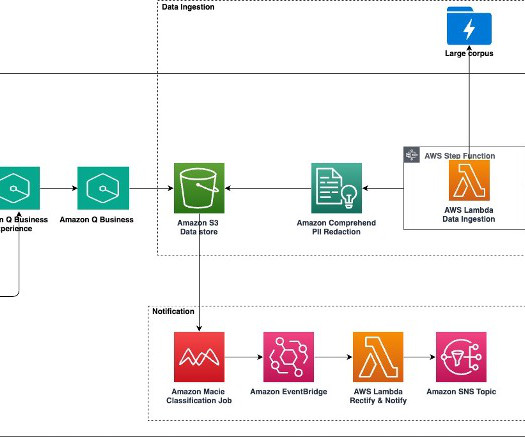
Introducing Field Advisor In April 2024, we launched our AI sales assistant, which we call Field Advisor, making it available to AWS employees in the Sales, Marketing, and Global Services organization, powered by Amazon Q Business. We deliver our chatbot experience through a custom web frontend, as well as through a Slack application.
In business for 145 years, Principal is helping approximately 64 million customers (as of Q2, 2024) plan, protect, invest, and retire, while working to support the communities where it does business and build a diverse, inclusive workforce. 2024, Principal Financial Services, Inc. 3778998-082024
Solution overview This solution is primarily based on the following services: Foundational model We use Anthropics Claude 3.5 Sonnet on Amazon Bedrock as our LLM to generate SQL queries for user inputs. You can limit the number of output tokens to optimize the cost: # Create a Boto3 client for Bedrock Runtime bedrock_runtime = boto3.client(
Step Functions orchestrates AWS services like AWS Lambda and organization APIs like DataStore to ingest, process, and store data securely. For example, the Datastore API might require certain input like date periods to query data. This step can be used to define the date periods to be used by the Map state as an input.
During these live events, F1 IT engineers must triage critical issues across its services, such as network degradation to one of its APIs. This impacts downstream services that consume data from the API, including products such as F1 TV, which offer live and on-demand coverage of every race as well as real-time telemetry.
This blog will delve into the top four customer service trends that are expected to take center stage in 2024. The economic potential of generative AI: The next productivity frontier Of all the customer service trends for 2024, the advent of Generative AI is likely to have the greatest impact.
Lumoa Product News for April 2024 Hey everyone! Note that you will need to be logged in to Lumoa in order to access certain guides: [link] – This is the new place where we will be hosting our API documentation Finnish Knowledge Base – We have some articles translated to Finnish, with more on the way! Thanks for reading!
Agent Creator is a versatile extension to the SnapLogic platform that is compatible with modern databases, APIs, and even legacy mainframe systems, fostering seamless integration across various data environments. The integration with Amazon Bedrock is achieved through the Amazon Bedrock InvokeModel APIs.
The 2501 version follows previous iterations (Mistral-Small-2409 and Mistral-Small-2402) released in 2024, incorporating improvements in instruction-following and reliability. At the time of writing this post, you can use the InvokeModel API to invoke the model. It doesnt support Converse APIs or other Amazon Bedrock tooling.
Amazon Bedrock is a fully managed service that makes foundation models (FMs) from leading AI startups and Amazon available through an API, so you can choose from a wide range of FMs to find the model that’s best suited for your use case. The deployment will output the API Gateway endpoint URL and an API key.
Starting in Q1 2024, customers can engage with researchers and ML scientists from the Generative AI Innovation Center to fine-tune Anthropic Claude models securely with their own proprietary data. Today, we are excited to announce the AWS Generative AI Innovation Center Custom Model Program for Anthropic Claude.
Use hybrid search and semantic search options via SDK When you call the Retrieve API, Knowledge Bases for Amazon Bedrock selects the right search strategy for you to give you most relevant results. You have the option to override it to use either hybrid or semantic search in the API.
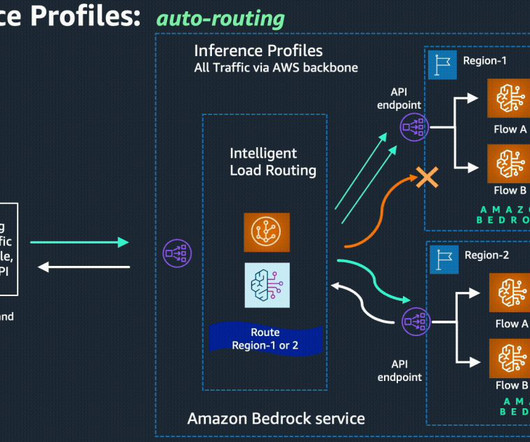
During re:Invent 2024, we launched latency-optimized inference for foundation models (FMs) in Amazon Bedrock. This challenge is compounded by the increasing complexity of modern LLM applications, where multiple LLM calls are often needed to solve a single problem, significantly increasing total processing times. Haiku model and Metas Llama 3.1
Moreover, this capability prioritizes the connected Amazon Bedrock API source/primary region when possible, helping to minimize latency and improve responsiveness. Compatibility with existing Amazon Bedrock API No additional routing or data transfer cost and you pay the same price per token for models as in your source/primary region.
Amazon Lookout for Equipment , the AWS machine learning (ML) service designed for industrial equipment predictive maintenance, will no longer be open to new customers effective October 17, 2024.
red teaming) In April 2024, we announced the general availability of Guardrails for Amazon Bedrock and Model Evaluation in Amazon Bedrock to make it easier to introduce safeguards, prevent harmful content, and evaluate models against key safety and accuracy criteria. In February 2024, Amazon joined the U.S.
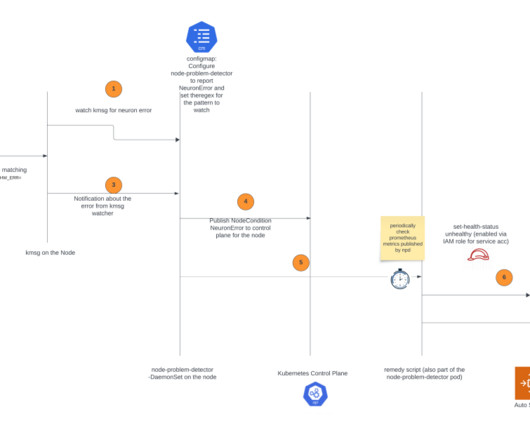
If it detects error messages specifically related to the Neuron device (which is the Trainium or AWS Inferentia chip), it will change NodeCondition to NeuronHasError on the Kubernetes API server. The node recovery agent is a separate component that periodically checks the Prometheus metrics exposed by the node problem detector.
Additionally, Q Business conversation APIs employ a layer of privacy protection by leveraging trusted identity propagation enabled by IAM Identity Center. Amazon Q Business comes with rich API support to perform administrative tasks or to build an AI-assistant with customized user experience for your enterprise.
At re:Invent 2024, we are excited to announce new capabilities to speed up your AI inference workloads with NVIDIA accelerated computing and software offerings on Amazon SageMaker. This post is co-written with Abhishek Sawarkar, Eliuth Triana, Jiahong Liu and Kshitiz Gupta from NVIDIA.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading artificial intelligence (AI) companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API. This change allows you to use metadata fields during the retrieval process.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies, like Meta, through a single API, along with a broad set of capabilities you need to build generative AI applications with security, privacy, and responsible AI. Configure Llama 3.2 b64encode(image_bytes).decode('utf-8')
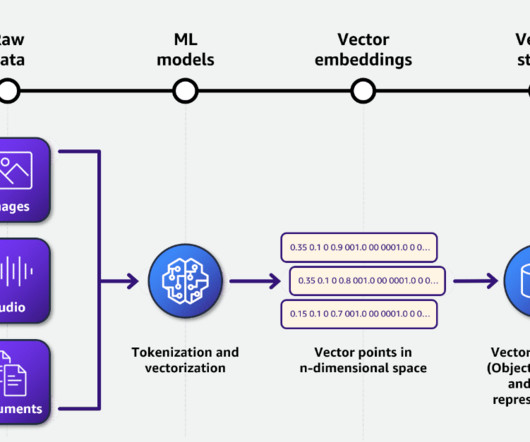
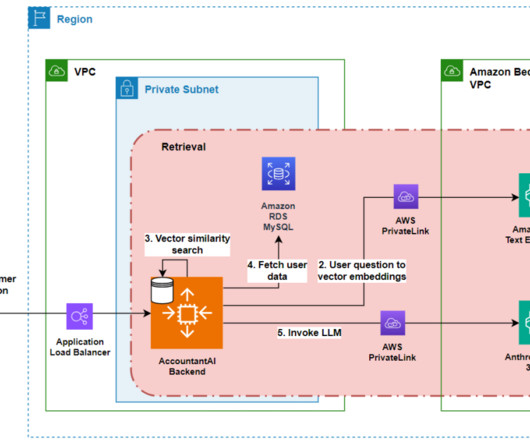
The ingestion workflow transforms these curated questions into vector embeddings using Amazon Titan Text Embeddings model API. Specific accounting knowledge that is relevant to the question and the model is not familiar with, such as updated data for 2024. The vector embeddings are persisted in the application in-memory vector store.
WEM is becoming an open enterprise-grade platform of interoperable applications built with microservices and application programming interfaces (APIs). Learn more at dmgconsult.com. # # # The post DMG Consulting Releases 2023 – 2024 Enterprise Workforce Engagement Management Product and Market Report appeared first on DMG Consulting.
Amazon EKS creates a highly available endpoint for the managed Kubernetes API server that you use to communicate with your cluster (using tools like kubectl). The managed endpoint uses Network Load Balancer to load balance Kubernetes API servers. This VPC doesn’t appear in the customer account. Replace the Instance.
In 2024, however, organizations are using large language models (LLMs), which require relatively little focus on NLP, shifting research and development from modeling to the infrastructure needed to support LLM workflows. This often means the method of using a third-party LLM API won’t do for security, control, and scale reasons.
This year, like no other, we will see organizations tap into APIs to sidestep the complexity and cost of developing and maintaining their own AI solutions and models. In pursuit of digital… Read more on Cisco Blogs
AWS CloudTrail is also essential for maintaining security and compliance in your AWS environment by providing a comprehensive log of all API calls and actions taken across your AWS account, enabling you to track changes, monitor user activities, and detect suspicious behavior. Enable CloudWatch cross-account observability.
In this blog post, we will introduce how to use an Amazon EC2 Inf2 instance to cost-effectively deploy multiple industry-leading LLMs on AWS Inferentia2 , a purpose-built AWS AI chip, helping customers to quickly test and open up an API interface to facilitate performance benchmarking and downstream application calls at the same time.
In April 2024, we announced the general availability of Amazon Bedrock Guardrails to help you introduce safeguards, prevent harmful content, and evaluate models against key safety criteria. You can create a guardrail using the Amazon Bedrock console, infrastructure as code (IaC), or the API.
In the article, we’re going to discuss how VoIP works and why it’s a great choice for your business, with some of the best VoIP service providers in 2024. billion by 2024, growing at a CAGR of 9.1% from 2019 to 2024. Here are some of the top VoIP service providers in 2024. Connecting Call Centers to Success.
FAST has earned a fourth consecutive leader ranking in the 2024 ISG Provider Lens report for its seamless integration with Verisk’s data, analytics, and claims tools. Through some slick prompt engineering and using Claude’s latest capabilities to invoke APIs, Verisk seamlessly accessed their database to procure real-time information.
At the 2024 NVIDIA GTC conference, we announced support for NVIDIA NIM Inference Microservices in Amazon SageMaker Inference. This allows developers to take advantage of the power of these advanced models using SageMaker APIs and just a few lines of code, accelerating the deployment of cutting-edge AI capabilities within their applications.
Though no known incidents are currently associated with the tool, security firm PromptArmor reported in August 2024 that it contained a prompt injection vulnerability. Even if your employees do everything right, there’s still the risk of data exfiltrationor potentially even a data breachwithout proper safeguards.
The workflow invokes the Amazon Bedrock CreateModelCustomizationJob API synchronously to fine tune the base model with the training data from the S3 bucket and the passed-in hyperparameters. The parent state machine calls the child state machine to evaluate the performance of the custom model with respect to the base model. hours to complete!
You might be able to get the same results from an AI API that Google or Amazon have offered for the past decade, which have significantly more real-world testing. GPTs can do these tasks well, but they come with their own pros and cons. Don’t rush to buy something new just because it has a ‘GPT-powered’ sticker on it.
medium instance to demonstrate deploying the model as an API endpoint using an SDK through SageMaker JumpStart. sess = sagemaker.session.Session() # sagemaker session for interacting with different AWS APIs region = sess._region_name To demonstrate this solution, a sample notebook is available in the GitHub repo.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content