This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Using its enterprise software, FloTorch conducted an extensive comparison between Amazon Nova models and OpenAIs GPT-4o models with the Comprehensive Retrieval Augmented Generation (CRAG) benchmark dataset. OpenAI launched GPT-4o in May 2024, and Amazon introduced Amazon Nova models at AWS re:Invent in December 2024.
adds new APIs to customize GraphStorm pipelines: you now only need 12 lines of code to implement a custom node classification training loop. To help you get started with the new API, we have published two Jupyter notebook examples: one for node classification, and one for a link prediction task. Specifically, GraphStorm 0.3
An alternative approach to routing is to use the native tool use capability (also known as function calling) available within the Bedrock Converse API. In this scenario, each category or data source would be defined as a ‘tool’ within the API, enabling the model to select and use these tools as needed.
During re:Invent 2024, we launched latency-optimized inference for foundation models (FMs) in Amazon Bedrock. Consider benchmarking your user experience to find the best latency for your use case, considering that most humans cant read faster than 225 words per minute and therefore extremely fast response can hinder user experience.
The 2501 version follows previous iterations (Mistral-Small-2409 and Mistral-Small-2402) released in 2024, incorporating improvements in instruction-following and reliability. At the time of writing this post, you can use the InvokeModel API to invoke the model. It doesnt support Converse APIs or other Amazon Bedrock tooling.
red teaming) In April 2024, we announced the general availability of Guardrails for Amazon Bedrock and Model Evaluation in Amazon Bedrock to make it easier to introduce safeguards, prevent harmful content, and evaluate models against key safety and accuracy criteria. In February 2024, Amazon joined the U.S.
We published a follow-up post on January 31, 2024, and provided code examples using AWS SDKs and LangChain, showcasing a Streamlit semantic search app. A common way to select an embedding model (or any model) is to look at public benchmarks; an accepted benchmark for measuring embedding quality is the MTEB leaderboard.
In this blog post, we will introduce how to use an Amazon EC2 Inf2 instance to cost-effectively deploy multiple industry-leading LLMs on AWS Inferentia2 , a purpose-built AWS AI chip, helping customers to quickly test and open up an API interface to facilitate performance benchmarking and downstream application calls at the same time.
On Hugging Face, the Massive Text Embedding Benchmark (MTEB) is provided as a leaderboard for diverse text embedding tasks. It currently provides 129 benchmarking datasets across 8 different tasks on 113 languages. medium instance to demonstrate deploying the model as an API endpoint using an SDK through SageMaker JumpStart.
Figure 1: Examples of generative AI for sustainability use cases across the value chain According to KPMG’s 2024 ESG Organization Survey , investment in ESG capabilities is another top priority for executives as organizations face increasing regulatory pressure to disclose information about ESG impacts, risks, and opportunities.
In addition, they use the developer-provided instruction to create an orchestration plan and then carry out the plan by invoking company APIs and accessing knowledge bases using Retrieval Augmented Generation (RAG) to provide an answer to the user’s request. user id 111 Today: 09/03/2024 Certainly! Your appointment ID is XXXX.
Although existing large language model (LLM) benchmarks like MT-bench evaluate model capabilities, they lack the ability to validate the application layers. Evaluator considerations By default, evaluators use the InvokeModel API with On-Demand mode, which will incur AWS charges based on input tokens processed and output tokens generated.
What is Mixtral 8x22B Mixtral 8x22B is Mistral AI’s latest open-weights model and sets a new standard for performance and efficiency of available foundation models , as measured by Mistral AI across standard industry benchmarks. making the model available for exploring, testing, and deploying. Therefore, she sold the car for $18,248.33.
From the period of September 2023 to March 2024, sellers leveraging GenAI Account Summaries saw a 4.9% This involves benchmarking new models against our current selections across various metrics, running A/B tests, and gradually incorporating high-performing models into our production pipeline. The impact goes beyond just efficiency.
In January 2024, Amazon SageMaker launched a new version (0.26.0) In this post, we explore the latest features introduced in this release, examine performance benchmarks, and provide a detailed guide on deploying new LLMs with LMI DLCs at high performance. of Large Model Inference (LMI) Deep Learning Containers (DLCs).
Furthermore, model hosting on Amazon SageMaker JumpStart can help by exposing the endpoint API without sharing model weights. It also takes away potential high-level compute challenges with on-premises hardware with Amazon Elastic Compute Cloud (Amazon EC2) resources.
Enable a data science team to manage a family of classic ML models for benchmarking statistics across multiple medical units. Users from several business units were trained and onboarded to the platform, and that number is expected to grow in 2024. Another important metric is the efficiency for data science users.
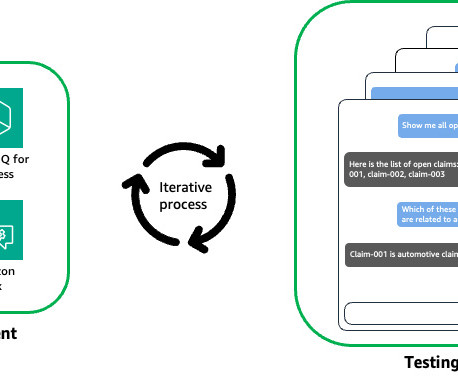
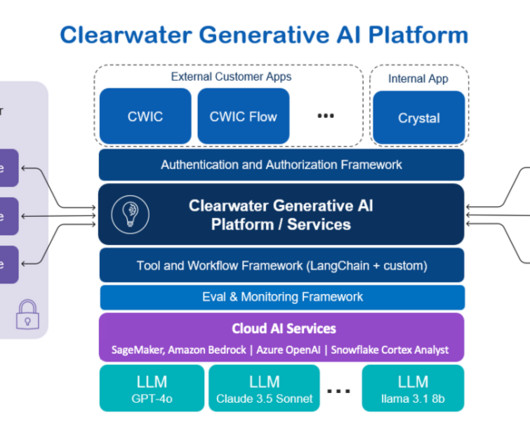
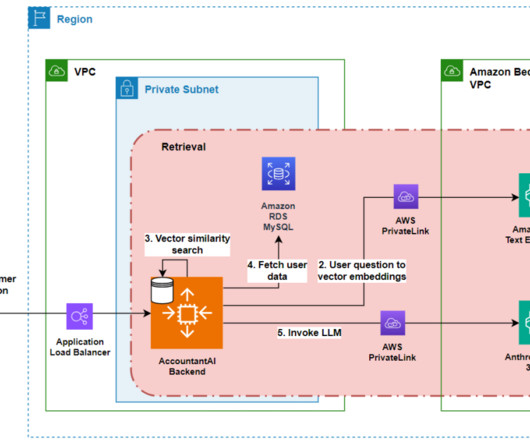
As of September 2024, the AI solution supports three core applications: Clearwater Intelligent Console (CWIC) Clearwaters customer-facing AI application. Crystal shares CWICs core functionalities but benefits from broader data sources and API access. The following image illustrates the solution architecture.
Seamlessly bring your fine-tuned models into a fully managed, serverless environment, and use the Amazon Bedrock standardized API and features like Amazon Bedrock Agents and Amazon Bedrock Knowledge Bases to accelerate generative AI application development.
Sonnet currently ranks at the top of S&P AI Benchmarks by Kensho , which assesses large language models (LLMs) for finance and business. For example, there could be leakage of benchmark datasets’ questions and answers into training data. Anthropic Claude 3.5 Kensho is the AI Innovation Hub for S&P Global. Anthropic Claude 3.5
In terms of resulting speedups, the approximate order is programming hardware, then programming against PBA APIs, then programming in an unmanaged language such as C++, then a managed language such as Python. In March 2024, AWS announced it will offer the new NVIDIA Blackwell platform, featuring the new GB200 Grace Blackwell chip.
At re:Invent 2024, we are excited to announce new capabilities to speed up your AI inference workloads with NVIDIA accelerated computing and software offerings on Amazon SageMaker. This integration provides a powerful multilingual model that excels in reasoning benchmarks.
The ingestion workflow transforms these curated questions into vector embeddings using Amazon Titan Text Embeddings model API. Specific accounting knowledge that is relevant to the question and the model is not familiar with, such as updated data for 2024. The vector embeddings are persisted in the application in-memory vector store.
This was accomplished by using foundation models (FMs) to transform natural language into structured queries that are compatible with our products GraphQL API. 2024-10-{01/00:00:00--02/00:00:00}. For example, what if the model generates a filter with a key not supported by our API? Translate it to a GraphQL API request.
This feature empowers customers to import and use their customized models alongside existing foundation models (FMs) through a single, unified API. Having a unified developer experience when accessing custom models or base models through Amazon Bedrock’s API. Ease of deployment through a fully managed, serverless, service. 2, 3, 3.1,
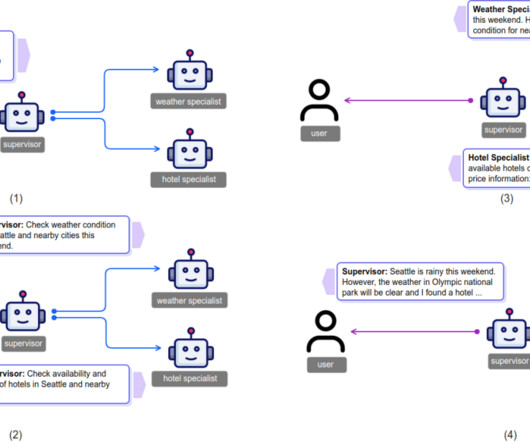
For example, in the case of travel planning, the agent would need to maintain a high-level plan for checking weather forecasts, searching for hotel rooms and attractions, while simultaneously reasoning about the correct usage of a set of hotel-searching APIs. We refer to this approach as assertion-based benchmarking.
Optimize DeepSeek-R1 prompts To get started with prompt optimization, select DeepSeek-R1 on the model playground on Amazon Bedrock, enter your prompt, and choose the magic wand icon, or use the Amazon Bedrock optimize_prompt() API. GPT 4o, and OpenAI O1 (more details in this paper ).
This post and the subsequent code implementation were inspired by one of the International Conference on Machine Learning (ICML) 2024 best papers on LLM debates Debating with More Persuasive LLMs Leads to More Truthful Answers. It uses a different dataset, TofuEval. Details on the exact dataset can be found in the GitHub repository.
Today at AWS re:Invent 2024, we are excited to announce the new Container Caching capability in Amazon SageMaker, which significantly reduces the time required to scale generative AI models for inference. To run this benchmark, we use sub-minute metrics to detect the need for scaling. The following table summarizes our setup.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

































Let's personalize your content