This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
OpenAI launched GPT-4o in May 2024, and Amazon introduced Amazon Nova models at AWS re:Invent in December 2024. How do Amazon Nova Micro and Amazon Nova Lite perform against GPT-4o mini in these same metrics? Amazon Bedrock APIs make it straightforward to use Amazon Titan Text Embeddings V2 for embedding data.
Gain insights into training strategies, productivity metrics, and real-world use cases to empower your developers to harness the full potential of this game-changing technology. Discover how to create and manage evaluation jobs, use automatic and human reviews, and analyze critical metrics like accuracy, robustness, and toxicity.
In business for 145 years, Principal is helping approximately 64 million customers (as of Q2, 2024) plan, protect, invest, and retire, while working to support the communities where it does business and build a diverse, inclusive workforce. The platform has delivered strong results across several key metrics.
adds new APIs to customize GraphStorm pipelines: you now only need 12 lines of code to implement a custom node classification training loop. To help you get started with the new API, we have published two Jupyter notebook examples: one for node classification, and one for a link prediction task. Specifically, GraphStorm 0.3
During these live events, F1 IT engineers must triage critical issues across its services, such as network degradation to one of its APIs. This impacts downstream services that consume data from the API, including products such as F1 TV, which offer live and on-demand coverage of every race as well as real-time telemetry.
Additionally, the complexity increases due to the presence of synonyms for columns and internal metrics available. I am creating a new metric and need the sales data. Firstly, LLMs dont have access to enterprise databases, and the models need to be customized to understand the specific database of an enterprise.
During re:Invent 2024, we launched latency-optimized inference for foundation models (FMs) in Amazon Bedrock. To effectively optimize AI applications for responsiveness, we need to understand the key metrics that define latency and how they impact user experience. These metrics are shown in the following diagram.
The 2501 version follows previous iterations (Mistral-Small-2409 and Mistral-Small-2402) released in 2024, incorporating improvements in instruction-following and reliability. At the time of writing this post, you can use the InvokeModel API to invoke the model. It doesnt support Converse APIs or other Amazon Bedrock tooling.
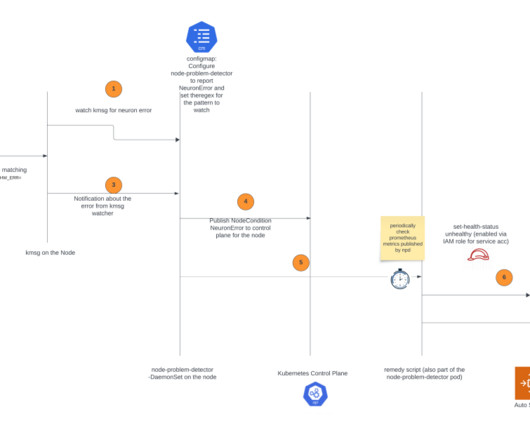
If it detects error messages specifically related to the Neuron device (which is the Trainium or AWS Inferentia chip), it will change NodeCondition to NeuronHasError on the Kubernetes API server. The node recovery agent is a separate component that periodically checks the Prometheus metrics exposed by the node problem detector.
SageMaker Model Monitor emits per-feature metrics to Amazon CloudWatch , which you can use to set up dashboards and alerts. You can use cross-account observability in CloudWatch to search, analyze, and correlate cross-account telemetry data stored in CloudWatch such as metrics, logs, and traces from one centralized account.
In addition, they use the developer-provided instruction to create an orchestration plan and then carry out the plan by invoking company APIs and accessing knowledge bases using Retrieval Augmented Generation (RAG) to provide an answer to the user’s request. user id 111 Today: 09/03/2024 Certainly! Your appointment ID is XXXX.
In 2024, however, organizations are using large language models (LLMs), which require relatively little focus on NLP, shifting research and development from modeling to the infrastructure needed to support LLM workflows. This often means the method of using a third-party LLM API won’t do for security, control, and scale reasons.
FAST has earned a fourth consecutive leader ranking in the 2024 ISG Provider Lens report for its seamless integration with Verisk’s data, analytics, and claims tools. Through some slick prompt engineering and using Claude’s latest capabilities to invoke APIs, Verisk seamlessly accessed their database to procure real-time information.
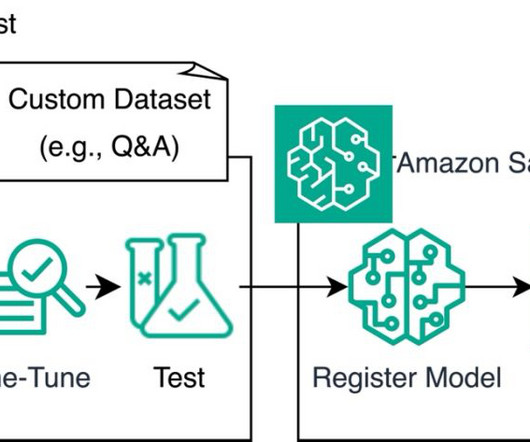
The workflow invokes the Amazon Bedrock CreateModelCustomizationJob API synchronously to fine tune the base model with the training data from the S3 bucket and the passed-in hyperparameters. An AWS Lambda function is called to evaluate the quality of the summarization done by custom model and the base model using the BERTScore metric.
From the period of September 2023 to March 2024, sellers leveraging GenAI Account Summaries saw a 4.9% This involves benchmarking new models against our current selections across various metrics, running A/B tests, and gradually incorporating high-performing models into our production pipeline. The impact goes beyond just efficiency.
As new embedding models are released with incremental quality improvements, organizations must weigh the potential benefits against the associated costs of upgrading, considering factors like computational resources, data reprocessing, integration efforts, and projected performance gains impacting business metrics.
Here’s the good news: in 2024, we have a wide array of capable call center quality assurance software solutions that can streamline QA processes, automate manual tasks, and deliver insightful reports to support decision-making. The post Top 5 Call Center Quality Assurance Software for 2024 appeared first on Balto.
SageMaker has seamless logging, monitoring, and auditing enabled for deployed models with native integrations with services like AWS CloudTrail for logging and monitoring to provide insights into API calls and Amazon CloudWatch to collect metrics, logs, and event data to provide information into the model’s resource utilization.
These applications require the LLMs to have requisite domain knowledge and be able to reason about numeric data to calculate metrics and extract insights. Sonnet is currently ranked number one (as of July 2024), demonstrating Anthropic’s strengths in the business and finance domain. Anthropic Claude 3.5
In early 2024, Amazon launched a major push to harness the power of Twitch for advertisers globally. It evaluates each user query to determine the appropriate course of action, whether refusing to answer off-topic queries, tapping into the LLM, or invoking APIs and data sources such as the vector database.
Figure 1: Examples of generative AI for sustainability use cases across the value chain According to KPMG’s 2024 ESG Organization Survey , investment in ESG capabilities is another top priority for executives as organizations face increasing regulatory pressure to disclose information about ESG impacts, risks, and opportunities.
Also learn how prompts can be integrated with your architecture and how to use API parameters for tuning the model parameters using Amazon Bedrock. See demos on how to build analytics dashboards and integrations between LLMs and Amazon QuickSight to visualize your key metrics. Reserve your seat now! Reserve your seat now!
In January 2024, Amazon SageMaker launched a new version (0.26.0) You can enable your desired strategy ( shard-over-heads , for example) with the following code: option.group_query_attention=shard-over-heads Additionally, the new implementation of NeuronX DLC introduces a cache API for TransformerNeuronX that enables access to the KV cache.
Users from several business units were trained and onboarded to the platform, and that number is expected to grow in 2024. Another important metric is the efficiency for data science users. The following outcomes were achieved: User adoption is one of the key leading indicators for Philips.
from 2024, fueled by several trends, including the use of smartphones. Enhanced self-management: the patient mobile app can help patients track their symptoms, adherence to treatment, and other health metrics. Health data tracking: integrate with wearables and devices to track vital signs, medications, and other health metrics.
In terms of resulting speedups, the approximate order is programming hardware, then programming against PBA APIs, then programming in an unmanaged language such as C++, then a managed language such as Python. In March 2024, AWS announced it will offer the new NVIDIA Blackwell platform, featuring the new GB200 Grace Blackwell chip.
With SageMaker JumpStart, you can evaluate, compare, and select foundation models (FMs) quickly based on predefined quality and responsibility metrics to perform tasks such as article summarization and image generation. Crystal shares CWICs core functionalities but benefits from broader data sources and API access.
As per recent stats the number of remote call center agents is expected to grow by 60 percent from 2022 to 2024. Consider APIs and third-party integrations available to extend functionality as needed. It just takes one natural disaster or pandemic to stop the entire call center operations for quite some time.
Chatbots will drive $142 billion in consumer spending by 2024 — a meteoric surge from $2.8 Live chat could nudge them to decide based on a current performance metric that might be relevant to their needs. You can even build custom automated support solutions with an API. billion in 2019. Source: JivoChat.
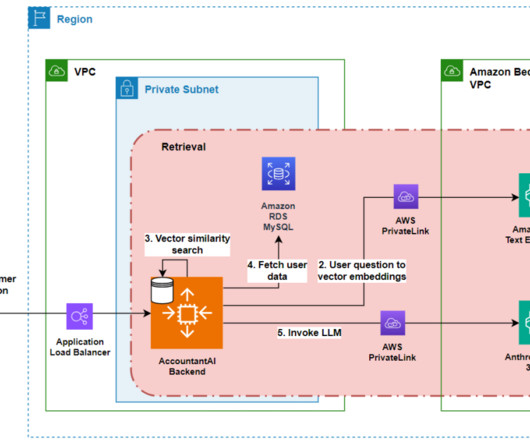
Guardrail objectives At the core of the architecture is Amazon Bedrock serving foundation models (FMs) with an API interface; the FM powers the conversational capabilities of the virtual agent. Designing a personalized CloudWatch dashboard involves the use of metric filters to extract targeted insights from logs. Virginia) AWS Region.
Today at AWS re:Invent 2024, we are excited to announce a new feature for Amazon SageMaker inference endpoints: the ability to scale SageMaker inference endpoints to zero instances. These sub-minute metrics can help trigger scale-out actions more precisely, reducing the number of NoCapacityInvocationFailures your users might experience.
At re:Invent 2024, we are excited to announce new capabilities to speed up your AI inference workloads with NVIDIA accelerated computing and software offerings on Amazon SageMaker. This post is co-written with Abhishek Sawarkar, Eliuth Triana, Jiahong Liu and Kshitiz Gupta from NVIDIA.
Amazon EKS creates a highly available endpoint for the managed Kubernetes API server that you use to communicate with your cluster (using tools like kubectl). The managed endpoint uses Network Load Balancer to load balance Kubernetes API servers. This VPC doesn’t appear in the customer account. Replace the Instance.
Validation loss and validation perplexity – Similar to the training metrics, but measured during the validation stage. On an order of magnitude, the two models performed about the same along these metrics on the provided data. Training perplexity – Measures the model’s surprise when encountering text during training.
The ingestion workflow transforms these curated questions into vector embeddings using Amazon Titan Text Embeddings model API. Specific accounting knowledge that is relevant to the question and the model is not familiar with, such as updated data for 2024. The vector embeddings are persisted in the application in-memory vector store.
Users initiate the process by calling the SageMaker control plane through APIs or command line interface (CLI) or using the SageMaker SDK for each individual step. Create a Weights & Biases API key to access the Weights & Biases dashboard for logging and monitoring Request a SageMaker service quota for 1x ml.p4d.24xlarge
This feature empowers customers to import and use their customized models alongside existing foundation models (FMs) through a single, unified API. Having a unified developer experience when accessing custom models or base models through Amazon Bedrock’s API. Ease of deployment through a fully managed, serverless, service. 2, 3, 3.1,
In a production environment, you continue to use the existing Amazon Bedrock Inference APIs, such as the InvokeModel or Converse API, and turn on invocation logs that store model input data (prompts) and model output data (responses). The record can optionally include a system prompt that indicates the role assigned to the model.
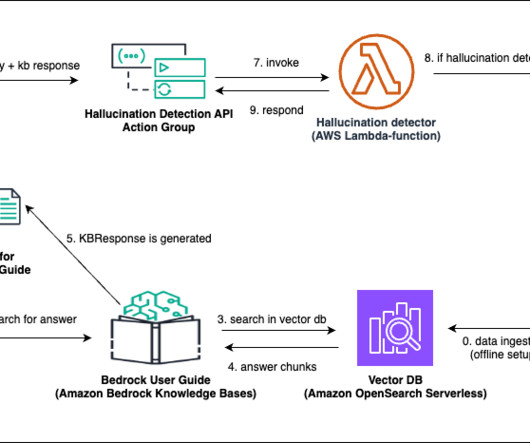
Amazon Bedrock Guardrails offer hallucination detection with contextual grounding checks, which can be seamlessly applied using Amazon Bedrock APIs (such as Converse or InvokeModel ) or embedded into workflows. The custom hallucination detector uses RAGAS metrics, which are generated using a CSV file containing question-answer pairs.
billion in 2024 to $47.1 These tools allow agents to interact with APIs, access databases, execute scripts, analyze data, and even communicate with other external systems. This includes detailed logging of agent interactions, performance metrics, and system health indicators.
However, inference of LLMs as single model invocations or API calls doesnt scale well with many applications in production. Additionally, the framework includes evaluation metrics that can be extended to accommodate changes in accuracy requirements. This API returns a response containing jobArn.
When we launched LLM-as-a-judge (LLMaJ) and Retrieval Augmented Generation (RAG) evaluation capabilities in public preview at AWS re:Invent 2024 , customers used them to assess their foundation models (FMs) and generative AI applications, but asked for more flexibility beyond Amazon Bedrock models and knowledge bases.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies such as AI21 Labs, Anthropic, Cohere, Meta, Mistral, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
Implementation details We spin up the cluster by calling the SageMaker control plane through APIs or the AWS Command Line Interface (AWS CLI) or using the SageMaker AWS SDK. Optional) Create a Weights & Biases API key to access the Weights & Biases dashboard for logging and monitoring. on Hugging Face.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content