This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Using its enterprise software, FloTorch conducted an extensive comparison between Amazon Nova models and OpenAIs GPT-4o models with the Comprehensive Retrieval Augmented Generation (CRAG) benchmark dataset. OpenAI launched GPT-4o in May 2024, and Amazon introduced Amazon Nova models at AWS re:Invent in December 2024.
According to Forresters Consumer Benchmark Survey, 2024, 54% of US online adults agree that loyalty programs influence what they buy, and 64% agree that programs influence where they make purchases. Are Your CX Metrics Hurting Your Customer Experience? There are ongoing discussions about which CX metric is the best.
According to New Relic’s 2024 Observability Forecast , businesses face a median annual downtime of 77 hours from high-impact outages. It examines service performance metrics, forecasts of key indicators like error rates, error patterns and anomalies, security alerts, and overall system status and health. million per hour.
Gain insights into training strategies, productivity metrics, and real-world use cases to empower your developers to harness the full potential of this game-changing technology. Discover how to create and manage evaluation jobs, use automatic and human reviews, and analyze critical metrics like accuracy, robustness, and toxicity.
Sonnet currently ranks at the top of S&P AI Benchmarks by Kensho , which assesses large language models (LLMs) for finance and business. For example, there could be leakage of benchmark datasets’ questions and answers into training data. Anthropic Claude 3.5 Kensho is the AI Innovation Hub for S&P Global. Anthropic Claude 3.5
During re:Invent 2024, we launched latency-optimized inference for foundation models (FMs) in Amazon Bedrock. To effectively optimize AI applications for responsiveness, we need to understand the key metrics that define latency and how they impact user experience. These metrics are shown in the following diagram.
This post describes how to get started with the software development agent, gives an overview of how the agent works, and discusses its performance on public benchmarks. This is an overview of the system as of May 2024. A single metric never tells the whole story. The success metric for SWE-bench is binary.
Continuous education involves more than glancing at release announcements it includes testing beta features, benchmarking real world results, and actively sharing insights. A 2024 survey identified Spring Boot as the most adopted Java framework at 62%, with Quarkus at 15% and Micronaut at 10%.
That way, both teams can use those outcomes as a benchmark of success throughout the customer journey. Strategy #3: Share revenue responsibility and success metrics There’s been a major shift in the B2B space over the past few years. This doesn’t just provide a useful shared goal.
As new embedding models are released with incremental quality improvements, organizations must weigh the potential benefits against the associated costs of upgrading, considering factors like computational resources, data reprocessing, integration efforts, and projected performance gains impacting business metrics.
The 2024 B2B SaaS Benchmarking Survey by SaaS Capital is the most comprehensive and up-to-date source of its kind for SaaS and customer success leaders who want to know where they stand compared to peers and competitors. To find out more about the survey, and see more research and benchmarking data, visit SaaS Capital here.
We also released a comprehensive study of co-training language models (LM) and graph neural networks (GNN) for large graphs with rich text features using the Microsoft Academic Graph (MAG) dataset from our KDD 2024 paper. To address this, with GraphStorm 0.3, Dataset Num. of nodes Num. of edges Num. of node/edge types Num.
The 2501 version follows previous iterations (Mistral-Small-2409 and Mistral-Small-2402) released in 2024, incorporating improvements in instruction-following and reliability.
This repository is a modified version of the original How to Fine-Tune LLMs in 2024 on Amazon SageMaker. Within the repository, you can use the medusa_1_train.ipynb notebook to run all the steps in this post. We added simplified Medusa training code, adapted from the original Medusa repository.
Laying the groundwork: Collecting ground truth data The foundation of any successful agent is high-quality ground truth data—the accurate, real-world observations used as reference for benchmarks and evaluating the performance of a model, algorithm, or system. user id 111 Today: 09/03/2024 Certainly! Your appointment ID is XXXX.
Figure 1: Examples of generative AI for sustainability use cases across the value chain According to KPMG’s 2024 ESG Organization Survey , investment in ESG capabilities is another top priority for executives as organizations face increasing regulatory pressure to disclose information about ESG impacts, risks, and opportunities.
In 2024 alone, 11x more AI models were put into production than last year, showing a clear shift from experimentation to real-world application. Real-time insights from sources like sales metrics, customer interactions, and digital analytics help businesses stay competitive by spotting trends early and seizing opportunities.
What is Mixtral 8x22B Mixtral 8x22B is Mistral AI’s latest open-weights model and sets a new standard for performance and efficiency of available foundation models , as measured by Mistral AI across standard industry benchmarks. making the model available for exploring, testing, and deploying. Therefore, she sold the car for $18,248.33.
From the period of September 2023 to March 2024, sellers leveraging GenAI Account Summaries saw a 4.9% This involves benchmarking new models against our current selections across various metrics, running A/B tests, and gradually incorporating high-performing models into our production pipeline.
First call resolution is far more than just a metric; it’s a direct reflection of your customer service effectiveness and significantly impacts your business’s bottom line. As you measure, and attempt to optimize, your contact centers first call resolution rate, its crucial to keep benchmarks and industry standards in mind.
In March 2024, AWS announced it will offer the new NVIDIA Blackwell platform, featuring the new GB200 Grace Blackwell chip. Accelerator benchmarking When considering compute services, users benchmark measures such as price-performance, absolute performance, availability, latency, and throughput.
In 2024 alone, hospitality saw a 20% decrease in already troubling customer retention rates. However, attrition is a metric of past performance. Attrition is the metric that confirms one or all of these scenarios occurred. And they continue to struggle to stem the tide. There are many reasons for this. This is important to note.
You can use industry benchmarks to estimate your staffing needs. For instance, if you receive 1,000 calls per day, you’d need to consider factors such as average handle time, first call resolution, and customer satisfaction metrics to determine the appropriate number of agents. A data breach can cost you more than just money.
From lead conversion rates (CVR), click-through rates (CTR), and Net Promoter Scores (NPS), companies use multiple metrics to analyze the effectiveness of their CX strategy. Is your CX strategy up to the task of meeting customers’ expectations going into 2024? One CX software that works well for most companies is Lumoa.
Financial services cybersecurity regulations are constantly evolving, with new requirements expected for 2024 and beyond. Measure Quality and Performance Quality assurance and performance metrics form the backbone of effective call center operations. These metrics should align with your business objectives and industry standards.
More than 80% of business leaders see customer experience as a growing priority in 2024. Despite efforts to collect and analyze feedback, employees frequently struggle to pinpoint what affects these metrics. 78% of customers have backed out of a purchase due to a poor customer experience (CX).
In January 2024, Amazon SageMaker launched a new version (0.26.0) In this post, we explore the latest features introduced in this release, examine performance benchmarks, and provide a detailed guide on deploying new LLMs with LMI DLCs at high performance. of Large Model Inference (LMI) Deep Learning Containers (DLCs).
Gartner also predicted that by 2024, this emotional effort will be the top reason customer service reps leave the service center. Agents who aren’t meeting your KPI benchmarks for how many interactions they handle in a shift might be avoiding interactions or too distracted by emotional overwhelm.
Enable a data science team to manage a family of classic ML models for benchmarking statistics across multiple medical units. Users from several business units were trained and onboarded to the platform, and that number is expected to grow in 2024. Another important metric is the efficiency for data science users.
With SageMaker JumpStart, you can evaluate, compare, and select foundation models (FMs) quickly based on predefined quality and responsibility metrics to perform tasks such as article summarization and image generation. RAG benchmark Compare the fine-tuned models performance against a RAG system using a pre-trained model.
At re:Invent 2024, we are excited to announce new capabilities to speed up your AI inference workloads with NVIDIA accelerated computing and software offerings on Amazon SageMaker. This integration provides a powerful multilingual model that excels in reasoning benchmarks.
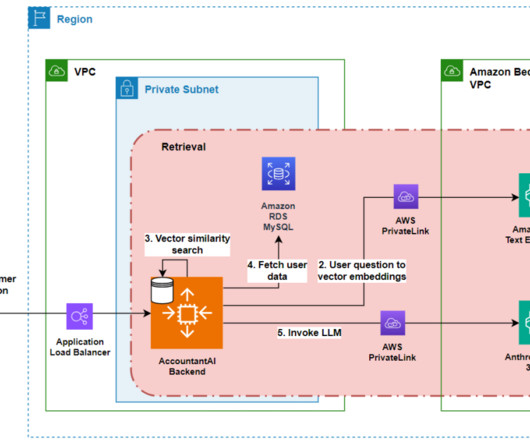
Specific accounting knowledge that is relevant to the question and the model is not familiar with, such as updated data for 2024. Lili selected Anthropic’s Claude model family for AccountantAI after reviewing industry benchmarks and conducting their own quality assessment. Data relevant to answering the customer's question.
models demonstrate state-of-the-art performance on a wide range of industry benchmarks and introduce features to help you build a new generation of AI experiences. These new models provide enhanced capabilities and broader applicability across various use cases. With a focus on responsible innovation and system-level safety, the Llama 3.2
These approaches train a single deep learning model across multiple time series in a dataset—for example, sales across a broad e-commerce catalog or observability metrics for thousands of customers. Transactions on Machine Learning Research (2024). [2] In NeurIPS Track on Datasets and Benchmarks (2021). 2] Hyndman, R.
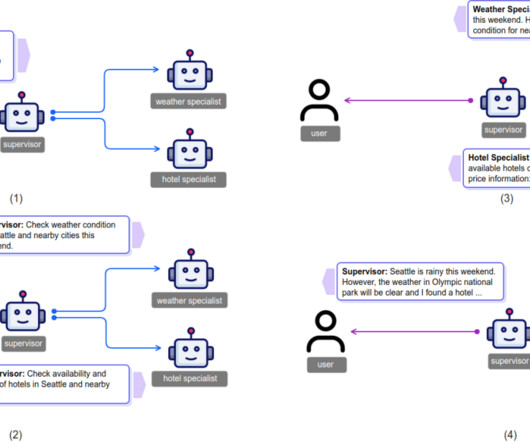
We refer to this approach as assertion-based benchmarking. Here is an example of a scenario and corresponding assertions for assertion-based benchmarking: Goals : User needs the weather conditions expected in Las Vegas for tomorrow, January 5, 2025. Since 2024, Raphael worked on multi-agent collaboration with LLM-based agents.
Running deterministic evaluation of generative AI assistants against use case ground truth data enables the creation of custom benchmarks. These benchmarks are essential for tracking performance drift over time and for statistically comparing multiple assistants in accomplishing the same task. See for examples.
This post and the subsequent code implementation were inspired by one of the International Conference on Machine Learning (ICML) 2024 best papers on LLM debates Debating with More Persuasive LLMs Leads to More Truthful Answers. Refer to the evaluation metrics section for accuracy definition) This continues for N(=3 in this notebook) rounds.
Today at AWS re:Invent 2024, we are excited to announce the new Container Caching capability in Amazon SageMaker, which significantly reduces the time required to scale generative AI models for inference. To run this benchmark, we use sub-minute metrics to detect the need for scaling. The following table summarizes our setup.
Today at AWS re:Invent 2024, we are excited to announce a new capability in Amazon SageMaker Inference that significantly reduces the time required to deploy and scale LLMs for inference using LMI: Fast Model Loader. To run this benchmark, we use sub-minute metrics to detect the need for scaling. For the LLaMa 3.1
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content