This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Using its enterprise software, FloTorch conducted an extensive comparison between Amazon Nova models and OpenAIs GPT-4o models with the Comprehensive Retrieval Augmented Generation (CRAG) benchmark dataset. FloTorch used these queries and their ground truth answers to create a subset benchmark dataset.
With the advancement of the contact center industry, benchmarks continue to shift and challenge businesses to meet higher customer expectations while maintaining efficiency. In 2025, achieving the right benchmarks means understanding the metrics that matter, tracking them effectively, and striving for continuous improvement.
Overview of Pixtral 12B Pixtral 12B, Mistrals inaugural VLM, delivers robust performance across a range of benchmarks, surpassing other open models and rivaling larger counterparts, according to Mistrals evaluation. Performance metrics and benchmarks Pixtral 12B is trained to understand both natural images and documents, achieving 52.5%
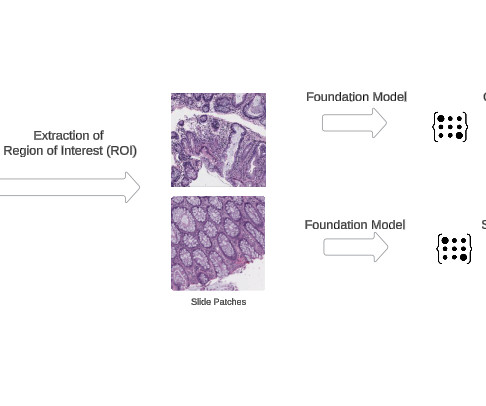
The power of FMs lies in their ability to learn robust and generalizable data embeddings that can be effectively transferred and fine-tuned for a wide variety of downstream tasks, ranging from automated disease detection and tissue characterization to quantitative biomarker analysis and pathological subtyping.
Expert analysis : Data scientists or machine learning engineers analyze the generated reports to derive actionable insights and make informed decisions. Prerequisites To use the LLM-as-a-judge model evaluation, make sure that you have satisfied the following requirements: An active AWS account. 0]}-{evaluator_model.split('.')[0]}-{datetime.now().strftime('%Y-%m-%d-%H-%M-%S')}"
We had Professor Bill Hedgecock, associate professor of marketing Carlson School of Management at the University of Minnesota, as a guest on a recent podcast to talk about facial recognition and facial expression analysis technology and application in Customer Experience programs. So, Is it Creepy?
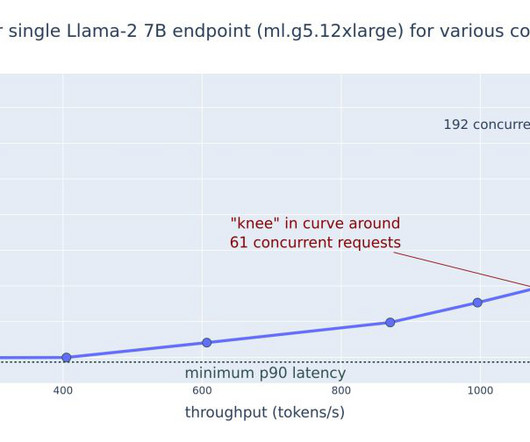
This post explores these relationships via a comprehensive benchmarking of LLMs available in Amazon SageMaker JumpStart, including Llama 2, Falcon, and Mistral variants. We provide theoretical principles on how accelerator specifications impact LLM benchmarking. Additionally, models are fully sharded on the supported instance.
That’s why performing a customer churn analysis can be powerful in the endeavor to increase customer retention. We dive into seven steps for a successful customer churn analysis. . What is a Customer Churn Analysis ? Customer churn analysis is a process by which you find meaning in your customer churn rate.
Oil and gas data analysis – Before beginning operations at a well a well, an oil and gas company will collect and process a diverse range of data to identify potential reservoirs, assess risks, and optimize drilling strategies. Consider a financial data analysis system. We give more details on that aspect later in this post.
Net Promoter Score (NPS) benchmarking presents an interesting challenge for many business leaders. Collectively, we have learned a lot through NPS benchmarking studies. Collectively, we have learned a lot through NPS benchmarking studies. So, why is it such a difficult business decision to obtain NPS benchmark intelligence?
A customer journey analysis helps you improve SaaS client experience and increase retention by optimizing the steps customers take in their relationship with your product and brand. A customer journey analysis identifies what needs to happen at each step in the process in order to deliver satisfaction and avoid dissatisfaction.
As proponents of a low-effort approach to CX , we’ve implemented our own benchmarking metrics for customer effort. And those metrics are exactly what CX leaders need to be tracking in order to start benchmarking customer experience. Tethr’s benchmarking feature shows you where you stand. #2 How’s that for accountability? #3
In this sense, CES can almost act as a gauge of how well a company is doing against its benchmarks and those of competitors. While interactions between clients and staff are qualitative, rating scales allow for quantitative analysis. For SaaS products, consider questions like: “How easy was it to set up your account?”
Accountability. Their suite of products and services allow you to truly understand your customer experience through detailed performance analysis and competitor benchmarking, all underpinned by tangible recommendations from real CX experts and the latest in AI and machine learning capabilities.
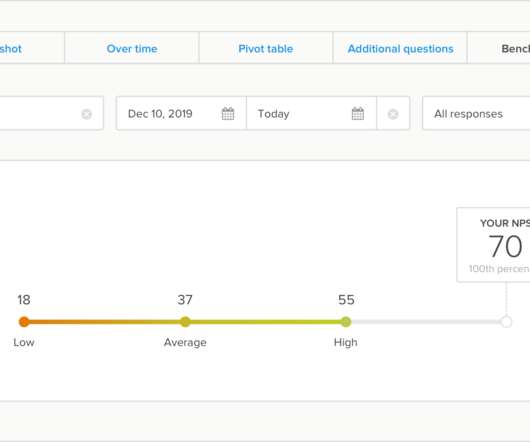
Find out how your real-time NPS compares to competitors in 20 industries with Benchmarks, our newest in-platform report. Prior to this release, our reporting features were all geared towards easy customer experience performance monitoring and feedback analysis for your Delighted survey results. How the Benchmarks report works.
Through automation, you can scale in-demand skillsets, such as model and data analysis, introducing and enforcing in-depth analysis of your models at scale across diverse product teams. This allows you to introduce analysis of arbitrary complexity while not being limited by the busy schedules of highly technical individuals.
A common way to select an embedding model (or any model) is to look at public benchmarks; an accepted benchmark for measuring embedding quality is the MTEB leaderboard. The Massive Text Embedding Benchmark (MTEB) evaluates text embedding models across a wide range of tasks and datasets.
First, we had to experiment and benchmark in order to determine that Graviton3 was indeed the right solution for us. First, we started by benchmarking our workloads using the readily available Graviton Deep Learning Containers (DLCs) in a standalone environment. Technical Account Manager at AWS with 15 years of experience.
FCR on social/text needs to be amended to first conversation resolution as customers rarely provide all info needed to resolve a query upfront, but measuring this provides a benchmark you can use against other channels. Smitha obtained her license as CPA in 2007 from the California Board of Accountancy. Reuben Kats @grab_results.
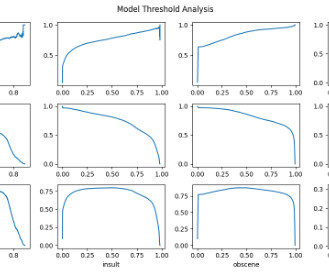
We go through several steps, including data preparation, model creation, model performance metric analysis, and optimizing inference based on our analysis. Prepare the data For this analysis, we use the Toxic Comment Classification dataset from Kaggle. For Analysis type , choose Custom classification. Choose Create job.
Accountability. Their suite of products and services allow you to truly understand your customer experience through detailed performance analysis and competitor benchmarking, all underpinned by tangible recommendations from real CX experts and the latest in AI and machine learning capabilities.
Now it’s time to put that data to use with some customer feedback analysis. In this post, we’ll walk through all the basics of customer feedback analysis, from prepping your customer data to using survey analytics tools to simplify the process. Survey results analysis and reporting. Analyzing customer feedback.
These include metrics such as ROUGE or cosine similarity for text similarity, and specific benchmarks for assessing toxicity (Detoxify), prompt stereotyping (cross-entropy loss), or factual knowledge (HELM, LAMA). If the use case doesnt yield discrete outputs, task-specific metrics are more appropriate.
In this article, we cover: Budgeting Benchmarks: Do They Cause More Harm than Good? How to Perform a Top-Down Analysis for Customer-to-CSM Ratio. How to Perform a Bottom-Up Analysis for Customer-to-CSM Ratio. Budgeting Benchmarks: Do They Cause More Harm than Good? Calculating Regular Journey Touchpoints. Not exactly.
Prerequisites To run the example notebooks, you need an AWS account with an AWS Identity and Access Management (IAM) role with permissions to manage resources created. For details, refer to Create an AWS account. DeepSeek-R1-Distill-Llama-8B DeepSeek-R1-Distill-Llama-8B was benchmarked across ml.g5.2xlarge , ml.g5.12xlarge , ml.g6e.2xlarge
The current benchmark is set for 96% customer satisfaction, but they regularly surpass this number. Until then, all we can do is post interesting, useful, and fun content to our blog and social media accounts. Aircall is committed to superior customer experience. Direct display of all CRM integrations. Media: 8/20. Security: 15/20.
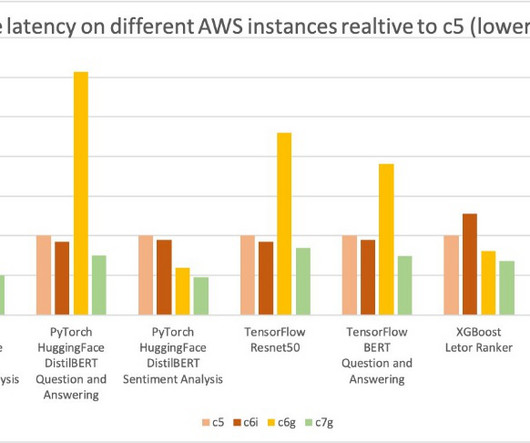
We cover computer vision (CV), natural language processing (NLP), classification, and ranking scenarios for models and ml.c6g, ml.c7g, ml.c5, and ml.c6i SageMaker instances for benchmarking. You can use the sample notebook to run the benchmarks and reproduce the results. For more details, refer to the GitHub repo. He received his Ph.D.
This installment’s myth is brought to you by ChurnZero Customer Success Manager (CSM) Allison Mortens and covers the widely held but false belief that there’s a universal standard for the number of accounts or amount of annual recurring revenue (ARR) that each CSM can manage. After reading that sentence, I bet a figure popped into your head.
It was built for organizations with the resources to manage layered feedback systems, not for lean teams that need quick, actionable customer feedback analysis. Were a full-service survey company handling everything you need including survey design, deployment, analysis, reporting, and more.
We benchmark ourselves against standards such as body mass index to determine where we should ideally be. If this approach - theoretically - works when dieting, why not use benchmarking with customers? We are talking about benchmarks on how they are currently doing and where they should ideally be.
A recent AVANT “6-12” report focusing on CCaaS notes that the CCaaS market currently accounts for more than $3 billion in global sales. These reduce downtime, and expedite carrier root cause analysis. One survey notes that responding CIOs indicate their use of on-premise applications dropped by more than 40% in 2021.
That’s why performing a customer churn analysis can be powerful in the endeavor to increase customer retention. We dive into seven steps for a successful customer churn analysis. What is a c ustomer churn analysis ? Customer churn analysis is a process by which you find meaning in your customer churn rate.
Often, in place of a proper churn analysis companies operate and make decisions based on opinions, hunches and best guesses. She proposed performing a customer churn analysis to find out why. Her analysis showed the segment of customers that were churning were the smallest and lowest paying accounts.
The power of a benchmark comparison in phone number testing When you receive an alert that your phone number is not functioning, you know immediately that there is a problem. Being able to benchmark your results against other organizations helps point out where issues might be, and provides guidelines to help you fix any hidden issues.
And how can I hold my vendors to account if they aren’t delivering the required service? Informed root-cause analysis For any executive responsible for a global telecoms network, reducing the mean time to restore service (MTRS) or mean time to resolution (MTTR) is a key imperative. Are our telco carriers performing as they should be?
Smitha obtained her license as CPA in 2007 from the California Board of Accountancy. With more than 15 years of experience in business, finance and accounting, she is also responsible for implementing financial controls and processes. Set your goals (contact concurrency or resolution time, the percentage of first time resolution, etc.)
This cutting-edge model supports long-context processing, complex segmentation scenarios, and fine-grained analysis, making it ideal for automating processes for various industries such as medical imaging in healthcare, satellite imagery for environment monitoring, and object segmentation for autonomous systems. Meta SAM 2.1 Meta SAM 2.1
Example: A customer upgrades their account from a free to a paid plan. And when calculating your score, dont forget to segment your customers so you can perform cross-tab analysis. With us, you get enterprise-level data analysis without the hassle or expense of managing software yourself. Thats why we go deeper.
Intelligent routing tools go beyond simple call distribution, leveraging sophisticated algorithms and data analysis to connect customers with the most appropriate agent or resource. These tools consider factors like customer history, agent skills, real-time availability, and even sentiment analysis to ensure optimal matching.
Key performance indicators play a crucial role in assessing current value and setting future goals and benchmarks. An analysis of obstacles impeding performance and solutions. Still, your KPI monitoring indicates that their account activity has dropped significantly below this level.
Our field organization includes customer-facing teams (account managers, solutions architects, specialists) and internal support functions (sales operations). Personalized content will be generated at every step, and collaboration within account teams will be seamless with a complete, up-to-date view of the customer.
Automate Price Calculations and Adjustments Utilize real-time pricing engines within CPQ to dynamically calculate prices based on market trends, cost fluctuations, and competitor benchmarks. Ensure pricing logic accounts for regional tax structures, regulatory compliance, and multi-currency support for global operations.
These examples include speeding up market trend analysis, ensuring accurate risk management and compliance, and facilitating data collection or report generation. You can use resources such as the Amazon Sustainability Data Initiative or the AWS Data Exchange to simplify and expedite the acquisition and analysis of comprehensive datasets.
The inference pipeline is powered by an AWS Lambda -based multi-step architecture, which maximizes cost-efficiency and elasticity by running independent image analysis steps in parallel. The buffer was implemented after benchmarking the captioning model’s performance. She loves traveling and spending time with her family.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content