This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
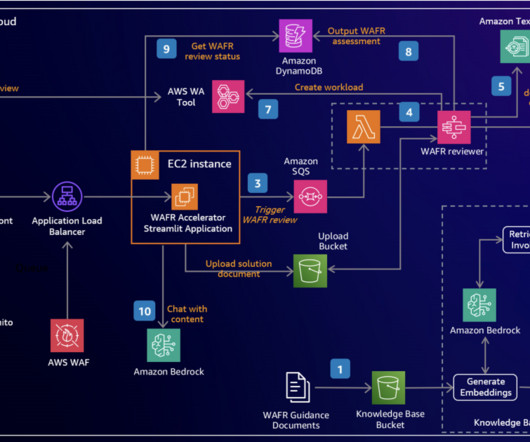
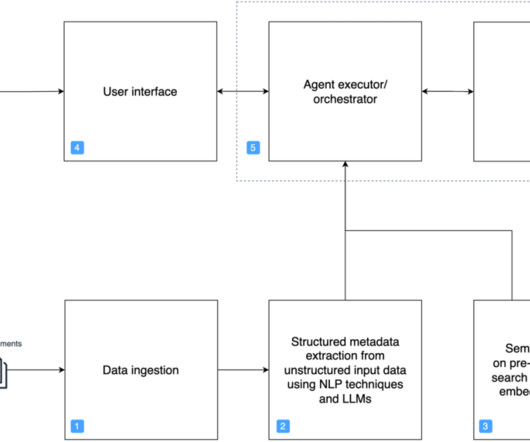
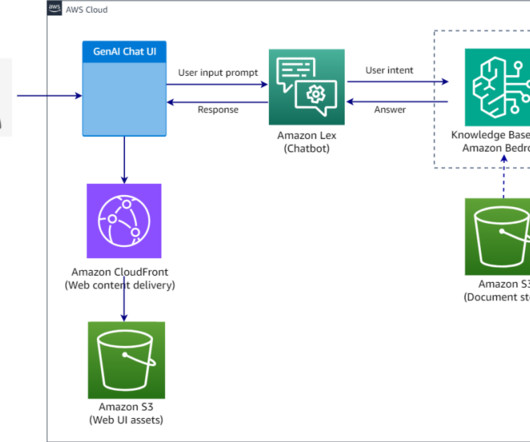
We demonstrate how to harness the power of LLMs to build an intelligent, scalable system that analyzes architecture documents and generates insightful recommendations based on AWS Well-Architected best practices. An interactive chat interface allows deeper exploration of both the original document and generated content.
Security – The solution uses AWS services and adheres to AWS Cloud Security best practices so your data remains within your AWS account. For a detailed breakdown of the features and implementation specifics, refer to the comprehensive documentation in the GitHub repository.
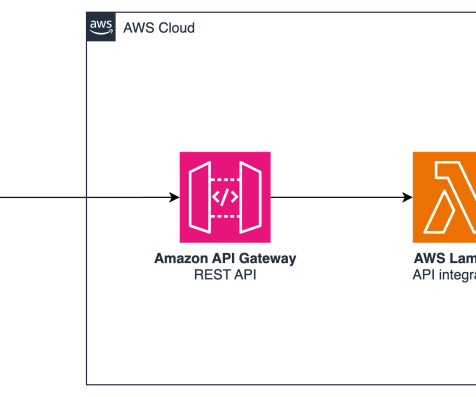
operation.font.set({ name: 'Arial' }); // flush changes to the Word document await context.sync(); }); Generative AI backend infrastructure The AWS Cloud backend consists of three components: Amazon API Gateway acts as an entry point, receiving requests from the Office applications Add-in. Here, we use Anthropics Claude 3.5 Sonnet).
In Part 1 of this series, we discussed intelligent document processing (IDP), and how IDP can accelerate claims processing use cases in the insurance industry. We discussed how we can use AWS AI services to accurately categorize claims documents along with supporting documents. Part 1: Classification and extraction of documents.
Organizations in the lending and mortgage industry process thousands of documents on a daily basis. From a new mortgage application to mortgage refinance, these business processes involve hundreds of documents per application. At the start of the process, documents are uploaded to an Amazon Simple Storage Service (Amazon S3) bucket.
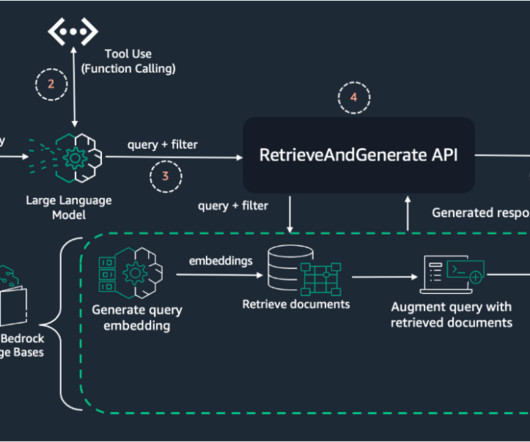
By narrowing down the search space to the most relevant documents or chunks, metadata filtering reduces noise and irrelevant information, enabling the LLM to focus on the most relevant content. This approach narrows down the search space to the most relevant documents or passages, reducing noise and irrelevant information.
Question and answering (Q&A) using documents is a commonly used application in various use cases like customer support chatbots, legal research assistants, and healthcare advisors. In this collaboration, the AWS GenAIIC team created a RAG-based solution for Deltek to enable Q&A on single and multiple government solicitation documents.
Such data often lacks the specialized knowledge contained in internal documents available in modern businesses, which is typically needed to get accurate answers in domains such as pharmaceutical research, financial investigation, and customer support. This task involves answering analytical reasoning questions.
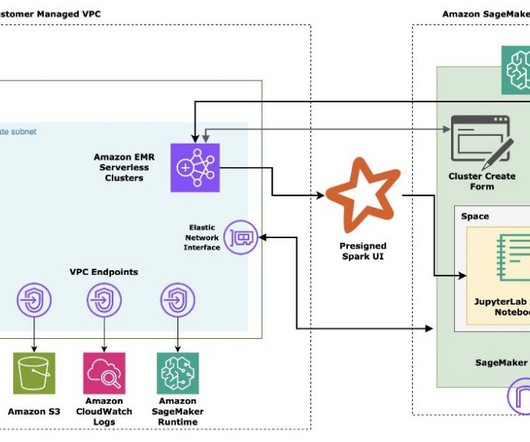
By using the Livy REST APIs , SageMaker Studio users can also extend their interactive analytics workflows beyond just notebook-based scenarios, enabling a more comprehensive and streamlined data science experience within the Amazon SageMaker ecosystem.
Lets say the task at hand is to predict the root cause categories (Customer Education, Feature Request, Software Defect, Documentation Improvement, Security Awareness, and Billing Inquiry) for customer support cases. We suggest consulting LLM prompt engineering documentation such as Anthropic prompt engineering for experiments.
Site monitors conduct on-site visits, interview personnel, and verify documentation to assess adherence to protocols and regulatory requirements. However, this process can be time-consuming and prone to errors, particularly when dealing with extensive audio recordings and voluminous documentation.
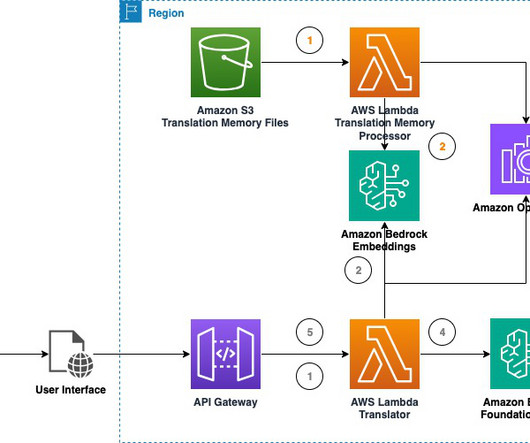
The solution offers two TM retrieval modes for users to choose from: vector and document search. When using the Amazon OpenSearch Service adapter (document search), translation unit groupings are parsed and stored into an index dedicated to the uploaded file. For this post, we use a document store. Choose With Document Store.
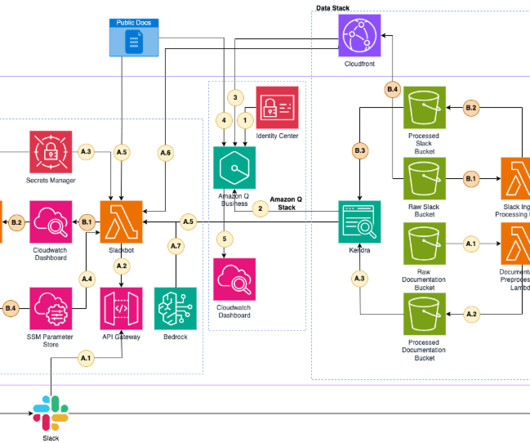
This post shows how to configure an Amazon Q Business custom connector and derive insights by creating a generative AI-powered conversation experience on AWS using Amazon Q Business while using access control lists (ACLs) to restrict access to documents based on user permissions. Who are the data stewards for my proprietary database sources?
The agent knowledge base stores Amazon Bedrock service documentation, while the cache knowledge base contains curated and verified question-answer pairs. For this example, you will ingest Amazon Bedrock documentation in the form of the User Guide PDF into the Amazon Bedrock knowledge base. This will be the primary dataset.
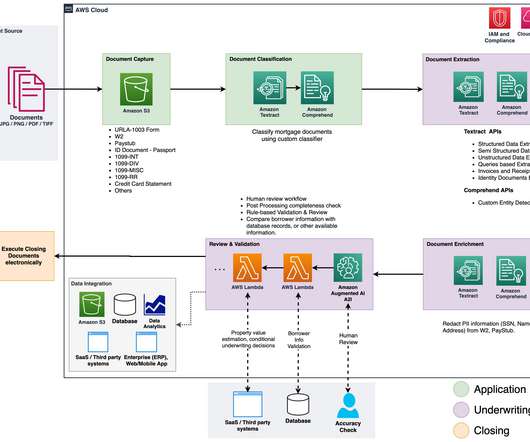
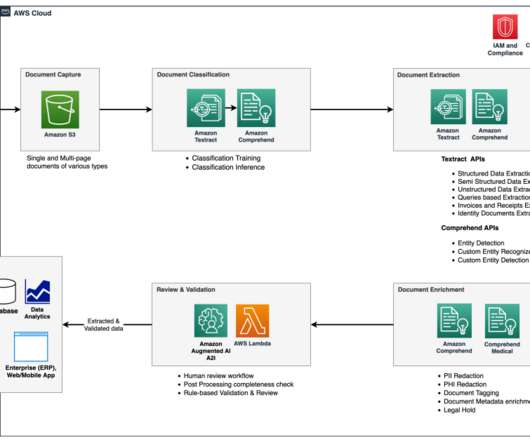
Amazon’s intelligent document processing (IDP) helps you speed up your business decision cycles and reduce costs. Across multiple industries, customers need to process millions of documents per year in the course of their business. The following figure shows the stages that are typically part of an IDP workflow.
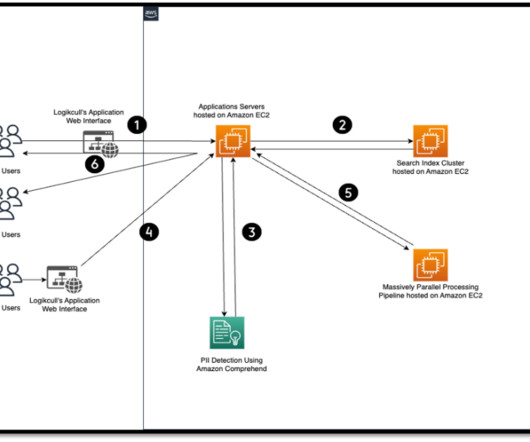
Organizations can search for PII using methods such as keyword searches, pattern matching, data loss prevention tools, machine learning (ML), metadata analysis, data classification software, optical character recognition (OCR), document fingerprinting, and encryption.
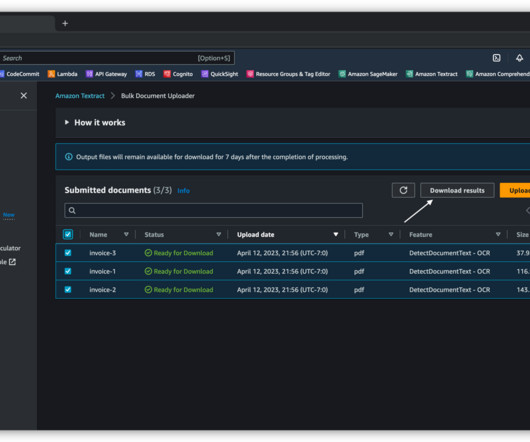
Amazon Textract is a machine learning (ML) service that automatically extracts text, handwriting, and data from any document or image. In this post, we walk through when and how to use the Amazon Textract Bulk Document Uploader to evaluate how Amazon Textract performs on your documents.
The ability to effectively handle and process enormous amounts of documents has become essential for enterprises in the modern world. Due to the continuous influx of information that all enterprises deal with, manually classifying documents is no longer a viable option.
Organizations across industries such as healthcare, finance and lending, legal, retail, and manufacturing often have to deal with a lot of documents in their day-to-day business processes. There is limited automation available today to process and extract information from these documents.
Its a dynamic document that, like your partnership, requires time and attention. It also holds everyone accountable for the role theyre supposed to play. Establish Reporting & Analytics Expectations Reporting and analytics are essential for creating a culture of continual improvement.
By documenting the specific model versions, fine-tuning parameters, and prompt engineering techniques employed, teams can better understand the factors contributing to their AI systems performance. SageMaker is a data, analytics, and AI/ML platform, which we will use in conjunction with FMEval to streamline the evaluation process.
Link your WhatsApp Business account to your organization’s professional phone number for added credibility. A WhatsApp Shared Inbox for Teams allows multiple support agents to respond to customer messages from the same WhatsApp account. Attach PDFs such as invoices, receipts, or warranty documentation directly in the chat.
Numerous disparate systems generate perpetual flows of valuable data — the analytic raw material that can yield truth and intelligence about your people, performance, processes, culture and more. Once in place, establish a data management and analytics assessment program to identify data challenges and coordinate and prioritize projects.
SageMaker JumpStart is a machine learning (ML) hub that provides a wide range of publicly available and proprietary FMs from providers such as AI21 Labs, Cohere, Hugging Face, Meta, and Stability AI, which you can deploy to SageMaker endpoints in your own AWS account. This logic sits in a hybrid search component.
“Intelligent document processing (IDP) solutions extract data to support automation of high-volume, repetitive document processing tasks and for analysis and insight. Customers spend a significant amount of time and effort identifying documents and extracting critical information from them for various use cases.
Data sources We use Spack documentation RST (ReStructured Text) files uploaded in an Amazon Simple Storage Service (Amazon S3) bucket. Whenever the assistant returns it as a source, it will be a link in the specific portion of the Spack documentation and not the top of a source page. Click here to open the AWS console and follow along.
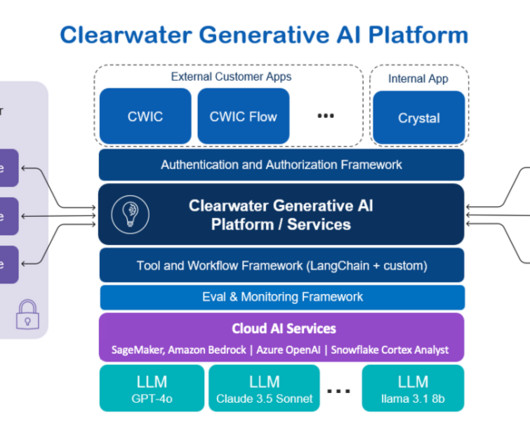
This post was written with Darrel Cherry, Dan Siddall, and Rany ElHousieny of Clearwater Analytics. About Clearwater Analytics Clearwater Analytics (NYSE: CWAN) stands at the forefront of investment management technology. trillion in assets across thousands of accounts worldwide.
If an employee is being dismissed due to performance concerns, you should keep all documentation on file such as data from quality assurance software solutions or performance monitoring reports, as well as any documentation from agent coaching sessions. Information about the notice period.
By Diana Aviles The core part of Speech Analytics that sometimes gets lost amongst the high powered metadata and reporting functionalities are the audio insights themselves. Also, there are complicated grey areas which you will need to account for. There is the fear of looking for too much or too little in a deep dive.
One area that holds significant potential for improvement is accounts payable. On a high level, the accounts payable process includes receiving and scanning invoices, extraction of the relevant data from scanned invoices, validation, approval, and archival. Now let’s dive into each of the document processing steps.
Data-Driven Approach: Leverage the power of data analytics to identify trends and patterns in quality issues. This fosters a sense of shared ownership and accountability. Documented Procedures: Document all service level agreements (SLAs) and operating procedures clearly and concisely.
If you’re implementing complex RAG applications into your daily tasks, you may encounter common challenges with your RAG systems such as inaccurate retrieval, increasing size and complexity of documents, and overflow of context, which can significantly impact the quality and reliability of generated answers.
Effective sharing of documents is essential for both businesses and individuals. Improved Accessibility Before planning on how to host a PDF online , it is important to learn that hosting PDF files online makes them readily available to an audience, as users can view these documents from any internet-connected device with ease.
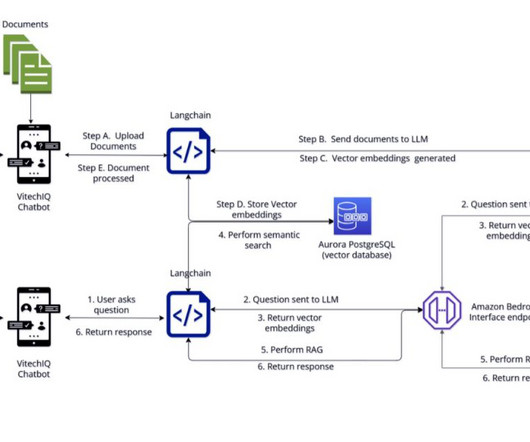
Vitech helps group insurance, pension fund administration, and investment clients expand their offerings and capabilities, streamline their operations, and gain analytical insights. Data store Vitech’s product documentation is largely available in.pdf format, making it the standard format used by VitechIQ.
Prerequisites To create and run this compound AI system in your AWS account, complete the following prerequisites: Create an AWS account if you dont already have one. Prepare question-answer pairs The first step is to prepare question-answer pairs from the CUAD document by running synthetic data generation.
Box, a leading cloud content management platform, serves as a central repository for diverse digital assets and documents in many organizations. An enterprise Box account typically contains a wealth of materials, including documents, presentations, knowledge articles, and more.
For example, students and their parents are provided with financial guidance documents which outline all the financial aids available. Leverage Speech Analytics: Speech analytics software can help you stay CFPB compliant. Once again, speech analytics can be really helpful here. However, there is a better way.
Our customer success experts do the homework on client analytics and provide the bigger picture, bringing deeper knowledge of the industry and how other clients have solved problems. Natural-language interfaces for analytics for easier-to-interpret insights and suggestions. Whenever possible, we meet with clients weekly.
The manual complaint practice causes a lack of key factors like accountability, on-time resolution, monitoring, and documentation – things that can worsen the whole experience for your guests. The biggest problem today is a lack of complaint documentation. Whenever things go wrong, the blame game starts between staff.
You can use the BGE embedding model to retrieve relevant documents and then use the BGE reranker to obtain final results. The application sends the user query to the vector database to find similar documents. The documents returned as a context are captured by the QnA application.
For instance, to improve key call center metrics such as first call resolution , business analysts may recommend implementing speech analytics solutions to improve agent performance management. Successful call centers use analytics to help aid, streamline and maximize customer service and sales needs…”. AmraBeganovich. Kirk Chewning.
Prerequisites To implement this solution, you need the following: An AWS account with privileges to create AWS Identity and Access Management (IAM) roles and policies. Keep the data source location as the same AWS account and choose Browse S3. Select the S3 bucket where you uploaded the Amazon shareholder documents and choose Choose.
It is typically helpful when working with lengthy documents such as entire books. on Amazon Bedrock would be equivalent to roughly 150,000 words or over 500 pages of documents. docker tag :tag your-account-id.dkr.ecr.amazonaws.com/ :tag docker push.dkr.ecr.amazonaws.com/ :tag Copy the values for GenExamImageUri and TakeExamImageUri.
Prerequisites To implement the proposed solution, make sure that you have the following: An AWS account and a working knowledge of FMs, Amazon Bedrock , Amazon SageMaker , Amazon OpenSearch Service , Amazon S3 , and AWS Identity and Access Management (IAM). Display results : Display the top K similar results to the user.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





































Let's personalize your content