This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this post, we guide you through integrating Amazon Bedrock Agents with enterprise data APIs to create more personalized and effective customer support experiences. An automotive retailer might use inventory management APIs to track stock levels and catalog APIs for vehicle compatibility and specifications.
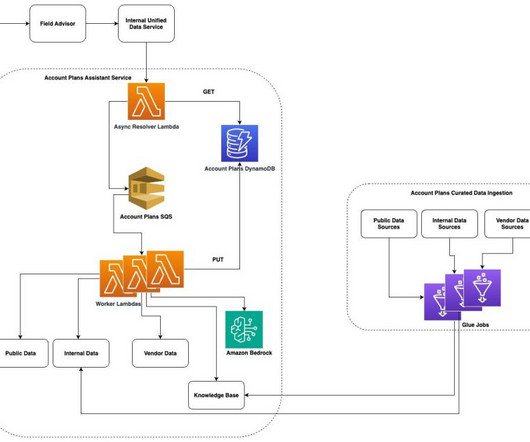
Every year, AWS Sales personnel draft in-depth, forward looking strategy documents for established AWS customers. These documents help the AWS Sales team to align with our customer growth strategy and to collaborate with the entire sales team on long-term growth ideas for AWS customers.
In this post, we focus on one such complex workflow: document processing. Rule-based systems or specialized machine learning (ML) models often struggle with the variability of real-world documents, especially when dealing with semi-structured and unstructured data.
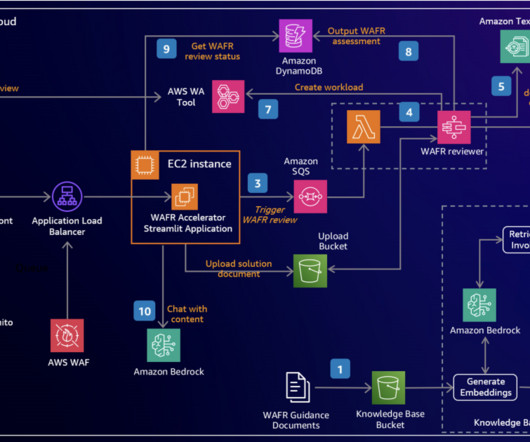
AWS offers powerful generative AI services , including Amazon Bedrock , which allows organizations to create tailored use cases such as AI chat-based assistants that give answers based on knowledge contained in the customers’ documents, and much more. The following figure illustrates the high-level design of the solution.
Google Drive supports storing documents such as Emails contain a wealth of information found in different places, such as within the subject of an email, the message content, or even attachments. Types of documents Gmail messages can be sorted and stored inside your email inbox using folders and labels.
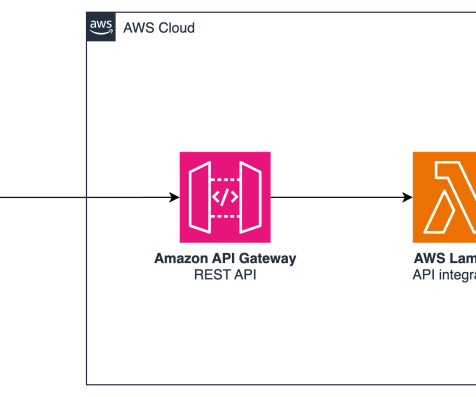
Note that these APIs use objects as namespaces, alleviating the need for explicit imports. API Gateway supports multiple mechanisms for controlling and managing access to an API. AWS Lambda handles the REST API integration, processing the requests and invoking the appropriate AWS services.
It also uses a number of other AWS services such as Amazon API Gateway , AWS Lambda , and Amazon SageMaker. API Gateway is serverless and hence automatically scales with traffic. API Gateway also provides a WebSocket API. Incoming requests to the gateway go through this point.
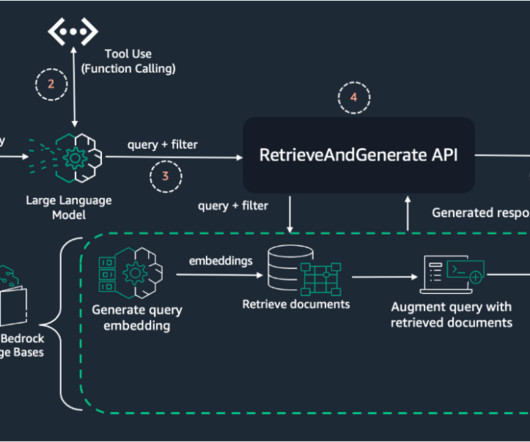
RAG workflow: Converting data to actionable knowledge RAG consists of two major steps: Ingestion Preprocessing unstructured data, which includes converting the data into text documents and splitting the documents into chunks. Document chunks are then encoded with an embedding model to convert them to document embeddings.
Amazon Bedrock Flows offers an intuitive visual builder and a set of APIs to seamlessly link foundation models (FMs), Amazon Bedrock features, and AWS services to build and automate user-defined generative AI workflows at scale. Test the flow Youre now ready to test the flow through the Amazon Bedrock console or API.
This enables sales teams to interact with our internal sales enablement collateral, including sales plays and first-call decks, as well as customer references, customer- and field-facing incentive programs, and content on the AWS website, including blog posts and service documentation.
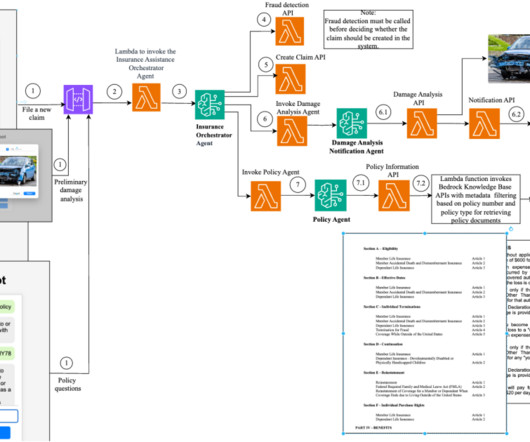
Intricate workflows that require dynamic and complex API orchestration can often be complex to manage. In this post, we explore how chaining domain-specific agents using Amazon Bedrock Agents can transform a system of complex API interactions into streamlined, adaptive workflows, empowering your business to operate with agility and precision.
We recently announced the general availability of cross-account sharing of Amazon SageMaker Model Registry using AWS Resource Access Manager (AWS RAM) , making it easier to securely share and discover machine learning (ML) models across your AWS accounts. Mitigation strategies : Implementing measures to minimize or eliminate risks.
Additionally, TDD facilitates collaboration and knowledge sharing among teams, because tests serve as living documentation and a shared understanding of the expected behavior and constraints. Prerequisites Before you start, make sure you have the following prerequisites in place: Create an AWS account , or sign in to your existing account.
Whether processing invoices, updating customer records, or managing human resource (HR) documents, these workflows often require employees to manually transfer information between different systems a process thats time-consuming, error-prone, and difficult to scale. Prerequisites AWS Command Line Interface (CLI), follow instructions here.
Amazon Textract is a machine learning (ML) service that automatically extracts text, handwriting, and data from scanned documents. Queries is a feature that enables you to extract specific pieces of information from varying, complex documents using natural language. personal or cashier’s checks), financial institution and country (e.g.,
In today’s data-driven business landscape, the ability to efficiently extract and process information from a wide range of documents is crucial for informed decision-making and maintaining a competitive edge. The Anthropic Claude 3 Haiku model then processes the documents and returns the desired information, streamlining the entire workflow.
Prerequisites Before proceeding, make sure that you have the necessary AWS account permissions and services enabled, along with access to a ServiceNow environment with the required privileges for configuration. AWS Have an AWS account with administrative access. Each unit is 20,000 documents. Number of units : Enter 1.
By narrowing down the search space to the most relevant documents or chunks, metadata filtering reduces noise and irrelevant information, enabling the LLM to focus on the most relevant content. This approach narrows down the search space to the most relevant documents or passages, reducing noise and irrelevant information.
Prerequisites Before creating your application in Amazon Bedrock IDE, you’ll need to set up a few resources in your AWS account. This includes setting up Amazon API Gateway , AWS Lambda functions, and Amazon Athena to enable querying the structured sales data. Navigate to the AWS Secrets Manager console and find the secret -api-keys.
Lets say the task at hand is to predict the root cause categories (Customer Education, Feature Request, Software Defect, Documentation Improvement, Security Awareness, and Billing Inquiry) for customer support cases. We suggest consulting LLM prompt engineering documentation such as Anthropic prompt engineering for experiments.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies such as AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon through a single API, along with a broad set of capabilities you need to build generative AI applications with security, privacy, and responsible AI.
By documenting the specific model versions, fine-tuning parameters, and prompt engineering techniques employed, teams can better understand the factors contributing to their AI systems performance. It functions as a standalone HTTP server that provides various REST API endpoints for monitoring, recording, and visualizing experiment runs.
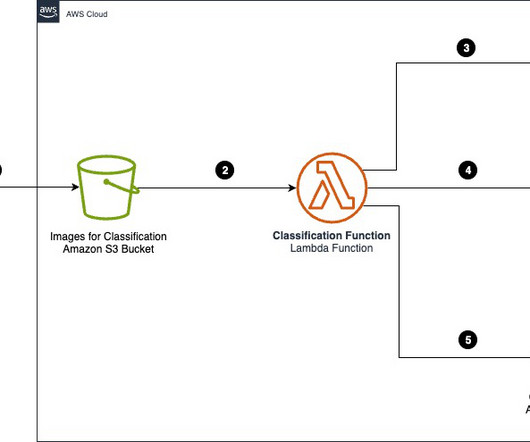
Organizations across industries want to categorize and extract insights from high volumes of documents of different formats. Manually processing these documents to classify and extract information remains expensive, error prone, and difficult to scale. Categorizing documents is an important first step in IDP systems.
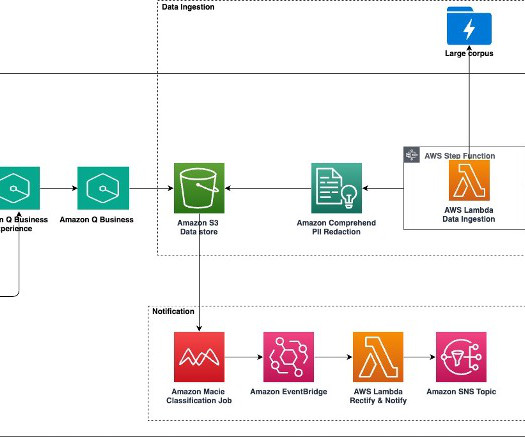
Large-scale data ingestion is crucial for applications such as document analysis, summarization, research, and knowledge management. These tasks often involve processing vast amounts of documents, which can be time-consuming and labor-intensive. For example, the Datastore API might require certain input like date periods to query data.
AWS customers in healthcare, financial services, the public sector, and other industries store billions of documents as images or PDFs in Amazon Simple Storage Service (Amazon S3). In this post, we focus on processing a large collection of documents into raw text files and storing them in Amazon S3.
We demonstrate how to harness the power of LLMs to build an intelligent, scalable system that analyzes architecture documents and generates insightful recommendations based on AWS Well-Architected best practices. An interactive chat interface allows deeper exploration of both the original document and generated content.
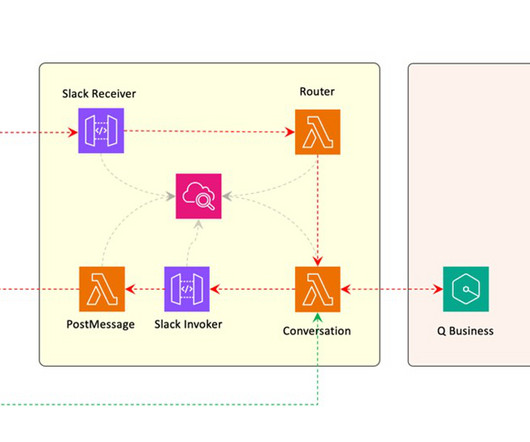
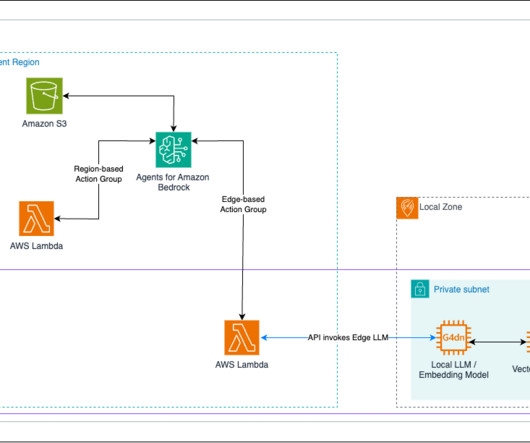
Agent architecture The following diagram illustrates the serverless agent architecture with standard authorization and real-time interaction, and an LLM agent layer using Amazon Bedrock Agents for multi-knowledge base and backend orchestration using API or Python executors. Domain-scoped agents enable code reuse across multiple agents.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
One of the most critical applications for LLMs today is Retrieval Augmented Generation (RAG), which enables AI models to ground responses in enterprise knowledge bases such as PDFs, internal documents, and structured data. Amazon Bedrock APIs make it straightforward to use Amazon Titan Text Embeddings V2 for embedding data.
Designed for both image and document comprehension, Pixtral demonstrates advanced capabilities in vision-related tasks, including chart and figure interpretation, document question answering, multimodal reasoning, and instruction followingseveral of which are illustrated with examples later in this post.
Reduced time and effort in testing and deploying AI workflows with SDK APIs and serverless infrastructure. We can also quickly integrate flows with our applications using the SDK APIs for serverless flow execution — without wasting time in deployment and infrastructure management.
Amazon Bedrock is a fully managed service that offers a choice of high-performing Foundation Models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon via a single API, along with a broad set of capabilities you need to build generative AI applications with security, privacy, and responsible AI.
With GraphStorm, you can build solutions that directly take into account the structure of relationships or interactions between billions of entities, which are inherently embedded in most real-world data, including fraud detection scenarios, recommendations, community detection, and search/retrieval problems. Specifically, GraphStorm 0.3
While using their data source, they want better visibility into the document processing lifecycle during data source sync jobs. They want to know the status of each document they attempted to crawl and index, as well as the ability to troubleshoot why certain documents were not returned with the expected answers.
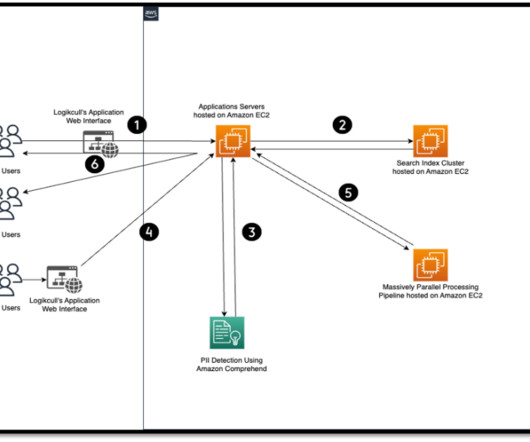
Organizations can search for PII using methods such as keyword searches, pattern matching, data loss prevention tools, machine learning (ML), metadata analysis, data classification software, optical character recognition (OCR), document fingerprinting, and encryption.
We developed the Document Translation app, which uses Amazon Translate , to address these issues. The Document Translation app uses Amazon Translate for performing translations. Amazon Translate provides high-quality document translations for contextual, accurate, and fluent translations. 1 – Translating a document.
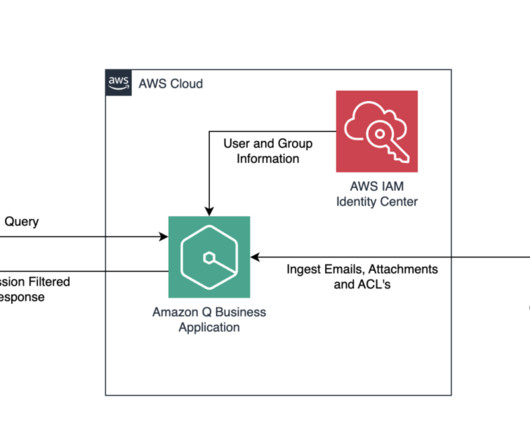
This post shows how to configure an Amazon Q Business custom connector and derive insights by creating a generative AI-powered conversation experience on AWS using Amazon Q Business while using access control lists (ACLs) to restrict access to documents based on user permissions. Who are the data stewards for my proprietary database sources?
The documents uploaded to the knowledge base on the rack might be private and sensitive documents, so they wont be transferred to the AWS Region and will remain completely local on the Outpost rack. This vector database will store the vector representations of your documents, serving as a key component of your local Knowledge Base.
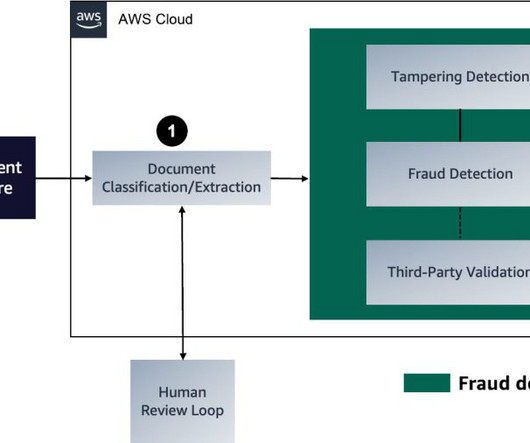
In the first post of this three-part series, we presented a solution that demonstrates how you can automate detecting document tampering and fraud at scale using AWS AI and machine learning (ML) services for a mortgage underwriting use case. The following diagram represents each stage in a mortgage document fraud detection pipeline.
This post presents a solution for developing a chatbot capable of answering queries from both documentation and databases, with straightforward deployment. For documentation retrieval, Retrieval Augmented Generation (RAG) stands out as a key tool. Virginia) AWS Region. The following diagram illustrates the solution architecture.
For more information about the SageMaker AI API, refer to the SageMaker AI API Reference. 8B-Instruct to DeepSeek-R1-Distill-Llama-8B, but the new model version has different API expectations. In this use case, you have configured a CloudWatch alarm to monitor for 4xx errors, which would indicate API compatibility issues.
Amazon Bedrock is a fully managed service that makes FMs from leading AI startups and Amazon available through an API, so you can choose from a wide range of FMs to find the model that is best suited for your use case. Solution overview The solution comprises two main steps: Generate synthetic data using the Amazon Bedrock InvokeModel API.
This intuitive platform enables the rapid development of AI-powered solutions such as conversational interfaces, document summarization tools, and content generation apps through a drag-and-drop interface. The IDP solution uses the power of LLMs to automate tedious document-centric processes, freeing up your team for higher-value work.
These anonymous user applications can be used in use cases such as public website Q&A, documentation portals, and customer self-service experiences. Our example demonstrates a practical scenario: helping website visitors find information on public-facing documentation websites.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content