This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this post, we explore how you can use Amazon Bedrock to generate high-quality categorical ground truth data, which is crucial for training machine learning (ML) models in a cost-sensitive environment. This results in an imbalanced class distribution for training and test datasets.
It also uses a number of other AWS services such as Amazon API Gateway , AWS Lambda , and Amazon SageMaker. API Gateway is serverless and hence automatically scales with traffic. API Gateway also provides a WebSocket API. Incoming requests to the gateway go through this point.
We recently announced the general availability of cross-account sharing of Amazon SageMaker Model Registry using AWS Resource Access Manager (AWS RAM) , making it easier to securely share and discover machine learning (ML) models across your AWS accounts. Mitigation strategies : Implementing measures to minimize or eliminate risks.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
For their AI training and inference workloads, Adobe uses NVIDIA GPU-accelerated Amazon Elastic Compute Cloud (Amazon EC2) P5en (NVIDIA H200 GPUs), P5 (NVIDIA H100 GPUs), P4de (NVIDIA A100 GPUs), and G5 (NVIDIA A10G GPUs) instances. To train generative AI models at enterprise scale, ServiceNow uses NVIDIA DGX Cloud on AWS.
GraphStorm is a low-code enterprise graph machine learning (GML) framework to build, train, and deploy graph ML solutions on complex enterprise-scale graphs in days instead of months. allows you to define multiple training targets on different nodes and edges within a single training loop. Specifically, GraphStorm 0.3
Fine-tuning pre-trained language models allows organizations to customize and optimize the models for their specific use cases, providing better performance and more accurate outputs tailored to their unique data and requirements. Model customization in Amazon Bedrock involves the following actions: Create training and validation datasets.
With access to a wide range of generative AI foundation models (FM) and the ability to build and train their own machine learning (ML) models in Amazon SageMaker , users want a seamless and secure way to experiment with and select the models that deliver the most value for their business. For details, see Creating an AWS account.
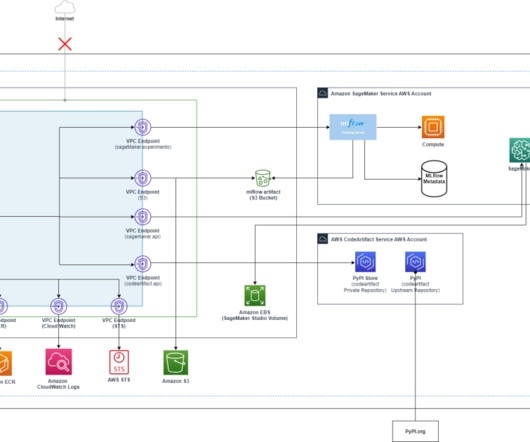
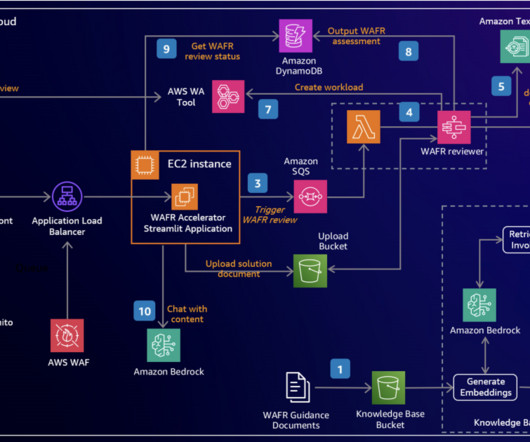
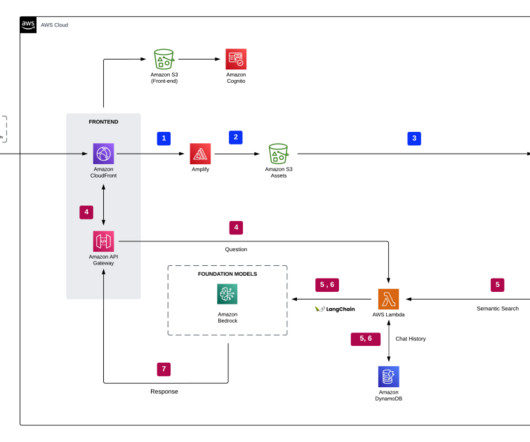
Enabling Global Resiliency for an Amazon Lex bot is straightforward using the AWS Management Console , AWS Command Line Interface (AWS CLI), or APIs. If this option isn’t visible, the Global Resiliency feature may not be enabled for your account. To better understand the solution, refer to the following architecture diagram.
Similarly, maintaining detailed information about the datasets used for training and evaluation helps identify potential biases and limitations in the models knowledge base. It functions as a standalone HTTP server that provides various REST API endpoints for monitoring, recording, and visualizing experiment runs.
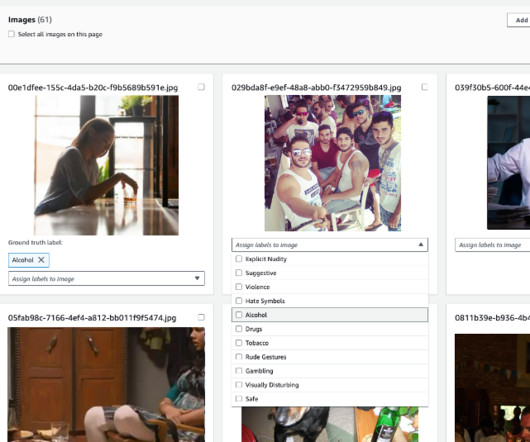
In this post, we discuss how to use the Custom Moderation feature in Amazon Rekognition to enhance the accuracy of your pre-trained content moderation API. You can train a custom adapter with as few as 20 annotated images in less than 1 hour. Create a project A project is a container to store your adapters.
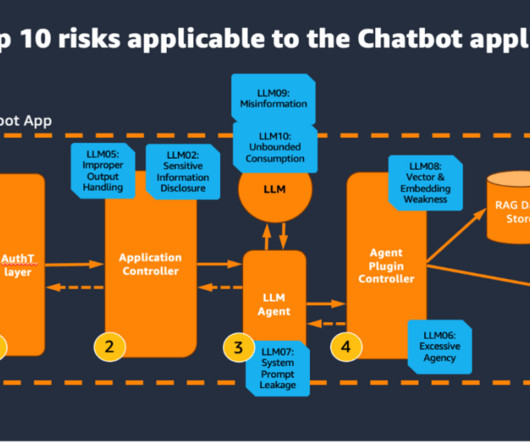
Contrast that with Scope 4/5 applications, where not only do you build and secure the generative AI application yourself, but you are also responsible for fine-tuning and training the underlying large language model (LLM). These steps might involve both the use of an LLM and external data sources and APIs.
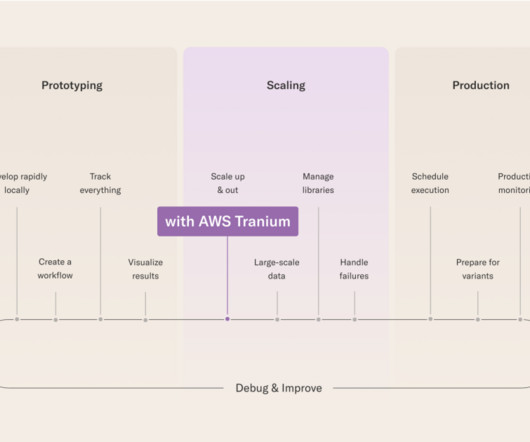
This often means the method of using a third-party LLM API won’t do for security, control, and scale reasons. First, the AWS Trainium accelerator provides a high-performance, cost-effective, and readily available solution for training and fine-tuning large models. The following figure illustrates this workflow.
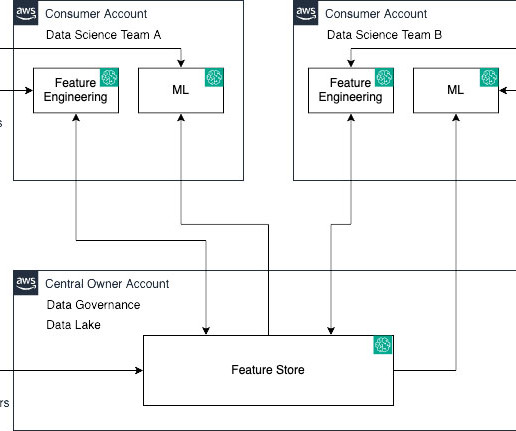
Features are inputs to ML models used during training and inference. Also, when features used to train models offline in batch are made available for real-time inference, it’s hard to keep the two feature stores synchronized. For a deep dive, refer to Cross account feature group discoverability and access.
Many use cases involve using pre-trained large language models (LLMs) through approaches like Retrieval Augmented Generation (RAG). Fine-tuning is a supervised training process where labeled prompt and response pairs are used to further train a pre-trained model to improve its performance for a particular use case.
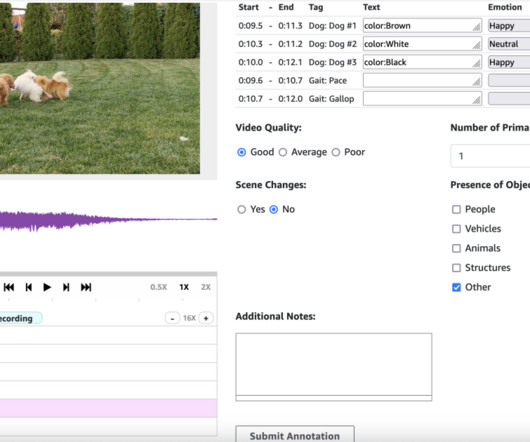
As large language models (LLMs) increasingly integrate more multimedia capabilities, human feedback becomes even more critical in training them to generate rich, multi-modal content that aligns with human quality standards. The path to creating effective AI models for audio and video generation presents several distinct challenges.
The Amazon Bedrock single API access, regardless of the models you choose, gives you the flexibility to use different FMs and upgrade to the latest model versions with minimal code changes. Amazon Titan FMs provide customers with a breadth of high-performing image, multimodal, and text model choices, through a fully managed API.
Discover how the fully managed infrastructure of SageMaker enables high-performance, low cost ML throughout the ML lifecycle, from building and training to deploying and managing models at scale. AWS Trainium and AWS Inferentia deliver high-performance AI training and inference while reducing your costs by up to 50%.
Handling Basic Inquiries : Chat GPT can assist with basic inquiries such as order status, account information, shipping details, or product specifications. Language Support : Chat GPT can be trained in multiple languages, enabling contact centers to provide support to customers globally without the need for multilingual agents.
It provides a collection of pre-trained models that you can deploy quickly, accelerating the development and deployment of ML applications. One of the key components of SageMaker JumpStart is model hubs, which offer a vast catalog of pre-trained models, such as Mistral, for a variety of tasks.
Large organizations often have many business units with multiple lines of business (LOBs), with a central governing entity, and typically use AWS Organizations with an Amazon Web Services (AWS) multi-account strategy. LOBs have autonomy over their AI workflows, models, and data within their respective AWS accounts.
Large language models (LLMs) are generally trained on large publicly available datasets that are domain agnostic. For example, Meta’s Llama models are trained on datasets such as CommonCrawl , C4 , Wikipedia, and ArXiv. The resulting LLM outperforms LLMs trained on non-domain-specific datasets when tested on finance-specific tasks.
While these models are trained on vast amounts of generic data, they often lack the organization-specific context and up-to-date information needed for accurate responses in business settings. The function checks the semantic cache (Amazon Bedrock Knowledge Bases) using the Retrieve API. which is received by the Invoke Agent function.
Within hours, you can annotate your sample documents using the AWS Management Console and train an adapter. Adapters are components that plug in to the Amazon Textract pre-trained deep learning model, customizing its output based on your annotated documents. Adapters can be created via the console or programmatically via the API.
How much budget is remaining for the customer service training initiative? You can integrate Smartsheet to Amazon Q Business through the AWS Management Console , AWS Command Line Interface (AWS CLI), or the CreateDataSource API. In Smartsheet Have access to the Smartsheet Event Reporting API. A Smartsheet access token.
The vision encoder was specifically trained to natively handle variable image sizes, enabling Pixtral to accurately interpret high-resolution diagrams, charts, and documents while maintaining fast inference speeds for smaller images such as icons, clipart, and equations. To begin using Pixtral 12B, choose Deploy.
Frontier large language models (LLMs) like Anthropic Claude on Amazon Bedrock are trained on vast amounts of data, allowing Anthropic Claude to understand and generate human-like text. Solution overview Fine-tuning is a technique in natural language processing (NLP) where a pre-trained language model is customized for a specific task.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading artificial intelligence (AI) companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API. Amazon Bedrock service starts an import job in an AWS operated deployment account.
Amazon Bedrock , a fully managed service offering high-performing foundation models from leading AI companies through a single API, has recently introduced two significant evaluation capabilities: LLM-as-a-judge under Amazon Bedrock Model Evaluation and RAG evaluation for Amazon Bedrock Knowledge Bases.
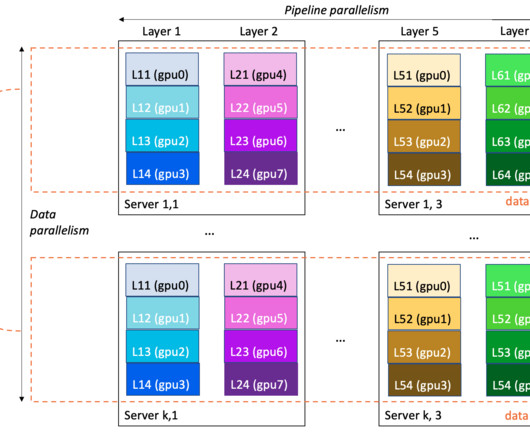
Large language models (LLMs) are neural network-based language models with hundreds of millions ( BERT ) to over a trillion parameters ( MiCS ), and whose size makes single-GPU training impractical. The size of an LLM and its training data is a double-edged sword: it brings modeling quality, but entails infrastructure challenges.
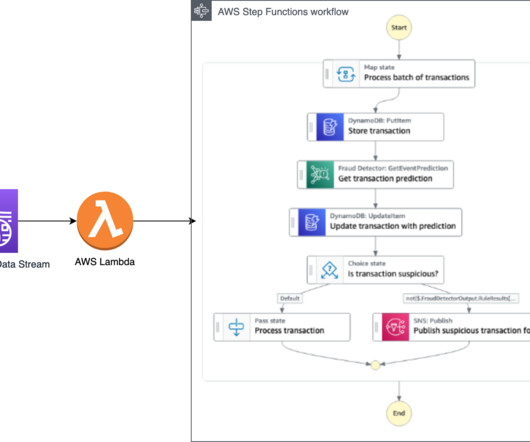
Online fraud has a widespread impact on businesses and requires an effective end-to-end strategy to detect and prevent new account fraud and account takeovers, and stop suspicious payment transactions. You can also use Amazon SageMaker to train a proprietary fraud detection model.
Amazon Bedrock is a fully managed service that offers a choice of high-performing Foundation Models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon via a single API, along with a broad set of capabilities you need to build generative AI applications with security, privacy, and responsible AI.
Its collaborative capabilities such as real-time coediting and sharing notebooks within the team ensures smooth teamwork, while the scalability and high-performance training caters to large datasets. For high availability, multiple identical private isolated subnets are provisioned.
Modern model pre-training often calls for larger cluster deployment to reduce time and cost. At the server level, such training workloads demand faster compute and increased memory allocation. As models grow to hundreds of billions of parameters, they require a distributed training mechanism that spans multiple nodes (instances).
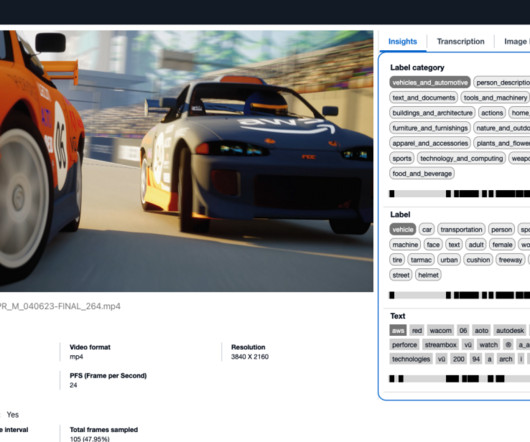
Amazon Rekognition includes a simple, easy-to-use API that can quickly analyze any image or video file that’s stored in Amazon Simple Storage Service (Amazon S3). The following table shows the moderation labels, content type, and confidence scores returned in the API response. Graphic Violence L2 92.6% Explosions and Blasts L3 92.6%
Select your options and train the model. Deploy the API to make predictions. Prerequisites The following are prerequisite steps for this solution: Sign up for an AWS account. Set up permissions that allows your AWS account to access Amazon Fraud Detector. Create the model. Review model performance. Deploy the model.
This allows customers to further pre-train selected models using their own proprietary data to tailor model responses to their business context. This allows customers to further pre-train selected models using their own proprietary data to tailor model responses to their business context. This data must be in the JSON Line format.
In this post, we show how to use Amazon Comprehend Custom to train and host an ML model to classify if the input email is an phishing attempt or not. Comprehend Custom builds customized NLP models on your behalf, using training data that you provide. For minimum training requirements, see General quotas for document classification.
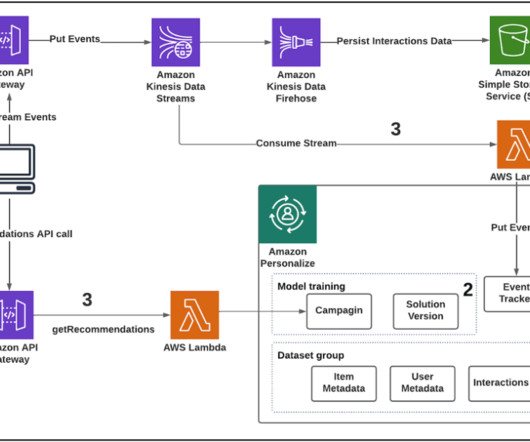
Amazon Personalize provisions the necessary infrastructure and manages the entire machine learning (ML) pipeline, including processing the data, identifying features, using the most appropriate algorithms, and training, optimizing, and hosting the models. An interaction is an event that you record and then import as training data.
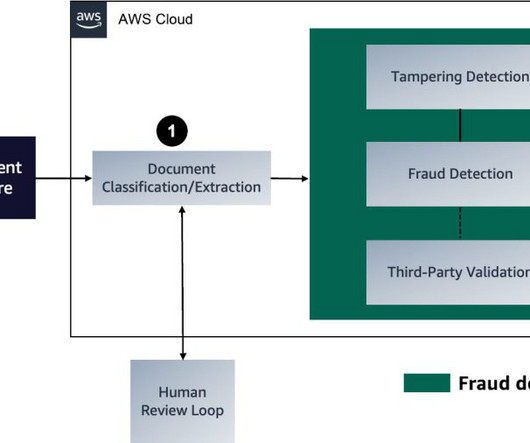
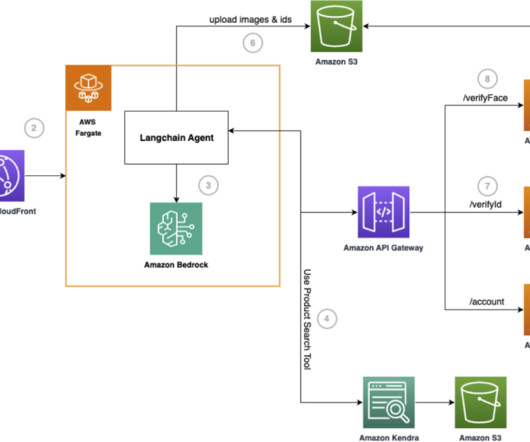
Challenges with traditional onboarding The traditional onboarding process for banks faces challenges in the current digital landscape because many institutions don’t have fully automated account-opening systems. This constraint impacts the flexibility for customers to initiate account opening at their preferred time.
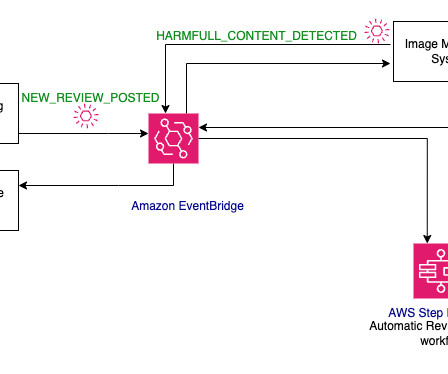
FMs are trained on a broad spectrum of generalized and unlabeled data. FMs and LLMs, even though they’re pre-trained, can continue to learn from data inputs or prompts during inference. Detect if the review content has any harmful information using the Amazon Comprehend DetectToxicContent API.
Data privacy and network security With Amazon Bedrock, you are in control of your data, and all your inputs and customizations remain private to your AWS account. Your data remains in the AWS Region where the API call is processed. It is highly recommended that you use a separate AWS account and setup AWS Budget to monitor the costs.
However, their training on massive datasets also limits their usefulness for specialized tasks. Without continued learning, these models remain oblivious to new data and trends that emerge after their initial training. Furthermore, the cost to train new LLMs can prove prohibitive for many enterprise settings. Python 3.6
Educational tech companies manage large inventories of training videos. The solution is available on the GitHub repository and can be deployed to your AWS account using an AWS Cloud Development Kit (AWS CDK) package. The frontend UI interacts with the extract microservice through a RESTful interface provided by Amazon API Gateway.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content