This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The answer is found in the concept of mental accounting, and it might have significant implications for your Customer Experience. We discussed how our mental accounting affects our behavior as customers in our recent podcast. How Mental Accounting Works. We have written about Mental Accounting before.
Using its enterprise software, FloTorch conducted an extensive comparison between Amazon Nova models and OpenAIs GPT-4o models with the Comprehensive Retrieval Augmented Generation (CRAG) benchmark dataset. FloTorch used these queries and their ground truth answers to create a subset benchmark dataset.
With the advancement of the contact center industry, benchmarks continue to shift and challenge businesses to meet higher customer expectations while maintaining efficiency. In 2025, achieving the right benchmarks means understanding the metrics that matter, tracking them effectively, and striving for continuous improvement.
Sonnet currently ranks at the top of S&P AI Benchmarks by Kensho , which assesses large language models (LLMs) for finance and business. For example, there could be leakage of benchmark datasets’ questions and answers into training data. Anthropic Claude 3.5 Kensho is the AI Innovation Hub for S&P Global. Anthropic Claude 3.5
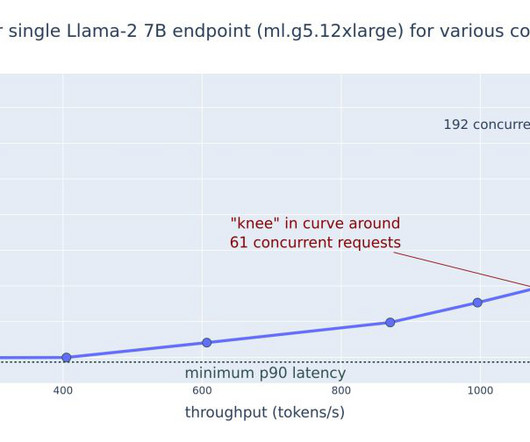
This post explores these relationships via a comprehensive benchmarking of LLMs available in Amazon SageMaker JumpStart, including Llama 2, Falcon, and Mistral variants. We provide theoretical principles on how accelerator specifications impact LLM benchmarking. Additionally, models are fully sharded on the supported instance.
In our webinar, 2022 SaaS retention benchmarks , SaaS Capital Manager Director Rob Belcher shares the results from their 11th annual B2B SaaS benchmarking survey. You can download the full report for net retention and gross retention benchmarks as well as retention metrics in relation to ACV, growth, size, and more.
For example, if you have a multi-step account setup process for a first-time customer on your website, and they are setting up an account at the end of a long day, you can expect them to be more frustrated than a person who is setting up an account first thing in the morning.
All text-to-image benchmarks are evaluated using Recall@5 ; text-to-text benchmarks are evaluated using NDCG@10. Text-to-text benchmark accuracy is based on BEIR, a dataset focused on out-of-domain retrievals (14 datasets). Generic text-to-image benchmark accuracy is based on Flickr and CoCo.
To help determine whether a serverless endpoint is the right deployment option from a cost and performance perspective, we have developed the SageMaker Serverless Inference Benchmarking Toolkit , which tests different endpoint configurations and compares the most optimal one against a comparable real-time hosting instance.
Overview of Pixtral 12B Pixtral 12B, Mistrals inaugural VLM, delivers robust performance across a range of benchmarks, surpassing other open models and rivaling larger counterparts, according to Mistrals evaluation. Performance metrics and benchmarks Pixtral 12B is trained to understand both natural images and documents, achieving 52.5%
Net Promoter Scores are always an interesting topic of conversation, and industry NPS benchmarks even more so. This blog post will discuss NPS benchmarks and look at why NPS is so essential to overall customer success. This is why benchmarking is so important, which we will discuss later.
Now, the question is—what are the metrics and figures to benchmark for every industry? Building their account on highly targeted ad groups. As with previous benchmark reports, the numbers have been consistently high for these industries. Otherwise, they’ll end up inflating their budget to no avail. Average Cost per Click (CPC).
Prerequisites To use the LLM-as-a-judge model evaluation, make sure that you have satisfied the following requirements: An active AWS account. You can confirm that the models are enabled for your account on the Model access page of the Amazon Bedrock console. Selected evaluator and generator models enabled in Amazon Bedrock.
Besides the efficiency in system design, the compound AI system also enables you to optimize complex generative AI systems, using a comprehensive evaluation module based on multiple metrics, benchmarking data, and even judgements from other LLMs. The code from this post and more examples are available in the GitHub repository.
This sets a new benchmark for state-of-the-art performance in critical medical diagnostic tasks, from identifying cancerous cells to detecting genetic abnormalities in tumors. Prerequisites We assume you have access to and are authenticated in an AWS account. The AWS CloudFormation template for this solution uses t3.medium
Google used to mine all kinds of data from people’s Gmail accounts and people were OK with that because they got free email. If you want to benchmark your organization’s performance in the new world of behavioral economics against other companies, take our short questionnaire. Sincerely, Big Brother*. *
Accountability. Their suite of products and services allow you to truly understand your customer experience through detailed performance analysis and competitor benchmarking, all underpinned by tangible recommendations from real CX experts and the latest in AI and machine learning capabilities. What’s driving this paradoxical shift?
According to a survey from PwC, nearly half (48%) of U.S. consumers define good customer service as friendly and welcoming. Meanwhile, an overwhelming majority (82%) of the top-performing companies report paying “close attention” to customer experience.
In this sense, CES can almost act as a gauge of how well a company is doing against its benchmarks and those of competitors. For SaaS products, consider questions like: “How easy was it to set up your account?” This provides a baseline for comparison over time and against industry benchmarks.
As the Director of Strategic Accounts at TechSee, I’ve had the privilege of working with tech giants like AWS, and many others. Test the results (new tiny LLM benchmarks are promising) and design escalation to an expert when needed. I’m Megan Saucier , your friendly guide through the ever-evolving landscape of technology.
A set of key performance indicators and benchmarks to track and measure client progress towards goals. This stands in contrast to plans shared via email or in a spreadsheet, where it becomes difficult to tie these outcomes to customer accounts. How Do You Use a Customer Success Plan?
Define expectations and establish accountability. If you want to benchmark your organization’s performance in the new world of behavioral economics against other companies, take our short questionnaire. They see a problem, and know it has to be fixed, but it’s uncomfortable. Hold each other and your teams to a standard.
A common way to select an embedding model (or any model) is to look at public benchmarks; an accepted benchmark for measuring embedding quality is the MTEB leaderboard. The Massive Text Embedding Benchmark (MTEB) evaluates text embedding models across a wide range of tasks and datasets.
FCR on social/text needs to be amended to first conversation resolution as customers rarely provide all info needed to resolve a query upfront, but measuring this provides a benchmark you can use against other channels. Smitha obtained her license as CPA in 2007 from the California Board of Accountancy. Reuben Kats @grab_results.
Customer interactions are at the heart of every contact center, so it makes sense to take their feedback into account. By taking this step, you’ll be able to account for the customer experience — after all, there’s no point in implementing a strategy that makes them unhappy. Create a benchmark for success.
According to the 2019 Global Customer Experience Benchmarking Report from NTT Ltd., Once contact centers are aware of agents’ needs, they can take them into account when deciding on new workplace strategies and policies. According to the 2019 Global Customer Experience, Benchmarking Report from NTT Ltd.,
Service Level Targets Service levels are benchmarks that determine the quality of customer interactions. These tools can also account for real-time changes, ensuring forecasts remain relevant in dynamic environments. Understanding peak hours and slow periods ensures efficient shift scheduling.
It’s important to have NPS benchmarks in mind so you can start making effective changes based on your score. Benchmarks allow you to figure out when your score is good, when and where there’s room for improvement, and how you might compare to other competitors in your industry. External Benchmarks. Internal Benchmarks.
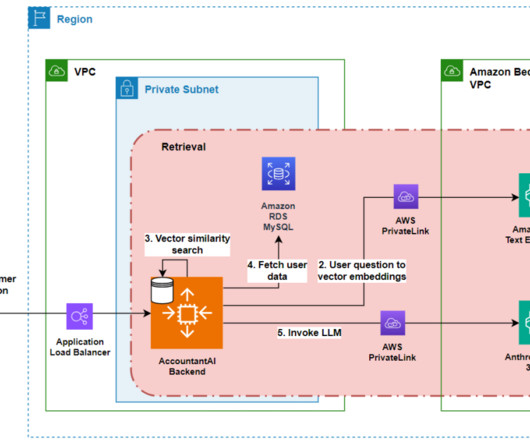
Aligning with AWS multi-account best practices The solution outlined in this post spans across several accounts in a given AWS organization. For a deeper look at the various components required for an AWS organization multi-account enterprise ML environment, see MLOps foundation roadmap for enterprises with Amazon SageMaker.
A common grade of service is 70% in 20 seconds however service level goals should take into account corporate objectives, market position, caller captivity, customer perceptions of the company, benchmarking surveys and what your competitors are doing. First Contact Resolution. Net Promoter Score.
The 2024 B2B SaaS Benchmarking Survey by SaaS Capital is the most comprehensive and up-to-date source of its kind for SaaS and customer success leaders who want to know where they stand compared to peers and competitors. We’re operating under the concept of rule of 60, with growth account ing for 20% and margins for 40%.
Impact: Fortune 500 companies that excel at recruitment marketing strategies have 62% higher average revenue per year than those with average scores, and 152% higher average revenue per year than those with failing recruitment scores (SmashFly’s Fortune 500 Report: 2018 Recruitment Marketing Benchmarks).
Accountability. Their suite of products and services allow you to truly understand your customer experience through detailed performance analysis and competitor benchmarking, all underpinned by tangible recommendations from real CX experts and the latest in AI and machine learning capabilities. What’s driving this paradoxical shift?
Techniques : AI Chatbots can resolve frequently asked questions like “How do I retrieve my account?” By benchmarking these KPIs regularly, you can identify bottlenecks and make improvements. It sets your brand apart in a competitive industry where gamers demand accountability and responsiveness.
Small business proprietors tend to prioritize the operational aspects of their enterprises over administrative tasks, such as maintaining financial records and accounting. While hiring a professional accountant can provide valuable guidance and expertise, it can be cost-prohibitive for many small businesses.
The bottom line: increase account growth and decrease customer churn. The main benefit of a customer success software that executive management should be aware of is the fact that it can increase account growth and decrease customer churn. With this level of visibility, CSMs can be more agile and address issues faster.
And how can I hold my vendors to account if they aren’t delivering the required service? Yet, resolving a ticket with a vendor where full details of a fault are unclear can be a lengthy process (even without accounting for how long it may have taken for the fault to be recognised in the first place).
Smitha obtained her license as CPA in 2007 from the California Board of Accountancy. With more than 15 years of experience in business, finance and accounting, she is also responsible for implementing financial controls and processes. Set your goals (contact concurrency or resolution time, the percentage of first time resolution, etc.)
The power of a benchmark comparison in phone number testing When you receive an alert that your phone number is not functioning, you know immediately that there is a problem. Being able to benchmark your results against other organizations helps point out where issues might be, and provides guidelines to help you fix any hidden issues.
If the vendor has been smart enough to collect aggregate data about how its customers use the product or service, it can also offer useful benchmark metrics to bolster that guidance.” If your customer churn rate is higher than these benchmarks, chances are, your company would benefit greatly by redoubling its efforts on Customer Success.
Prerequisites To run the example notebooks, you need an AWS account with an AWS Identity and Access Management (IAM) role with permissions to manage resources created. For details, refer to Create an AWS account. DeepSeek-R1-Distill-Llama-8B DeepSeek-R1-Distill-Llama-8B was benchmarked across ml.g5.2xlarge , ml.g5.12xlarge , ml.g6e.2xlarge
By regularly asking these questions and keeping your team accountable, your onboarding process will grow alongside your customers. Then adjust and set benchmarks as customers work through those tasks, creating baselines that are easy to review in the future Ask: Where are most customers getting stuck during onboarding?
Prerequisites To implement this solution, you need the following: An AWS account with privileges to create AWS Identity and Access Management (IAM) roles and policies. You must follow the provided notebook to reproduce the solution. We elaborate on the main code components in this post.
In this article, we cover: Budgeting Benchmarks: Do They Cause More Harm than Good? Budgeting Benchmarks: Do They Cause More Harm than Good? If you’re in the Customer Success industry, you’re probably familiar with these popular budgeting benchmarks: CSMs should manage $1 million to $5 million in Annual Recurring Revenue (ARR).
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content