This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Using its enterprise software, FloTorch conducted an extensive comparison between Amazon Nova models and OpenAIs GPT-4o models with the Comprehensive Retrieval Augmented Generation (CRAG) benchmark dataset. FloTorch used these queries and their ground truth answers to create a subset benchmark dataset.
All text-to-image benchmarks are evaluated using Recall@5 ; text-to-text benchmarks are evaluated using NDCG@10. Text-to-text benchmark accuracy is based on BEIR, a dataset focused on out-of-domain retrievals (14 datasets). Generic text-to-image benchmark accuracy is based on Flickr and CoCo.
Curated judge models : Amazon Bedrock provides pre-selected, high-quality evaluation models with optimized prompt engineering for accurate assessments. Expert analysis : Data scientists or machine learning engineers analyze the generated reports to derive actionable insights and make informed decisions. 0]}-{evaluator_model.split('.')[0]}-{datetime.now().strftime('%Y-%m-%d-%H-%M-%S')}"
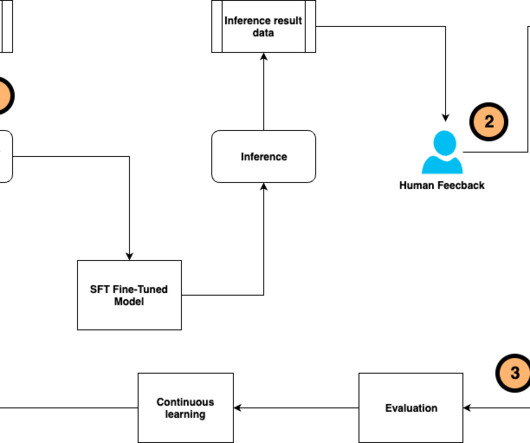
Compound AI system and the DSPy framework With the rise of generative AI, scientists and engineers face a much more complex scenario to develop and maintain AI solutions, compared to classic predictive AI. In the next section, we discuss using a compound AI system to implement this framework to achieve high versatility and reusability.
Model choices – SageMaker JumpStart offers a selection of state-of-the-art ML models that consistently rank among the top in industry-recognized HELM benchmarks. We also use Vector Engine for Amazon OpenSearch Serverless (currently in preview) as the vector data store to store embeddings. An Amazon SageMaker Studio domain and user.
This requirement translates into time and effort investment of trained personnel, who could be support engineers or other technical staff, to review tens of thousands of support cases to arrive at an even distribution of 3,000 per category. Sonnet prediction accuracy through prompt engineering. We expect to release version 4.2.2
Now, the question is—what are the metrics and figures to benchmark for every industry? The higher its quality, the lower its CPC, and the better its position on search engines. Building their account on highly targeted ad groups. As with previous benchmark reports, the numbers have been consistently high for these industries.
FCR on social/text needs to be amended to first conversation resolution as customers rarely provide all info needed to resolve a query upfront, but measuring this provides a benchmark you can use against other channels. Smitha obtained her license as CPA in 2007 from the California Board of Accountancy. Reuben Kats @grab_results.
It simplifies data integration from various sources and provides tools for data indexing, engines, agents, and application integrations. Prerequisites To implement this solution, you need the following: An AWS account with privileges to create AWS Identity and Access Management (IAM) roles and policies.
For example, for mixed AI workloads, the AI inference is part of the search engine service with real-time latency requirements. First, we had to experiment and benchmark in order to determine that Graviton3 was indeed the right solution for us. After that was confirmed, we had to perform the actual migration.
A common way to select an embedding model (or any model) is to look at public benchmarks; an accepted benchmark for measuring embedding quality is the MTEB leaderboard. The Massive Text Embedding Benchmark (MTEB) evaluates text embedding models across a wide range of tasks and datasets.
Use cases we have worked on include: Technical assistance for field engineers – We built a system that aggregates information about a company’s specific products and field expertise. A chatbot enables field engineers to quickly access relevant information, troubleshoot issues more effectively, and share knowledge across the organization.
Acting as a model hub, JumpStart provided a large selection of foundation models and the team quickly ran their benchmarks on candidate models. Here, Amazon SageMaker Ground Truth allowed ML engineers to easily build the human-in-the-loop workflow (step v). The Amazon API Gateway receives the PUT request (step 1).
With a focus on responsible innovation and system-level safety, these new models demonstrate state-of-the-art performance on a wide range of industry benchmarks and introduce features that help you build a new generation of AI experiences. With SageMaker, you can streamline the entire model deployment process. 32xlarge Llama-3.2-1B-Instruct
The buffer was implemented after benchmarking the captioning model’s performance. The benchmarking revealed that the model performed optimally when processing batches of images, but underperformed when analyzing individual images. About the authors Vlad Lebedev is a Senior Technology Leader at Mixbook.
Prerequisites To build the solution yourself, there are the following prerequisites: You need an AWS account with an AWS Identity and Access Management (IAM) role that has permissions to manage resources created as part of the solution (for example AmazonSageMakerFullAccess and AmazonS3FullAccess ).
and run inference: An AWS account that will contain all your AWS resources. Recommended instances and benchmarks The following table lists all the Meta SAM 2.1 Banu Nagasundaram leads product, engineering, and strategic partnerships for Amazon SageMaker JumpStart, SageMaker AIs machine learning and generative AI hub.
A recent AVANT “6-12” report focusing on CCaaS notes that the CCaaS market currently accounts for more than $3 billion in global sales. But, many engineering teams have had their fire fighting experiences. One survey notes that responding CIOs indicate their use of on-premise applications dropped by more than 40% in 2021.
Additionally, evaluation can identify potential biases, hallucinations, inconsistencies, or factual errors that may arise from the integration of external sources or from sub-optimal prompt engineering. In this case, the model choice needs to be revisited or further prompt engineering needs to be done.
Smitha obtained her license as CPA in 2007 from the California Board of Accountancy. With more than 15 years of experience in business, finance and accounting, she is also responsible for implementing financial controls and processes. Set your goals (contact concurrency or resolution time, the percentage of first time resolution, etc.)
To overcome this, enterprises needs to shape a clear operating model defining how multiple personas, such as data scientists, data engineers, ML engineers, IT, and business stakeholders, should collaborate and interact; how to separate the concerns, responsibilities, and skills; and how to use AWS services optimally.
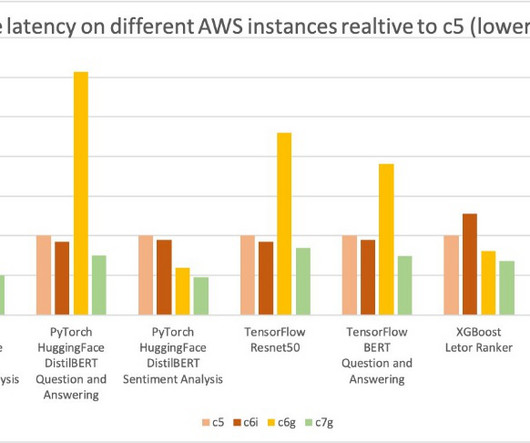
We cover computer vision (CV), natural language processing (NLP), classification, and ranking scenarios for models and ml.c6g, ml.c7g, ml.c5, and ml.c6i SageMaker instances for benchmarking. You can use the sample notebook to run the benchmarks and reproduce the results. Mohan Gandhi is a Senior Software Engineer at AWS.
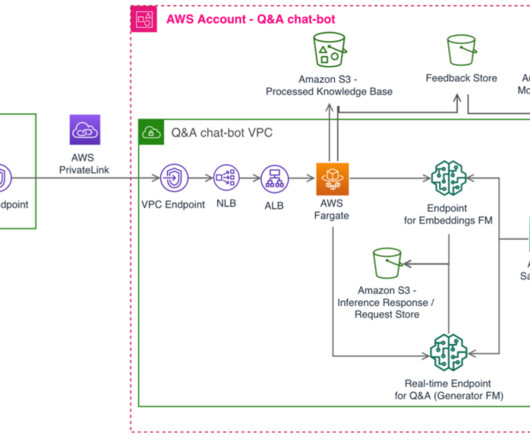
SageMaker JumpStart allowed the team to experiment quickly with different models, running different benchmarks and tests, failing fast as needed. The Q&A chatbot likewise has its own AWS account for role separation, isolation, and ease of monitoring for security, cost, and compliance purposes. Jangwon Kim is a Sr.
In this part of the blog series, we review techniques of prompt engineering and Retrieval Augmented Generation (RAG) that can be employed to accomplish the task of clinical report summarization by using Amazon Bedrock. Prompt engineering helps to effectively design and improve prompts to get better results on different tasks with LLMs.
Three tricks we used to accomplish this include: Be RACI: Using a responsibility assignment matrix (aka a RACI—Responsible, Accountable, Consulted, Informed—matrix) has helped us to clearly define the roles and responsibilities between our CS and sales teams. At the same time, you can build out new opportunities to drive that value.
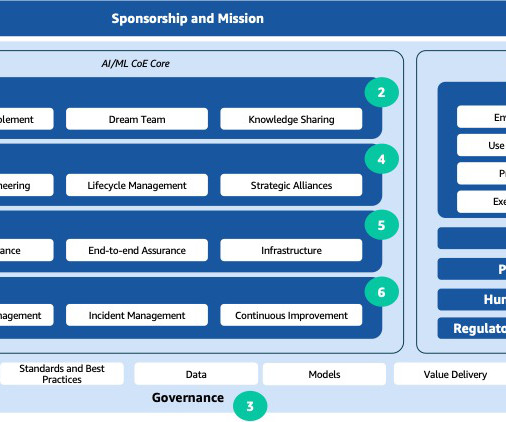
By taking a proactive approach , the CoE provides ethical compliance but also builds trust, enhances accountability, and mitigates potential risks such as veracity, toxicity, data misuse, and intellectual property concerns. Platform – A central platform such as Amazon SageMaker for creation, training, and deployment.
Figure 5 offers an overview on generative AI modalities and optimization strategies, including prompt engineering , Retrieval Augmented Generation , and fine-tuning or continued pre-training. This balance must account for the assessment of risk in terms of several factors such as quality, disclosures, or reporting.
If the vendor has been smart enough to collect aggregate data about how its customers use the product or service, it can also offer useful benchmark metrics to bolster that guidance.” If your customer churn rate is higher than these benchmarks, chances are, your company would benefit greatly by redoubling its efforts on Customer Success.
Our field organization includes customer-facing teams (account managers, solutions architects, specialists) and internal support functions (sales operations). Personalized content will be generated at every step, and collaboration within account teams will be seamless with a complete, up-to-date view of the customer.
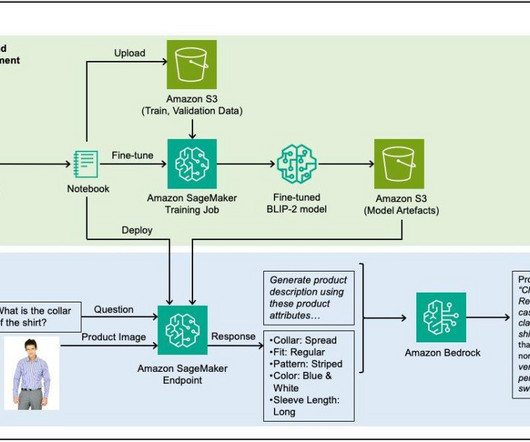
Customers can more easily locate products that have correct descriptions, because it allows the search engine to identify products that match not just the general category but also the specific attributes mentioned in the product description. For details, see Creating an AWS account. We use Amazon SageMaker Studio with the ml.t3.medium
Performance metrics and benchmarks According to Mistral, the instruction-tuned version of the model achieves over 81% accuracy on Massive Multitask Language Understanding (MMLU) with 150 tokens per second latency, making it currently the most efficient model in its category.
These teams are as follows: Advanced analytics team (data lake and data mesh) – Data engineers are responsible for preparing and ingesting data from multiple sources, building ETL (extract, transform, and load) pipelines to curate and catalog the data, and prepare the necessary historical data for the ML use cases.
This may be related to a complicated deployment such as enterprise software, or peer-to-peer, such as engineers from the supplier and customer companies meeting to work out usage details, or a customer appointee who interfaces with multiple locations of the supplier company in a single morning. B2B Customer Experience: Do This, Not That.
An illuminated “check engine” light is scary because it doesn’t offer any solution. For many, “check engine” may as well just say “car broken”—and that’s terrifying. A customer success health score is a framework used to identify the status of your customers so you can quickly prioritize accounts. Properly Weigh Your Metrics.
Rather than requiring extensive feature engineering and dataset labeling, LLMs can be fine-tuned on small amounts of domain-specific data to quickly adapt to new use cases. This post walks through examples of building information extraction use cases by combining LLMs with prompt engineering and frameworks such as LangChain.
Touchpoints may involve any medium you use to interact with customers, including: Search engine marketing. This may occur through encountering your brand or product through a search engine result, a search engine ad, a social media post, a video, a review on a technology website, word-of-mouth or other means. Blog content.
Leave the session inspired to bring Amazon Q Apps to supercharge your teams’ productivity engines. Learn how they created specialized agents for different tasks like account management, repos, pipeline management, and more to help their developers go faster.
It will help you set benchmarks to get a clear picture of your performance with your customers. A Net Promoter Score (NPS) is a customer satisfaction benchmark that measures how likely your customers are to recommend you to a friend or colleague. Products & Engineering. Let’s start with the basics.
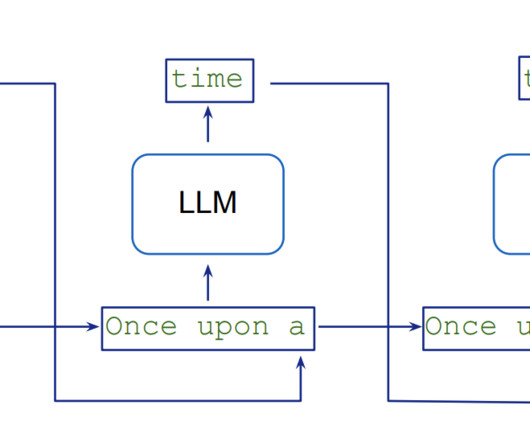
You can fine-tune the following parameters in serving.properties of the LMI container for using continuous batching: engine – The runtime engine of the code. The following diagram shows the dynamic batching of requests with different input sequence lengths being processed together by the model. Use MPI to enable continuous batching.
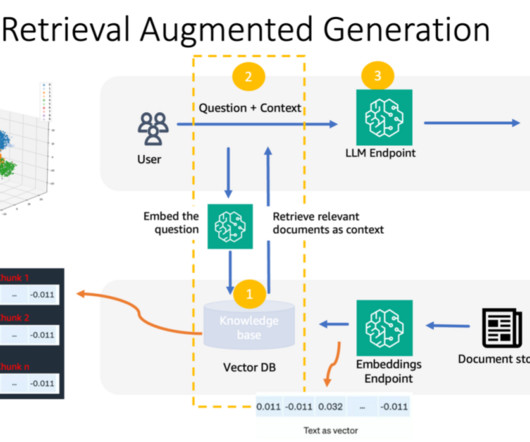
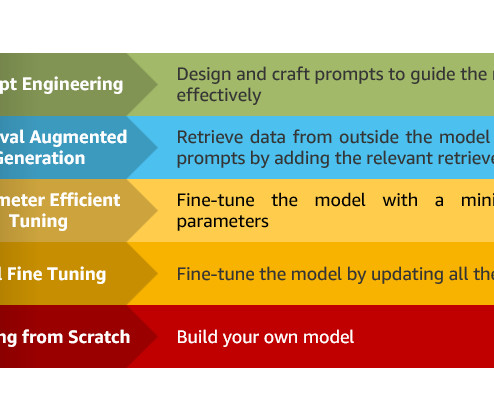
In particular, we provide practical best practices for different customization scenarios, including training models from scratch, fine-tuning with additional data using full or parameter-efficient techniques, Retrieval Augmented Generation (RAG), and prompt engineering. How can your generative AI project support sustainable innovation?
PrestoDB is an open source SQL query engine that is designed for fast analytic queries against data of any size from multiple sources. For more information on the TPC-H data, its database entities, relationships, and characteristics, refer to TPC Benchmark H. Twilio needed to implement an MLOps pipeline that queried data from PrestoDB.
We provide an overview of key generative AI approaches, including prompt engineering, Retrieval Augmented Generation (RAG), and model customization. Building large language models (LLMs) from scratch or customizing pre-trained models requires substantial compute resources, expert data scientists, and months of engineering work.
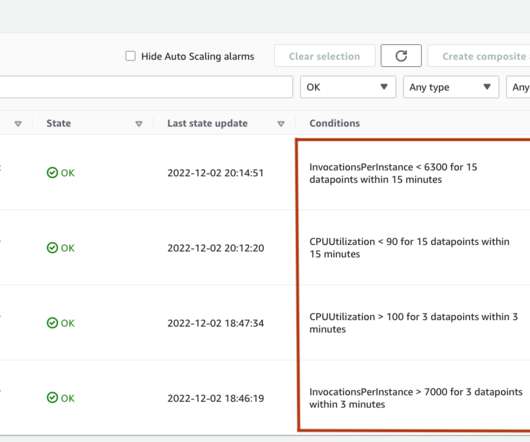
The procedure is further simplified with the use of Inference Recommender , a right-sizing and benchmarking tool built inside SageMaker. However, you can use any other benchmarking tool. Benchmarking To derive the right scaling policy, the first step in the plan is to determine application behavior on the chosen hardware.
Prompt engineering Prompt engineering refers to efforts to extract accurate, consistent, and fair outputs from large models, such text-to-image synthesizers or large language models. For more information, refer to EMNLP: Prompt engineering is the new feature engineering.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content