This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Using its enterprise software, FloTorch conducted an extensive comparison between Amazon Nova models and OpenAIs GPT-4o models with the Comprehensive Retrieval Augmented Generation (CRAG) benchmark dataset. The following table provides example questions with their domain and question type.
The answer is found in the concept of mental accounting, and it might have significant implications for your Customer Experience. We discussed how our mental accounting affects our behavior as customers in our recent podcast. How Mental Accounting Works. We have written about Mental Accounting before.
With the advancement of the contact center industry, benchmarks continue to shift and challenge businesses to meet higher customer expectations while maintaining efficiency. In 2025, achieving the right benchmarks means understanding the metrics that matter, tracking them effectively, and striving for continuous improvement.
Sonnet currently ranks at the top of S&P AI Benchmarks by Kensho , which assesses large language models (LLMs) for finance and business. For example, there could be leakage of benchmark datasets’ questions and answers into training data. Anthropic Claude 3.5 Kensho is the AI Innovation Hub for S&P Global.
For example, if you are staying in a hotel in a certain city and a friend of yours has stayed there also, and they say, “It’s like the Four Seasons Resort,” you now have a pretty high reference point. Professor Hamilton’s favorite example is choosing a political candidate in a tight race.
In this post, we discuss the benefits and capabilities of this new model with some examples. The following figure illustrates an example of this workflow. The following figure illustrates some examples of these use cases. Generic text-to-image benchmark accuracy is based on Flickr and CoCo.
Overview of Pixtral 12B Pixtral 12B, Mistrals inaugural VLM, delivers robust performance across a range of benchmarks, surpassing other open models and rivaling larger counterparts, according to Mistrals evaluation. Performance metrics and benchmarks Pixtral 12B is trained to understand both natural images and documents, achieving 52.5%
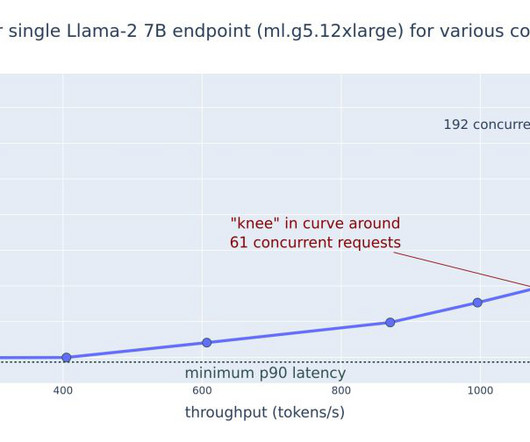
This post explores these relationships via a comprehensive benchmarking of LLMs available in Amazon SageMaker JumpStart, including Llama 2, Falcon, and Mistral variants. We provide theoretical principles on how accelerator specifications impact LLM benchmarking. Additionally, models are fully sharded on the supported instance.
Besides the efficiency in system design, the compound AI system also enables you to optimize complex generative AI systems, using a comprehensive evaluation module based on multiple metrics, benchmarking data, and even judgements from other LLMs. The code from this post and more examples are available in the GitHub repository.
To help determine whether a serverless endpoint is the right deployment option from a cost and performance perspective, we have developed the SageMaker Serverless Inference Benchmarking Toolkit , which tests different endpoint configurations and compares the most optimal one against a comparable real-time hosting instance.
Prerequisites To use the LLM-as-a-judge model evaluation, make sure that you have satisfied the following requirements: An active AWS account. You can confirm that the models are enabled for your account on the Model access page of the Amazon Bedrock console. Selected evaluator and generator models enabled in Amazon Bedrock.
This sets a new benchmark for state-of-the-art performance in critical medical diagnostic tasks, from identifying cancerous cells to detecting genetic abnormalities in tumors. Through practical examples, we show you how to adapt this FM to these specific use cases while optimizing computational resources.
For example, companies now use your Wi-Fi connection to know where you are when you linger in a store and don’t get me started on the sheer amount of information “they” have about your clickstream data (i.e., Google used to mine all kinds of data from people’s Gmail accounts and people were OK with that because they got free email.
At others, customer success specialists are accountable for managing churn and providing essential support. No matter what type of customer success team you’ve built, we have guidance and real-world examples of helpful ways to write your customer success specialist job description to start drawing in qualified candidates.
To mitigate this challenge, thorough model evaluation, benchmarking, and data-aware optimization are essential, to compare the Amazon Nova models performance against the model used before the migration, and optimize the prompts on Amazon Nova to align performance with that of the previous workload or improve upon them.
Our recommendations are based on extensive experiments using public benchmark datasets across various vision-language tasks, including visual question answering, image captioning, and chart interpretation and understanding. Prerequisites To use this feature, make sure that you have satisfied the following requirements: An active AWS account.
By regularly asking these questions and keeping your team accountable, your onboarding process will grow alongside your customers. Then adjust and set benchmarks as customers work through those tasks, creating baselines that are easy to review in the future Ask: Where are most customers getting stuck during onboarding?
Net Promoter Scores are always an interesting topic of conversation, and industry NPS benchmarks even more so. This blog post will discuss NPS benchmarks and look at why NPS is so essential to overall customer success. For example, the average NPS score in 2021 for the retail sector is 32.9, and IT services is 42.
Define expectations and establish accountability. For example, with email she suggested they respond immediately with an acknowledgment of the receipt of the inquiry and a message that informs the customer you are working on it. For example, can a customer go to your website and find your phone number, or do they have to hunt for it?
We published a follow-up post on January 31, 2024, and provided code examples using AWS SDKs and LangChain, showcasing a Streamlit semantic search app. For example, in a recommendation system for a large ecommerce platform, a modest increase in recommendation accuracy could translate into significant additional revenue.
We’ll also look at real-world examples of companies that have leveraged CES to improve their customer experience and boost retention rates. In this sense, CES can almost act as a gauge of how well a company is doing against its benchmarks and those of competitors. ” “Do you like using our software?”
Now, the question is—what are the metrics and figures to benchmark for every industry? Building their account on highly targeted ad groups. For example, if an e-commerce ad has 10 clicks after being seen 200 times, the CTR would be 5%. For example, a consultation service puts up an ad leading to a “contact us” form.
For example, DeepSeek-R1-Distill-Llama-8B offers an excellent balance of performance and efficiency. In the following code snippets, we use the LMI container example. See the following GitHub repo for more deployment examples using TGI, TensorRT-LLM, and Neuron. For details, refer to Create an AWS account.
We also showcase a real-world example for predicting the root cause category for support cases. For the use case of labeling the support root cause categories, its often harder to source examples for categories such as Software Defect, Feature Request, and Documentation Improvement for labeling than it is for Customer Education.
Here are some examples of these metrics: Retrieval component Context precision Evaluates whether all of the ground-truth relevant items present in the contexts are ranked higher or not. For example, metrics like Answer Relevancy and Faithfulness are typically scored on a scale from 0 to 1.
For example, a technician could query the system about a specific machine part, receiving both textual maintenance history and annotated images showing wear patterns or common failure points, enhancing their ability to diagnose and resolve issues efficiently. has 92% accuracy on the HumanEval code benchmark.
Benchmarking, or setting customer expectations, is a well known psychological tool that helps customers evaluate the quality of your customer service. For example, we don’t look at the number on our paycheck and decide we make enough money. For example, Baskits sells food items, which can’t be returned for obvious reasons.
In our example, the organization is willing to approve a model for deployment if it passes their checks for model quality, bias, and feature importance prior to deployment. Aligning with AWS multi-account best practices The solution outlined in this post spans across several accounts in a given AWS organization.
Performance metrics and benchmarks According to Mistral, the instruction-tuned version of the model achieves over 81% accuracy on Massive Multitask Language Understanding (MMLU) with 150 tokens per second latency, making it currently the most efficient model in its category. For example, content for inference.
A set of key performance indicators and benchmarks to track and measure client progress towards goals. This stands in contrast to plans shared via email or in a spreadsheet, where it becomes difficult to tie these outcomes to customer accounts. How Do You Use a Customer Success Plan?
Impact: Fortune 500 companies that excel at recruitment marketing strategies have 62% higher average revenue per year than those with average scores, and 152% higher average revenue per year than those with failing recruitment scores (SmashFly’s Fortune 500 Report: 2018 Recruitment Marketing Benchmarks). Distrust of leadership.
For example, if you’re looking to increase productivity and agent performance, you’re likely looking at a larger goal of improving employee engagement. Customer interactions are at the heart of every contact center, so it makes sense to take their feedback into account. Create a benchmark for success.
FCR on social/text needs to be amended to first conversation resolution as customers rarely provide all info needed to resolve a query upfront, but measuring this provides a benchmark you can use against other channels. Smitha obtained her license as CPA in 2007 from the California Board of Accountancy. Reuben Kats @grab_results.
To show you some of the ways live chat can be used, and how it can benefit both your customers and agents, here are our top 5 live chat examples to inspire you. Thanks to Comm100’s robust security standards , members can retrieve account information safely and securely through the live chat window. at that time. Customer Stories.
For example, for mixed AI workloads, the AI inference is part of the search engine service with real-time latency requirements. First, we had to experiment and benchmark in order to determine that Graviton3 was indeed the right solution for us. Technical Account Manager at AWS with 15 years of experience. Gaurav Garg is a Sr.
Through comparative benchmarking tests, we illustrate how deploying FMs in Local Zones closer to end users can significantly reduce latencya critical factor for real-time applications such as conversational AI assistants. Under Name and tags , enter a descriptive name for the instance (for example, la-local-zone-instance ).
Service Level Targets Service levels are benchmarks that determine the quality of customer interactions. These tools can also account for real-time changes, ensuring forecasts remain relevant in dynamic environments. Examples include workforce management systems and predictive analytics platforms.
With GraphStorm, you can build solutions that directly take into account the structure of relationships or interactions between billions of entities, which are inherently embedded in most real-world data, including fraud detection scenarios, recommendations, community detection, and search/retrieval problems. In addition, GraphStorm 0.3
Small business proprietors tend to prioritize the operational aspects of their enterprises over administrative tasks, such as maintaining financial records and accounting. While hiring a professional accountant can provide valuable guidance and expertise, it can be cost-prohibitive for many small businesses.
In this example figure, features are extracted from raw historical data, which are then are fed into a neural network (NN). Examples of other PBAs now available include AWS Inferentia and AWS Trainium , Google TPU, and Graphcore IPU. As shown in the preceding figure, the ML paradigm is learning (training) followed by inference.
and run inference: An AWS account that will contain all your AWS resources. Alternatively, you can deploy through the example notebook by choosing Open Notebook. This is a basic example of interacting with the SAM 2.1 The following examples for each of the tasks reference these operations without repeating them.
A common grade of service is 70% in 20 seconds however service level goals should take into account corporate objectives, market position, caller captivity, customer perceptions of the company, benchmarking surveys and what your competitors are doing. First Contact Resolution. Net Promoter Score.
For example, if a gamer mentions that their “skin didn’t load,” your team should know they’re not referring to clothing, but custom character designs. Techniques : AI Chatbots can resolve frequently asked questions like “How do I retrieve my account?” ” quickly and without human intervention.
If youre running this code using an Amazon SageMaker notebook instance, edit the IAM role thats attached to the notebook (for example, AmazonSageMaker-ExecutionRole-XXX) instead of creating a new role. The following table shows an example. Do not create a new AWS account, IAM user, or IAM group as part of those instructions.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content