This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Cohere Embed 3 makes it simple to locate specific UI mockups, visual templates, and presentation slides based on a text description. All text-to-image benchmarks are evaluated using Recall@5 ; text-to-text benchmarks are evaluated using NDCG@10. Generic text-to-image benchmark accuracy is based on Flickr and CoCo.
Overview of Pixtral 12B Pixtral 12B, Mistrals inaugural VLM, delivers robust performance across a range of benchmarks, surpassing other open models and rivaling larger counterparts, according to Mistrals evaluation. Performance metrics and benchmarks Pixtral 12B is trained to understand both natural images and documents, achieving 52.5%
This post explores these relationships via a comprehensive benchmarking of LLMs available in Amazon SageMaker JumpStart, including Llama 2, Falcon, and Mistral variants. We provide theoretical principles on how accelerator specifications impact LLM benchmarking. Additionally, models are fully sharded on the supported instance.
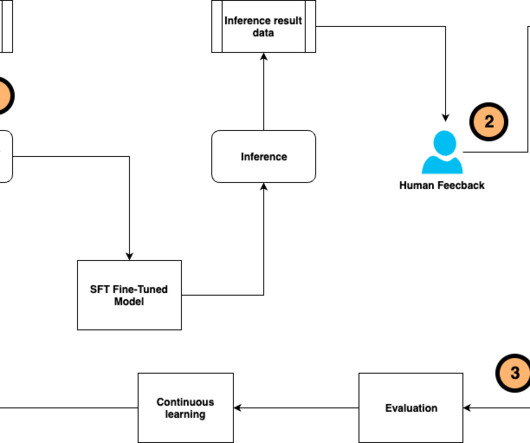
To address these challenges, we present an innovative continuous self-instruct fine-tuning framework that streamlines the LLM fine-tuning process of training data generation and annotation, model training and evaluation, human feedback collection, and alignment with human preference. Set up a SageMaker notebook instance.
Whenever I call Federal Express to arrange an outgoing shipment of Ron Kaufman books, tapes, videos and learning resources, FedEx already knows my name, address and account number … even before I tell them who is calling. When I call to make a reservation, they ask for my account or priority number each and every time.
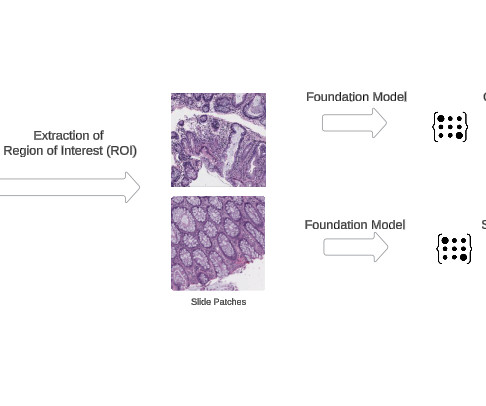
This sets a new benchmark for state-of-the-art performance in critical medical diagnostic tasks, from identifying cancerous cells to detecting genetic abnormalities in tumors. Prerequisites We assume you have access to and are authenticated in an AWS account. The AWS CloudFormation template for this solution uses t3.medium
Our recommendations are based on extensive experiments using public benchmark datasets across various vision-language tasks, including visual question answering, image captioning, and chart interpretation and understanding. Prerequisites To use this feature, make sure that you have satisfied the following requirements: An active AWS account.
To mitigate this challenge, thorough model evaluation, benchmarking, and data-aware optimization are essential, to compare the Amazon Nova models performance against the model used before the migration, and optimize the prompts on Amazon Nova to align performance with that of the previous workload or improve upon them.
Net Promoter Score (NPS) benchmarkingpresents an interesting challenge for many business leaders. Collectively, we have learned a lot through NPS benchmarking studies. Collectively, we have learned a lot through NPS benchmarking studies. Drawbacks of NPS Benchmarking. Understanding the Value of Net Promoter Score.
Accountability. The problem this presents is one of perception where “Our CX is failing, it’s time to turn it off” becomes an all too common occurrence. Present the facts, with an honest interpretation about what they mean for your business and encourage that message to move through your entire organisation.
By regularly asking these questions and keeping your team accountable, your onboarding process will grow alongside your customers. Then adjust and set benchmarks as customers work through those tasks, creating baselines that are easy to review in the future Ask: Where are most customers getting stuck during onboarding?
Accountability. The problem this presents is one of perception where “Our CX is failing, it’s time to turn it off” becomes an all too common occurrence. Present the facts, with an honest interpretation about what they mean for your business and encourage that message to move through your entire organisation.
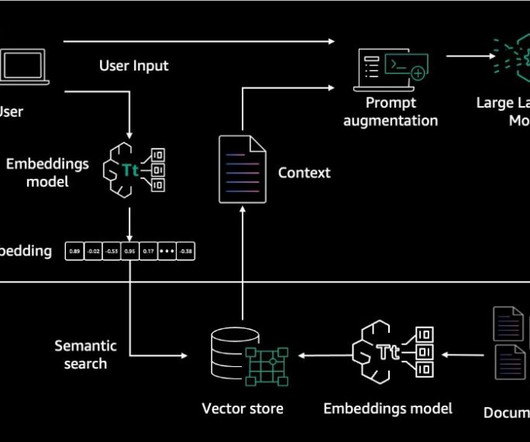
Here are some examples of these metrics: Retrieval component Context precision Evaluates whether all of the ground-truth relevant items present in the contexts are ranked higher or not. Evaluate RAG components with Foundation models We can also use a Foundation Model as a judge to compute various metrics for both retrieval and generation.
In this sense, CES can almost act as a gauge of how well a company is doing against its benchmarks and those of competitors. For SaaS products, consider questions like: “How easy was it to set up your account?” Determine Timing and Frequency Decide when to present surveys to customers.
The device further processes this response, including text-to-speech (TTS) conversion for voice agents, before presenting it to the user. Prerequisites To run this demo, complete the following prerequisites: Create an AWS account , if you dont already have one.
Here, we present our insights and top takeaways from The New 9 to 5: The State of CX in the Gig Economy – Customer Service Benchmark Report. and ‘I am unable to log in to my account,’ enabling faster support for gig economy players, who are always on the go. The Gig Economy + CX.
Next, we present the solution architecture and process flows for machine learning (ML) model building, deployment, and inferencing. Acting as a model hub, JumpStart provided a large selection of foundation models and the team quickly ran their benchmarks on candidate models. We end with lessons learned.
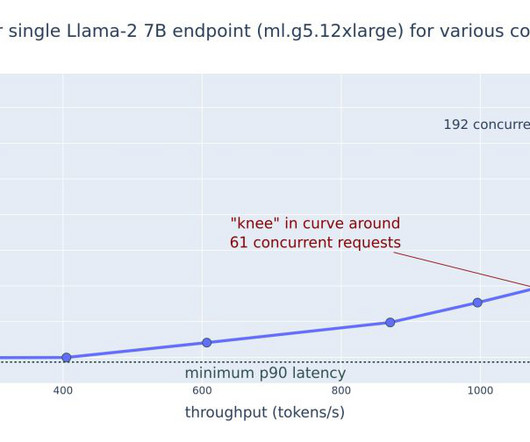
Prerequisites To run the example notebooks, you need an AWS account with an AWS Identity and Access Management (IAM) role with permissions to manage resources created. For details, refer to Create an AWS account. DeepSeek-R1-Distill-Llama-8B DeepSeek-R1-Distill-Llama-8B was benchmarked across ml.g5.2xlarge , ml.g5.12xlarge , ml.g6e.2xlarge
A recent AVANT “6-12” report focusing on CCaaS notes that the CCaaS market currently accounts for more than $3 billion in global sales. Cloud solutions boast high reliability and present very compelling arguments. Projections suggest that sales reach $10.5 billion by 2027. Why move to the cloud?
Our field organization includes customer-facing teams (account managers, solutions architects, specialists) and internal support functions (sales operations). Prospecting, opportunity progression, and customer engagement present exciting opportunities to utilize generative AI, using historical data, to drive efficiency and effectiveness.
With GraphStorm, you can build solutions that directly take into account the structure of relationships or interactions between billions of entities, which are inherently embedded in most real-world data, including fraud detection scenarios, recommendations, community detection, and search/retrieval problems. Dataset Num. of nodes Num.
We decided to stick with a straightforward intro-presentation-questions structure for this webinar. Sarah would introduced the webinar, introduce herself, Kayako and Jeanne, before handing over to Jeanne to start her presentation. At the end, Sarah would moderate an audience Q&A. We set some goals. We hoped for: 100 registrants.
Using these models, you too can learn how to go toe-to-toe with your Finance team by presenting trade-offs to get the headcount you need. In this article, we cover: Budgeting Benchmarks: Do They Cause More Harm than Good? Budgeting Benchmarks: Do They Cause More Harm than Good? Not exactly.
Presented in a step-by-step, interactive format, agent scripts built with Zingtree guide contact center reps through every step of a call, so they always know exactly what to say (and when to say it). Smitha obtained her license as CPA in 2007 from the California Board of Accountancy. This is even more critical for BPOs.
Lack of standardized benchmarks – There are no widely accepted and standardized benchmarks yet for holistically evaluating different capabilities of RAG systems. Without such benchmarks, it can be challenging to compare the various capabilities of different RAG techniques, models, and parameter configurations.
For SaaS B2B clients, QBR meetings tend to focus on assessing value as measured by KPI performance benchmarks. However, with today’s digital technology, scheduled QBRs may be supplemented by unscheduled reviews based on ongoing monitoring of customer account performance. Use Benchmarking Data. How Do I Prepare for a QBR?
As attendees circulate through the GAIZ, subject matter experts and Generative AI Innovation Center strategists will be on-hand to share insights, answer questions, present customer stories from an extensive catalog of reference demos, and provide personalized guidance for moving generative AI applications into production.
Presented by: Dave Kellogg , principal, Dave Kellogg Consulting. Presented by: Ryan Johansen , a stress management consultant who trains CS professionals on becoming top performers without burning out. With so much riding on this pivotal phase, you might feel inclined to custom-fit onboarding to each account.
And customer success departments can run business reviews with customers to look at how a product or platform is delivering on the business objectives they’re looking to solve, where benchmarks were not met, and discuss plans or changes for the future. Customer Business Review Tips and Tricks. Focus on delivery. . Want to learn more? .
The software service industry presents unique challenges for customer success management while also creating unique opportunities that call for specific strategies. SaaS success outcomes can be defined in terms of measurable digital benchmarks. Customer success in SaaS differs from CS in other industries.
has 92% accuracy on the HumanEval code benchmark. The dataframes may contain nans, so make sure you account for those in your code. - In other cases, we can’t reliably use an LLM to analyze tabular data, even when provided as structured format in the prompt. Put your the code in tags. -
Read Email Response Times: Benchmarks and Tips for Support for practical advice. Requiring customers to make a phone call to cancel or modify their account, when everything else can be done online, is infuriating. Tarek Khalil took to Twitter to document his quest to cancel his Baremetrics account. How Bare you?
Key performance indicators play a crucial role in assessing current value and setting future goals and benchmarks. Still, your KPI monitoring indicates that their account activity has dropped significantly below this level. The course of a QBR may cover: A review of previous goals and current performance.
If you go into a QBR focusing on the product, you can bet the executives present won’t be attending your next QBR, and that’s a huge missed opportunity. QBRs are your best tool to drive customer accountability. The golden rule for QBRs is to have the appropriate stakeholders present. What Are QBRs?
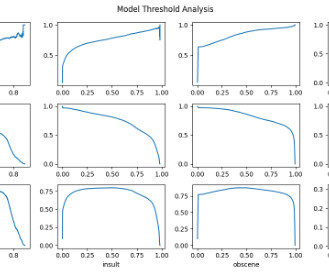
Solution overview This solution presents an approach to building an optimized custom classification model using Amazon Comprehend. We are using the max F1 score at the threshold as a benchmark to determine positive vs. negative for that label instead of a common benchmark (a standard value like > 0.7) for all the labels.
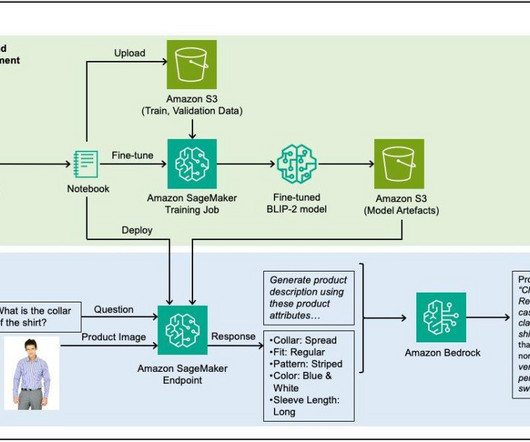
For details, see Creating an AWS account. Ensure sufficient capacity for this instance in your AWS account by requesting a quota increase if required. Conclusion We’ve shown you how the combination of VLMs on SageMaker and LLMs on Amazon Bedrock present a powerful solution for automating fashion product description generation.
At others, customer success specialists are accountable for managing churn and providing essential support. Generate trust and credibility at multiple levels in existing accounts after purchase and through the sales cycle. Experience managing accounts for a product that solves complex problems across many business units.
However, many businesses set up social media accounts without a clear strategy and randomly post content without tracking growth or results over time. The goal is to understand the health and performance of all social accounts to maximize their effectiveness. The audit gives you benchmarks to compare against in future analysis.
Both Inferentia2 and Trainium use the same basic components, but with differing layouts, accounting for the different workloads they are designed to support. Accelerator benchmarking When considering compute services, users benchmark measures such as price-performance, absolute performance, availability, latency, and throughput.
The typical ESG workflow consists of multiple phases, each presenting unique pain points. Consider the following guidelines: Implement real-time monitoring – Set up monitoring systems to track generative AI performance against sustainability benchmarks, focusing on efficiency and environmental impact.
Actually, according to the 2018 Customer Service Benchmark report , the average live chat response time is just two minutes, whereas the average response time for an email is 12 hours. When replying to any question or inquiry, be conscious of how you are presenting your responses. Give me one moment to pull your account up.
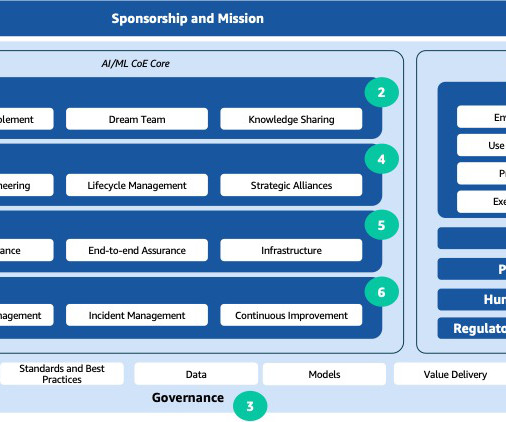
By taking a proactive approach , the CoE provides ethical compliance but also builds trust, enhances accountability, and mitigates potential risks such as veracity, toxicity, data misuse, and intellectual property concerns. Platform – A central platform such as Amazon SageMaker for creation, training, and deployment.
These include metrics such as ROUGE or cosine similarity for text similarity, and specific benchmarks for assessing toxicity (Detoxify), prompt stereotyping (cross-entropy loss), or factual knowledge (HELM, LAMA). The agent went over the details and presented the steps along necessary along with the documentation links.
With state-of-the-art vision capabilities and strong performance on industry benchmarks, Anthropic Claude 3 Haiku is a versatile solution for a wide range of enterprise applications. Prerequisites For this walkthrough, you need the following: An AWS account. You can deploy this solution following the steps in this post. Choose “t3.small”
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content