This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
I’ve been reading about BigData’s foray into “Journey Analytics.” Journey analytics seeks to improve customer experience by collecting data at each point on a customer’s journey and mapping customers’ paths – whether they lead to a purchase or not. And linking data points throughout a journey is a step in the right direction.
If you aren’t sure this is true, then ask yourself: would I open a Yahoo email account today? It’s because 500 million of Yahoo’s account users’ names, email addresses, telephone numbers, birth dates, scrambled passwords, and security questions are in the wind. Yahoo’s new email account set up is also quiet today.
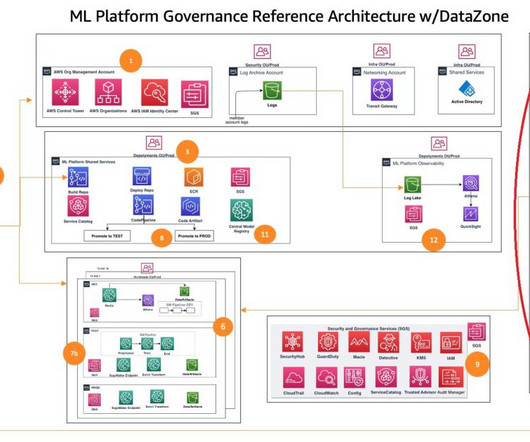
This post dives deep into how to set up data governance at scale using Amazon DataZone for the data mesh. The data mesh is a modern approach to data management that decentralizes data ownership and treats data as a product.
He shares how organizations can use data and AI-powered tools to benefit customers. And why doesn’t the email system know if a Notice of Cancellation is in effect for my account? The communications people who wrote this email need to get with the data scientists and customer representatives to create better targeting.
An effective PM solution sources data from all contact center systems through standardized integrations and merges the data (so handle times for Agent 1 from the ACD can be tied to interaction quality for Agent 1 from Quality Management, for example).
The solution integrates large language models (LLMs) with your organization’s data and provides an intelligent chat assistant that understands conversation context and provides relevant, interactive responses directly within the Google Chat interface. A Business or Enterprise Google Workspace account with access to Google Chat.
Whether you realize it or not, bigdata is at the heart of practically everything we do today. In today’s smart, digital world, bigdata has opened the floodgates to never-before-seen possibilities. As companies move forward in today’s age of rapid tech innovation, they must be armed with the right data strategy.
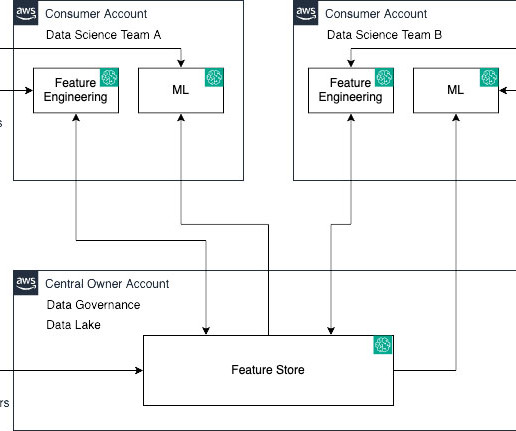
SageMaker Feature Store now makes it effortless to share, discover, and access feature groups across AWS accounts. With this launch, account owners can grant access to select feature groups by other accounts using AWS Resource Access Manager (AWS RAM).
I’m capitalizing the first letter of each word because the pervasiveness of digital transformation has all the feel of BigData a few years ago and Reeingineering in the 1990’s. Much of the digital transformation emphasis has been on technology (bigdata analytics and cloud, mobile apps, etc.) Brand Equity.
While these models are trained on vast amounts of generic data, they often lack the organization-specific context and up-to-date information needed for accurate responses in business settings. After ingesting the data, you create an agent with specific instructions: agent_instruction = """You are the Amazon Bedrock Agent.
BigData and Its Impact on Live Betting Bigdata is one form of technology that bookmakers have used for as long as it’s been available. Of course, technology has significantly improved the way that bigdata analysis is conducted, which has allowed the live betting niche to continue to grow and push forward.
Twilio enables companies to use communications and data to add intelligence and security to every step of the customer journey, from sales and marketing to growth, customer service, and many more engagement use cases in a flexible, programmatic way. Data is the foundational layer for all generative AI and ML applications.
By using social accounts for addressing all kinds of customer queries, companies are expanding their customer experience strategy. . Brands like Starbucks use their parent Twitter account to address complaints and generally talk to customers. Netflix has a dedicated Twitter account called NetflixHelps to respond to customer complaints.
To develop models for such use cases, data scientists need access to various datasets like credit decision engines, customer transactions, risk appetite, and stress testing. Managing appropriate access control for these datasets among the data scientists working on them is crucial to meet stringent compliance and regulatory requirements.
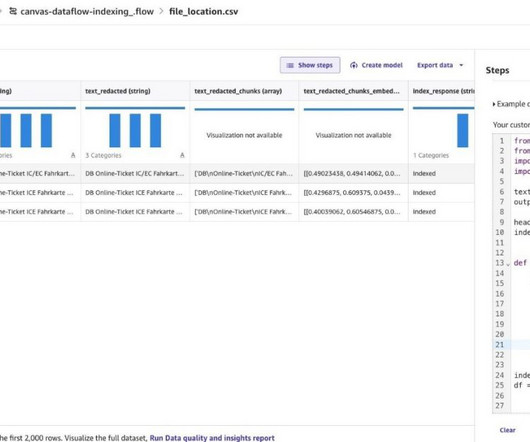
Data preparation is a crucial step in any machine learning (ML) workflow, yet it often involves tedious and time-consuming tasks. Amazon SageMaker Canvas now supports comprehensive data preparation capabilities powered by Amazon SageMaker Data Wrangler. To import data from Snowflake, follow steps from Set up OAuth for Snowflake.
Harnessing the power of bigdata has become increasingly critical for businesses looking to gain a competitive edge. However, managing the complex infrastructure required for bigdata workloads has traditionally been a significant challenge, often requiring specialized expertise.
Authored by Daniel Fenton , Director, Enterprise Accounts and Molly Clark , Senior Director, Operational Analytics. Leveraging data analytics to improve FCR rates is critical for achieving this objective. Northridge’s data-driven Root Cause Analysis process. Has the customer called in the past from a different phone number?
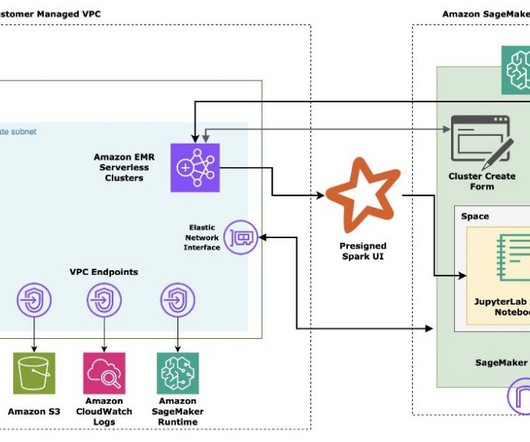
Amazon SageMaker Data Wrangler reduces the time it takes to collect and prepare data for machine learning (ML) from weeks to minutes. Data is frequently kept in data lakes that can be managed by AWS Lake Formation , giving you the ability to implement fine-grained access control using a straightforward grant or revoke procedure.
They immediately requested the account number from both. We discuss how Kenneth Cukier’s TED talk about “BigData is Better Data ” and how having data isn’t enough to predict how people will interpret it. Despite this, the mobile company treated both types of customers in the same way.
For context, these are the customers who continue to buy from you over and over again, and should account for the majority of your total sales. Years ago, the term “BigData” became popular. I came up with the concept of “Micro Data,” which is about very personalized information about a smaller set of customers.
In this blog post, we demonstrate prompt engineering techniques to generate accurate and relevant analysis of tabular data using industry-specific language. This is done by providing large language models (LLMs) in-context sample data with features and labels in the prompt.
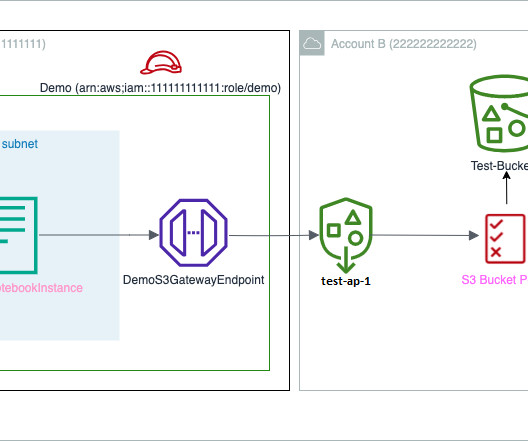
On August 9, 2022, we announced the general availability of cross-account sharing of Amazon SageMaker Pipelines entities. You can now use cross-account support for Amazon SageMaker Pipelines to share pipeline entities across AWS accounts and access shared pipelines directly through Amazon SageMaker API calls. Solution overview.
The LLM can then use its extensive knowledge base, which can be regularly updated with the latest medical research and clinical trial data, to provide relevant and trustworthy responses tailored to the patients specific situation. Extraction of relevant data points for electronic health records (EHRs) and clinical trial databases.
However, these models require massive amounts of clean, structured training data to reach their full potential. Most real-world data exists in unstructured formats like PDFs, which requires preprocessing before it can be used effectively. According to IDC , unstructured dataaccounts for over 80% of all business data today.
Whilst emotions are important and account for over 50% of a Customer Experience, understanding how to stimulate and evoke emotions at the subconscious and psychological level is the latest thought leadership in our field. Bigdata can be used to research past behavior. Thirteen years is a long time to be considered a madman!
Customer service needs customer data. John Rampton, entrepreneur and investor, defines single customer view as: ❝…an accessible and consistent set of information about how a customer has interacted with your company, including what they have bought, their personal data, opinions, and feedback.❞. Challenges to achieving SCV.
In this post, we show how to configure a new OAuth-based authentication feature for using Snowflake in Amazon SageMaker Data Wrangler. Snowflake is a cloud data platform that provides data solutions for data warehousing to data science. For more information about prerequisites, see Get Started with Data Wrangler.
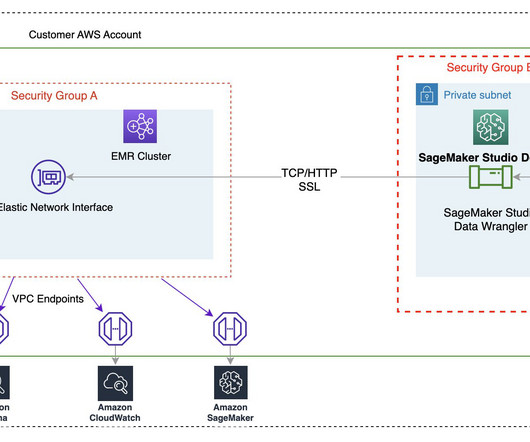
These customers need to balance governance, security, and compliance against the need for machine learning (ML) teams to quickly access their data science environments in a secure manner. One important aspect of this foundation is to organize their AWS environment following a multi-account strategy.
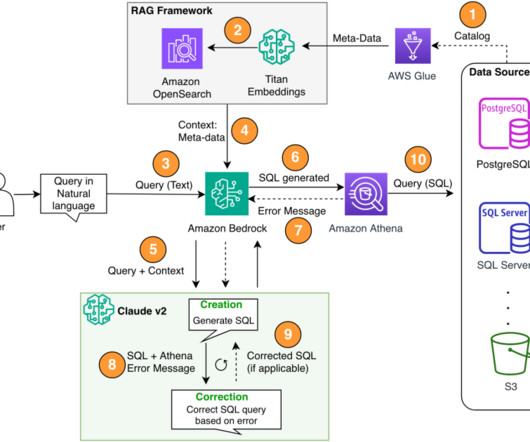
Amazon DataZone is a data management service that makes it quick and convenient to catalog, discover, share, and govern data stored in AWS, on-premises, and third-party sources. However, ML governance plays a key role to make sure the data used in these models is accurate, secure, and reliable.
The solution in this post aims to bring enterprise analytics operations to the next level by shortening the path to your data using natural language. Second, you might need to build text-to-SQL features for every database because data is often not stored in a single target. We use Anthropic Claude v2.1 on Amazon Bedrock as our LLM.
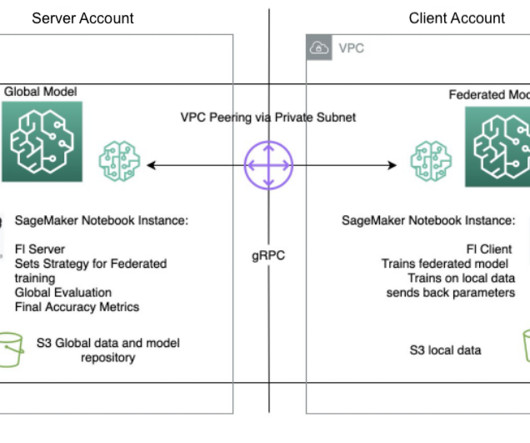
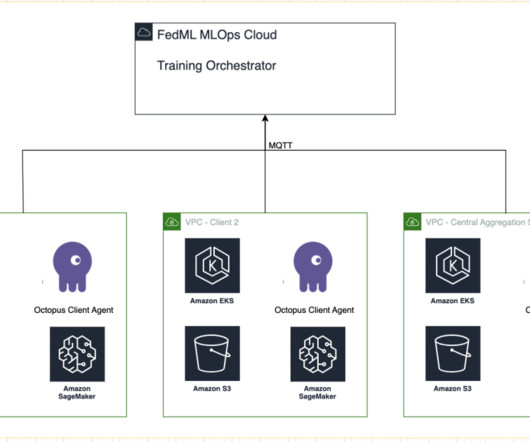
Machine learning (ML) is revolutionizing solutions across industries and driving new forms of insights and intelligence from data. Many ML algorithms train over large datasets, generalizing patterns it finds in the data and inferring results from those patterns as new unseen records are processed. What is federated learning?
With the Amazon Bedrock serverless experience, you can quickly get started, easily experiment with FMs, privately customize them with your own data, and seamlessly integrate and deploy them into your applications using AWS tools and capabilities.
Whilst emotions are important and account for over 50% of a Customer Experience, understanding how to stimulate and evoke emotions at the subconscious and psychological level is the latest thought leadership in our field. Bigdata can be used to research past behavior. Thirteen years is a long time to be considered a madman!
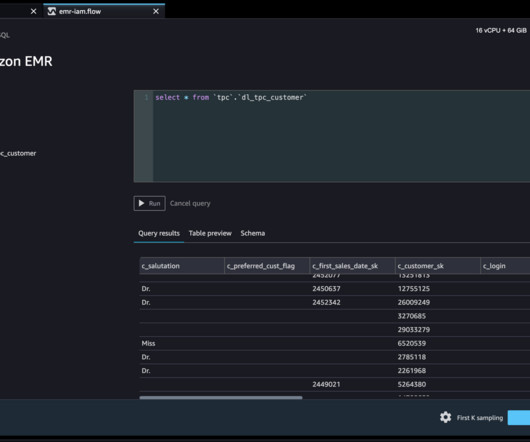
Amazon SageMaker Data Wrangler reduces the time it takes to aggregate and prepare data for machine learning (ML) from weeks to minutes in Amazon SageMaker Studio. Starting today, you can connect to Amazon EMR Hive as a bigdata query engine to bring in large datasets for ML.
Many other sensors and data sources will probably also be routed to PSAPs, such as LPR, gunshot detection, hazmat alerts, weather alerts, telematics, and even social media. While these sources of BigData hold a lot of promise, they will create major challenges too. for a complete evidentiary record.
Oxford defines “bigdata” as “extremely large data sets that may be analyzed computationally to reveal patterns, trends, and associations, especially relating to human behavior and interactions.” Bigdata is of special interest to businesses that wish to gauge their consumers’ preferences and ideas regarding customer service.
With increased access to data, ML has the potential to provide unparalleled business insights and opportunities. To address this issue, federated learning (FL) is a decentralized and collaborative ML training technique that offers data privacy while maintaining accuracy and fidelity.
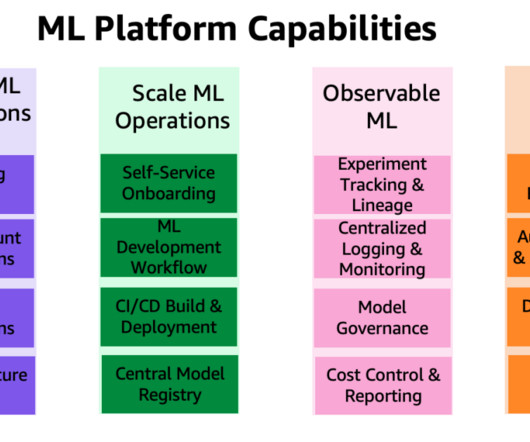
Data underpins ML and AI use cases and is a strategic asset to an organization. As data is growing at an exponential rate, organizations are looking to set up an integrated, cost-effective, and performant data platform in order to preprocess data, perform feature engineering, and build, train, and operationalize ML models at scale.
In the world of SaaS, there certainly isn’t a lack of data – bigdata, small data – all of that data! Even though you’ll have the data (after spending a considerable amount of time collecting it), it still won’t provide the complete picture. Support tickets. Adoption rate.
They serve as a bridge between IT and other business functions, making data-driven recommendations that meet business requirements and improve processes while optimizing costs. Business analysts must own the call tracking systems and actively leverage data to tune the call center policies and procedures. Andrew Tillery. MAPCommInc.
Bigdata and analytics, with how they will impact predictive modelling and the marketing mix. Following on from the opportunities of BigData, the next concern is Marketing Accountability and its ROI. Knowing what to do with data. TIER TWO: The other concerns. Engaging customers. Acquiring new skills.
However, implementing security, data privacy, and governance controls are still key challenges faced by customers when implementing ML workloads at scale. These companies also recognize the need for governance to manage things like access control, data usage, model performance, and unfair bias.
Additionally, Knowledge Bases for Amazon Bedrock empowers you to develop applications that harness the power of Retrieval Augmented Generation (RAG), an approach where retrieving relevant information from data sources enhances the model’s ability to generate contextually appropriate and informed responses. A data source in Amazon S3.
Make sure to validate prompt input data and prompt input size for allocated character limits that are defined by your model. If you’re performing prompt engineering, you should persist your prompts to a reliable data store. In the batch case, there are a couple challenges compared to typical data pipelines.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content