This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
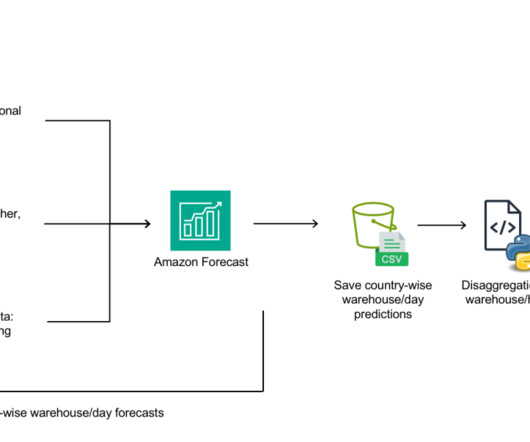
Challenges in data management Traditionally, managing and governing data across multiple systems involved tedious manual processes, custom scripts, and disconnected tools. The diagram shows several accounts and personas as part of the overall infrastructure. The following diagram gives a high-level illustration of the use case.
We recently announced the general availability of cross-account sharing of Amazon SageMaker Model Registry using AWS Resource Access Manager (AWS RAM) , making it easier to securely share and discover machine learning (ML) models across your AWS accounts. Mitigation strategies : Implementing measures to minimize or eliminate risks.
About the Authors Dheer Toprani is a System Development Engineer within the Amazon Worldwide Returns and ReCommerce Data Services team. Chaithanya Maisagoni is a Senior Software Development Engineer (AI/ML) in Amazons Worldwide Returns and ReCommerce organization.
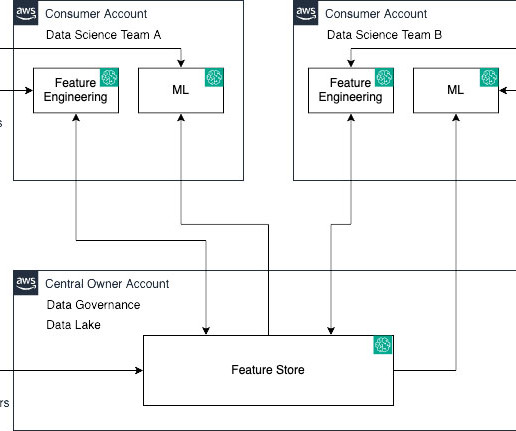
SageMaker Feature Store now makes it effortless to share, discover, and access feature groups across AWS accounts. With this launch, account owners can grant access to select feature groups by other accounts using AWS Resource Access Manager (AWS RAM).
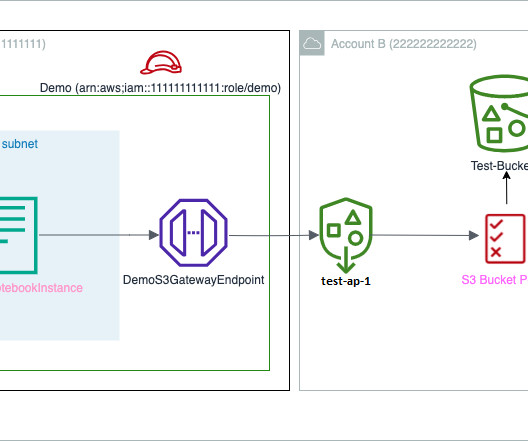
To develop models for such use cases, data scientists need access to various datasets like credit decision engines, customer transactions, risk appetite, and stress testing. Amazon S3 Access Points simplify managing and securing data access at scale for applications using shared datasets on Amazon S3.
In this blog post, we demonstrate prompt engineering techniques to generate accurate and relevant analysis of tabular data using industry-specific language. This is done by providing large language models (LLMs) in-context sample data with features and labels in the prompt. As we can see the data retrieval is more accurate.
Our initial approach combined prompt engineering and traditional Retrieval Augmented Generation (RAG). For more information about how to work with RDC and AWS and to understand how were supporting banking customers around the world to use AI in credit decisions, contact your AWS Account Manager or visit Rich Data Co.
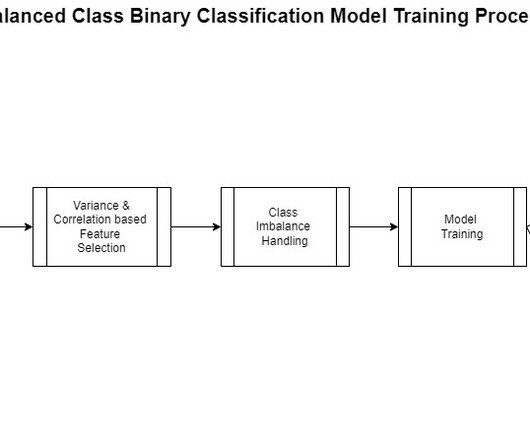
This includes gathering, exploring, and understanding the business and technical aspects of the data, along with evaluation of any manipulations that may be needed for the model building process. One aspect of this data preparation is feature engineering. However, generalizing feature engineering is challenging.
Harnessing the power of bigdata has become increasingly critical for businesses looking to gain a competitive edge. However, managing the complex infrastructure required for bigdata workloads has traditionally been a significant challenge, often requiring specialized expertise.
Whether you realize it or not, bigdata is at the heart of practically everything we do today. In today’s smart, digital world, bigdata has opened the floodgates to never-before-seen possibilities. To effectively apply your data, you must first determine what you wish to achieve with your data in the first place.
As data is growing at an exponential rate, organizations are looking to set up an integrated, cost-effective, and performant data platform in order to preprocess data, perform feature engineering, and build, train, and operationalize ML models at scale. In this post, we demonstrate how to implement this solution.
On August 9, 2022, we announced the general availability of cross-account sharing of Amazon SageMaker Pipelines entities. You can now use cross-account support for Amazon SageMaker Pipelines to share pipeline entities across AWS accounts and access shared pipelines directly through Amazon SageMaker API calls. Solution overview.
The principles include regulatory compliance, maintaining data provenance and reliability, incorporating human oversight via human-in-the-loop, inclusivity and diversity in data usage and algorithm adoption, responsibility and accountability, and digital education and communicative transparency.
For context, these are the customers who continue to buy from you over and over again, and should account for the majority of your total sales. Years ago, the term “BigData” became popular. I came up with the concept of “Micro Data,” which is about very personalized information about a smaller set of customers.
ASR and NLP techniques provide accurate transcription, accounting for factors like accents, background noise, and medical terminology. Text data integration The transcribed text data is integrated with other sources of adverse event reporting, such as electronic case report forms (eCRFs), patient diaries, and medication logs.
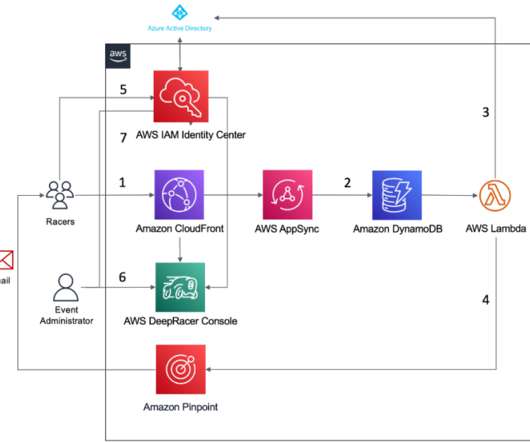
Until recently, organizations hosting private AWS DeepRacer events had to create and assign AWS accounts to every event participant. This often meant securing and monitoring usage across hundreds or even thousands of AWS accounts. Build a solution around AWS DeepRacer multi-user account management. Conclusion.
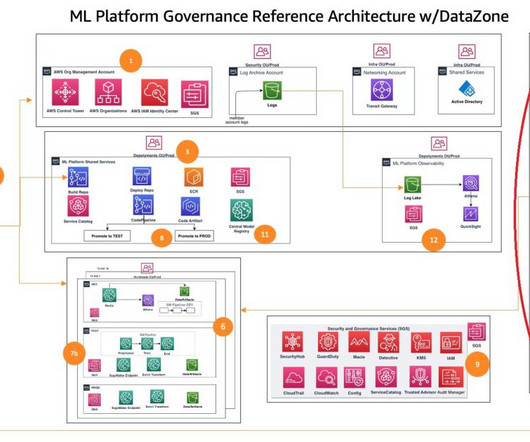
One important aspect of this foundation is to organize their AWS environment following a multi-account strategy. In this post, we show how you can extend that architecture to multiple accounts to support multiple LOBs. In this post, we show how you can extend that architecture to multiple accounts to support multiple LOBs.
This framework addresses challenges by providing prescriptive guidance through a modular framework approach extending an AWS Control Tower multi-account AWS environment and the approach discussed in the post Setting up secure, well-governed machine learning environments on AWS.
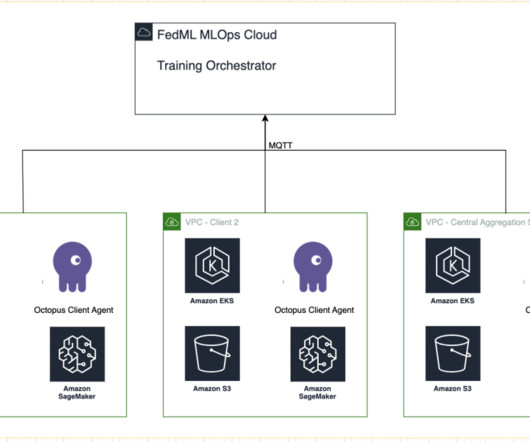
Healthcare organizations must navigate strict compliance regulations, such as the Health Insurance Portability and Accountability Act (HIPAA) in the United States, while implementing FL solutions. FedML Octopus is the industrial-grade platform of cross-silo FL for cross-organization and cross-account training.
Users typically reach out to the engineering support channel when they have questions about data that is deeply embedded in the data lake or if they can’t access it using various queries. Having an AI assistant can reduce the engineering time spent in responding to these queries and provide answers more quickly.
There are unique considerations when engineering generative AI workloads through a resilience lens. Make sure to validate prompt input data and prompt input size for allocated character limits that are defined by your model. If you’re performing prompt engineering, you should persist your prompts to a reliable data store.
Whether your HR department needs a Q&A workflow for employee benefits, your legal team needs a contract redlining solution, or your analysts need a research report analysis engine, Agent Creator provides the tools and flexibility to build it all. He currently is working on Generative AI for data integration.
In this post, we describe how we reduced the modelling time by 70% by doing the feature engineering and modelling using Amazon Forecast. SARIMA extends ARIMA by incorporating additional parameters to account for seasonality in the time series. The Amazon Forecast models were eventually selected for the algorithmic modeling segment.
The Amazon Bedrock VPC endpoint powered by AWS PrivateLink allows you to establish a private connection between the VPC in your account and the Amazon Bedrock service account. Use the following template to create the infrastructure stack Bedrock-GenAI-Stack in your AWS account. With an M.Sc.
To overcome this, enterprises needs to shape a clear operating model defining how multiple personas, such as data scientists, dataengineers, ML engineers, IT, and business stakeholders, should collaborate and interact; how to separate the concerns, responsibilities, and skills; and how to use AWS services optimally.
Prerequisites You need an AWS account and an AWS Identity and Access Management (IAM) role and user with permissions to create and manage the necessary resources and components for this application. If you don’t have an AWS account, see How do I create and activate a new Amazon Web Services account?
Using BigData to Make Leadership Advances in the Workplace. Keeps people accountable to their shifts. Efforts helped Best Buy crimp employee turnover “well into the double digits,” Timothy Embretson, director of retail user experience told the attendees at the Future Stores Miami conference in February of 2018.
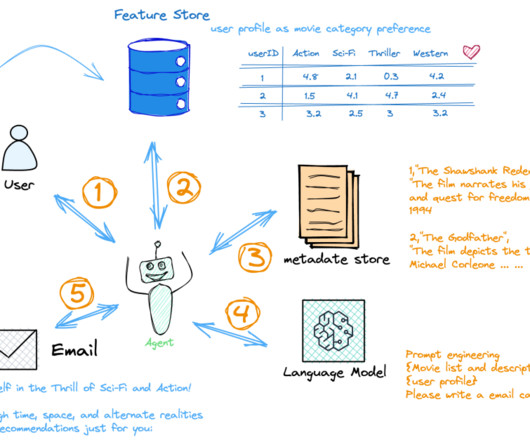
Large language models (LLMs) are revolutionizing fields like search engines, natural language processing (NLP), healthcare, robotics, and code generation. Another essential component is an orchestration tool suitable for prompt engineering and managing different type of subtasks. A feature store maintains user profile data.
In addition to dataengineers and data scientists, there have been inclusions of operational processes to automate & streamline the ML lifecycle. Depending on your governance requirements, Data Science & Dev accounts can be merged into a single AWS account.
Reviewing the Account Balance chatbot. As an example, this demo deploys a bot to perform three automated tasks, or intents : Check Balance , Transfer Funds , and Open Account. For example, the Open Account intent includes four slots: First Name. Account Type. Complete the following steps: Log in to your AWS account.
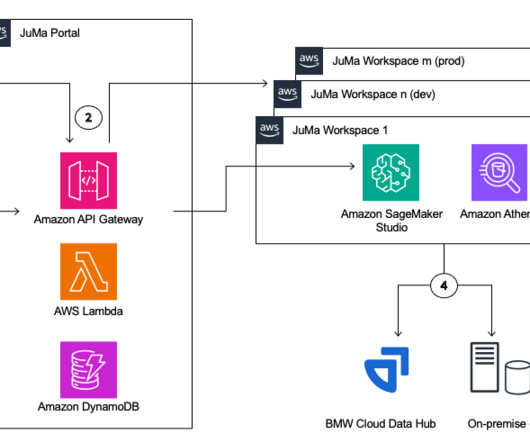
With that, the need for data scientists and machine learning (ML) engineers has grown significantly. Data scientists and ML engineers require capable tooling and sufficient compute for their work. JuMa is now available to all data scientists, ML engineers, and data analysts at BMW Group.
Amazon DataZone allows you to create and manage data zones , which are virtual data lakes that store and process your data, without the need for extensive coding or infrastructure management. The data publisher is responsible for publishing and governing access for the bespoke data in the Amazon DataZone business data catalog.
With SageMaker Processing jobs, you can use a simplified, managed experience to run data preprocessing or postprocessing and model evaluation workloads on the SageMaker platform. Twilio needed to implement an MLOps pipeline that queried data from PrestoDB. Follow the instructions in the GitHub README.md
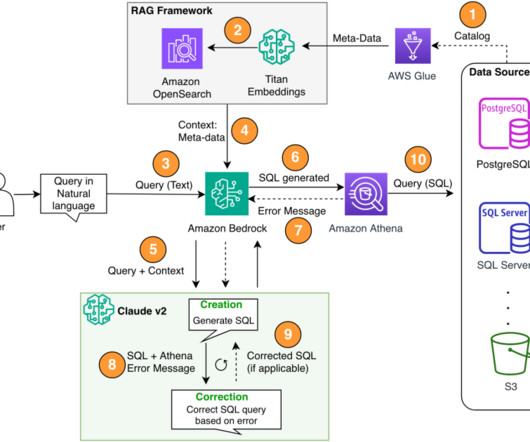
To address the challenges, our solution first incorporates the metadata of the data sources within the AWS Glue Data Catalog to increase the accuracy of the generated SQL query. Athena also allows us to use a multitude of supported endpoints and connectors to cover a large set of data sources. Set up the SDK for Python (Boto3).
Amazon SageMaker Data Wrangler reduces the time it takes to collect and prepare data for machine learning (ML) from weeks to minutes. In this post, we show how to use Lake Formation as a central data governance capability and Amazon EMR as a bigdata query engine to enable access for SageMaker Data Wrangler.
In our entire partnership, AWS has set the bar on customer obsession and delivering results—working with us the whole way to realize promised benefits.” – Keshav Kumar, Head of Engineering at BigBasket. About the Authors Santosh Waddi is a Principal Engineer at BigBasket, brings over a decade of expertise in solving AI challenges.
The workflow steps are as follows: Set up a SageMaker notebook and an AWS Identity and Access Management (IAM) role with appropriate permissions to allow SageMaker to access Amazon Elastic Container Registry (Amazon ECR), Secrets Manager, and other services within your AWS account. Ingest the data in a table in your Snowflake account.
As feature data grows in size and complexity, data scientists need to be able to efficiently query these feature stores to extract datasets for experimentation, model training, and batch scoring. The offline store data is stored in an Amazon Simple Storage Service (Amazon S3) bucket in your AWS account. Conclusion.
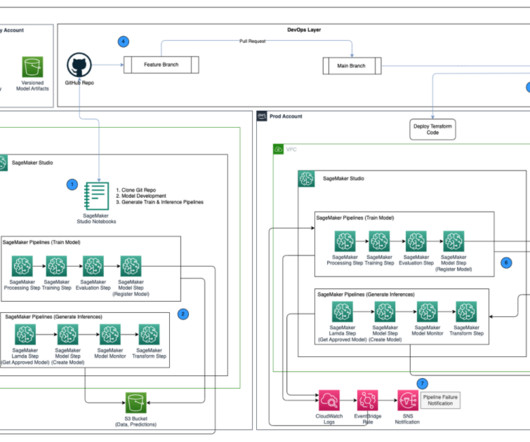
Central model registry – Amazon SageMaker Model Registry is set up in a separate AWS account to track model versions generated across the dev and prod environments. Approve the model in SageMaker Model Registry in the central model registry account. Create a pull request to merge the code into the main branch of the GitHub repository.
However, these models require massive amounts of clean, structured training data to reach their full potential. Most real-world data exists in unstructured formats like PDFs, which requires preprocessing before it can be used effectively. According to IDC , unstructured dataaccounts for over 80% of all business data today.
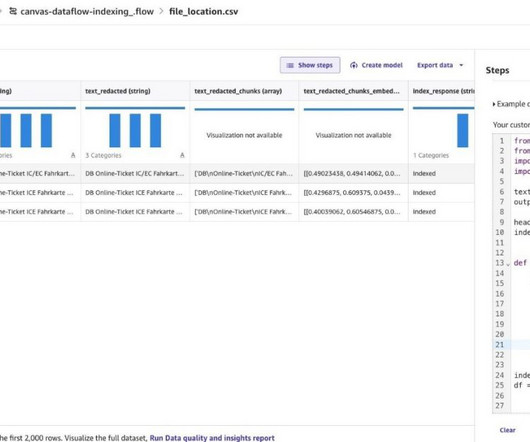
The no-code environment of SageMaker Canvas allows us to quickly prepare the data, engineer features, train an ML model, and deploy the model in an end-to-end workflow, without the need for coding. From the Import data page, select Snowflake from the list and choose Add connection. Huong Nguyen is a Sr.
This enables data scientists to quickly build and iterate on ML models, and empowers ML engineers to run through continuous integration and continuous delivery (CI/CD) ML pipelines faster, decreasing time to production for models. Jinzhao Feng , is a Machine Learning Engineer at AWS Professional Services.
According to Accenture , Millennials have overtaken Baby Boomers as the largest consumer demographic, expected to account for 30% of retail sales — that’s $1.4 With bigdata and advanced analytics readily available, companies can provide Millennials with the acknowledgement they demand. Pay attention.
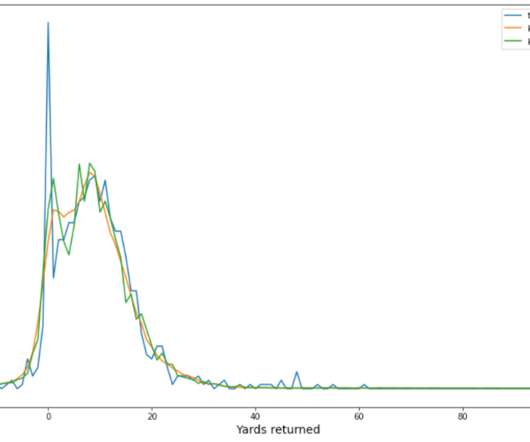
The data distribution for punt and kickoff are different. Data preprocessing and feature engineering First, the tracking data was filtered for just the data related to punts and kickoff returns. As a baseline, we used the model that won our NFL BigData Bowl competition on Kaggle.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



































Let's personalize your content