This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
An AWS account and an AWS Identity and Access Management (IAM) principal with sufficient permissions to create and manage the resources needed for this application. If you don’t have an AWS account, refer to How do I create and activate a new Amazon Web Services account? The script deploys the AWS CDK project in your account.
To test it, you can ask a question that isnt present in the agents knowledge base, making the LLM either refuse to answer or hallucinate. The Amazon Bedrock agent answers the question correctly using the cached answer even though the information is not present in the agent knowledge base. ms, sys: 0 ns, total: 10.4
We recently announced the general availability of cross-account sharing of Amazon SageMaker Model Registry using AWS Resource Access Manager (AWS RAM) , making it easier to securely share and discover machine learning (ML) models across your AWS accounts. Mitigation strategies : Implementing measures to minimize or eliminate risks.
Whether you realize it or not, bigdata is at the heart of practically everything we do today. In today’s smart, digital world, bigdata has opened the floodgates to never-before-seen possibilities. To effectively apply your data, you must first determine what you wish to achieve with your data in the first place.
Answer: 1 Please provide an analysis and interpretation of the results to answer the original {question}. """ } ] We see that with additional prompting the model uses all of the volatility columns in the dataset (1-year, 3-year, and 5-year) and provides output suggestions for when data is present or missing in the volatility columns.
On August 9, 2022, we announced the general availability of cross-account sharing of Amazon SageMaker Pipelines entities. You can now use cross-account support for Amazon SageMaker Pipelines to share pipeline entities across AWS accounts and access shared pipelines directly through Amazon SageMaker API calls. Solution overview.
ASR and NLP techniques provide accurate transcription, accounting for factors like accents, background noise, and medical terminology. Text data integration The transcribed text data is integrated with other sources of adverse event reporting, such as electronic case report forms (eCRFs), patient diaries, and medication logs.
Harnessing the power of bigdata has become increasingly critical for businesses looking to gain a competitive edge. However, managing the complex infrastructure required for bigdata workloads has traditionally been a significant challenge, often requiring specialized expertise.
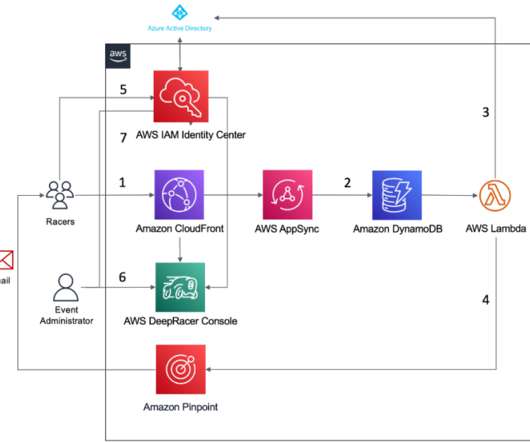
Until recently, organizations hosting private AWS DeepRacer events had to create and assign AWS accounts to every event participant. This often meant securing and monitoring usage across hundreds or even thousands of AWS accounts. Build a solution around AWS DeepRacer multi-user account management. Conclusion.
However, the journey from production-ready solutions to full-scale implementation can present distinct operational and technical considerations. For more information, you can watch the AWS Summit Milan 2024 presentation. Subhro Bose is a Data Architect in Emergent Technologies and Intelligence Platform in Amazon.
A 2015 Capgemini and EMC study called “Big & Fast Data: The rise of Insight-Driven Business” showed that: 56% of the 1,000 senior decision makers surveyed claim that their investment in bigdata over the next three years will exceed past investment in information management.
A 2015 Capgemini and EMC study called “Big & Fast Data: The rise of Insight-Driven Business” showed that: 56% of the 1,000 senior decision makers surveyed claim that their investment in bigdata over the next three years will exceed past investment in information management.
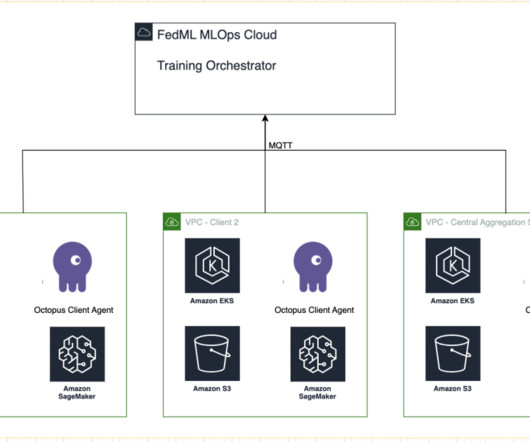
Healthcare organizations must navigate strict compliance regulations, such as the Health Insurance Portability and Accountability Act (HIPAA) in the United States, while implementing FL solutions. FedML Octopus is the industrial-grade platform of cross-silo FL for cross-organization and cross-account training.
Oxford defines “bigdata” as “extremely large data sets that may be analyzed computationally to reveal patterns, trends, and associations, especially relating to human behavior and interactions.” Bigdata is of special interest to businesses that wish to gauge their consumers’ preferences and ideas regarding customer service.
Today, CXA encompasses various technologies such as AI, machine learning, and bigdata analytics to provide personalized and efficient customer experiences. Over time, additional interactive solutions like IVR systems added the ability to automate basic queries like account balances or simple troubleshooting.
Reviewing the Account Balance chatbot. As an example, this demo deploys a bot to perform three automated tasks, or intents : Check Balance , Transfer Funds , and Open Account. For example, the Open Account intent includes four slots: First Name. Account Type. Complete the following steps: Log in to your AWS account.
Ingesting from these sources is different from the typical data sources like log data in an Amazon Simple Storage Service (Amazon S3) bucket or structured data from a relational database. In the low-latency case, you need to account for the time it takes to generate the embedding vectors.
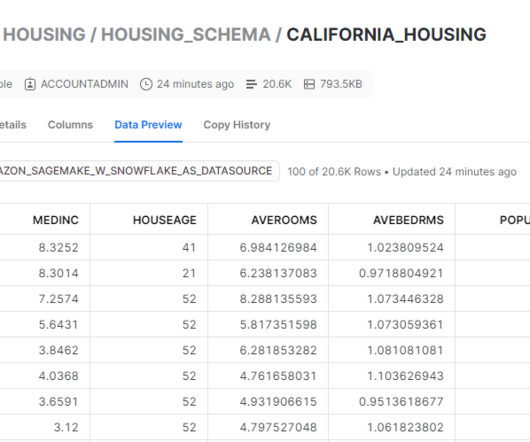
It also provides common ML algorithms that are optimized to run efficiently against extremely large data in a distributed environment. Store your Snowflake account credentials in AWS Secrets Manager. Ingest the data in a table in your Snowflake account. Launch a SageMaker Training job for training the ML model.
This framework addresses challenges by providing prescriptive guidance through a modular framework approach extending an AWS Control Tower multi-account AWS environment and the approach discussed in the post Setting up secure, well-governed machine learning environments on AWS.
According to Accenture , Millennials have overtaken Baby Boomers as the largest consumer demographic, expected to account for 30% of retail sales — that’s $1.4 With bigdata and advanced analytics readily available, companies can provide Millennials with the acknowledgement they demand. Pay attention.
A multi-account strategy is essential not only for improving governance but also for enhancing security and control over the resources that support your organization’s business. In this post, we dive into setting up observability in a multi-account environment with Amazon SageMaker.
In this post, we present a framework for automating the creation of a directed acyclic graph (DAG) for Amazon SageMaker Pipelines based on simple configuration files. The framework code and examples presented here only cover model training pipelines, but can be readily extended to batch inference pipelines as well.
Athena also allows us to use a multitude of supported endpoints and connectors to cover a large set of data sources. After we walk through the steps to build the solution, we present the results of some test scenarios with varying SQL complexity levels. Here, the output is presented to the user.
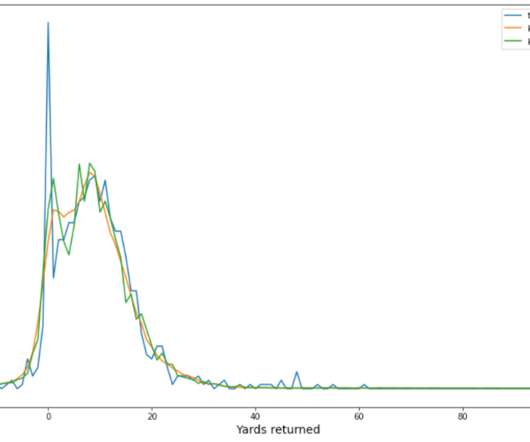
Next, we present the data preprocessing and other transformation methods applied to the dataset. Finally, we present the model performance results. The data preprocessing and feature engineering was adapted from the winner of the NFL BigData Bowl competition on Kaggle. We first describe the dataset used.
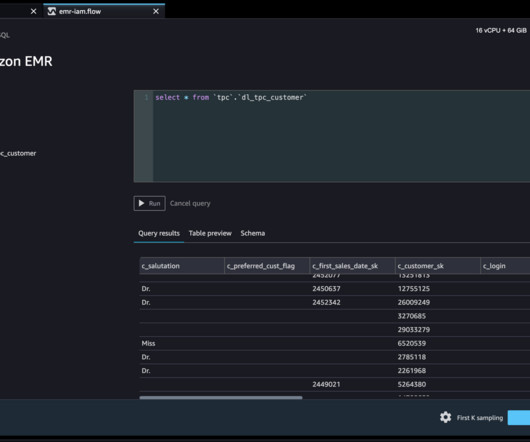
In this post, we show how to use Lake Formation as a central data governance capability and Amazon EMR as a bigdata query engine to enable access for SageMaker Data Wrangler. Solution overview We demonstrate this solution with an end-to-end use case using a sample dataset, the TPC data model.
We begin by understanding the feature columns, presented in the following table. To learn more about importing data to SageMaker Canvas, see Import data into Canvas. Choose Import data , then choose Tabular. After a successful import, you will be presented with a preview of the data, which you can browse.
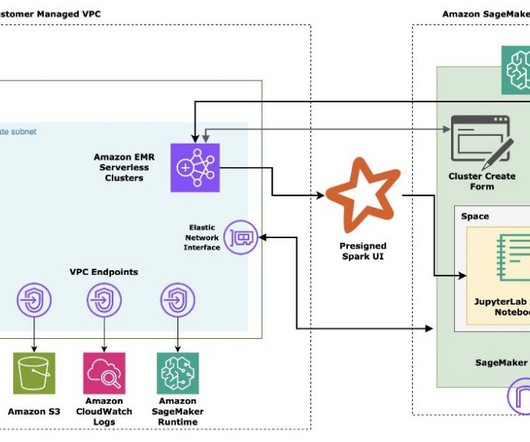
This presents an undesired threat vector for exfiltration and gaining access to customer data when proper access controls are not enforced. Studio supports a few methods for enforcing access controls against presigned URL data exfiltration: Client IP validation using the IAM policy condition aws:sourceIp.
SageMaker provides end-to-end ML development, deployment, and monitoring capabilities such as a SageMaker Studio notebook environment for writing code, data acquisition, data tagging, model training, model tuning, deployment, monitoring, and much more.
The presented MLOps workflow provides a reusable template for managing the ML lifecycle through automation, monitoring, auditability, and scalability, thereby reducing the complexities and costs of maintaining batch inference workloads in production. The central model registry could optionally be placed in a shared services account as well.
She currently serves as SVP of Global Customer Success at Guavus , which she describes as “a bigdata real-time analytics company supporting the largest and most complex data infrastructures in the world.”. I actually just presented at an AI conference recently, and I love to do things like that.
With this high turnover presenting a significant challenge to contact centers in terms of cost, productivity and morale, it is not surprising that there’s an ongoing global trend towards fostering agent development and enhancing their day-to-day activities.
It’s aligned with the AWS recommended practice of using temporary credentials to access AWS accounts. At the time of this writing, you can create only one domain per AWS account per Region. To implement the strong separation, you can use multiple AWS accounts with one domain per account as a workaround.
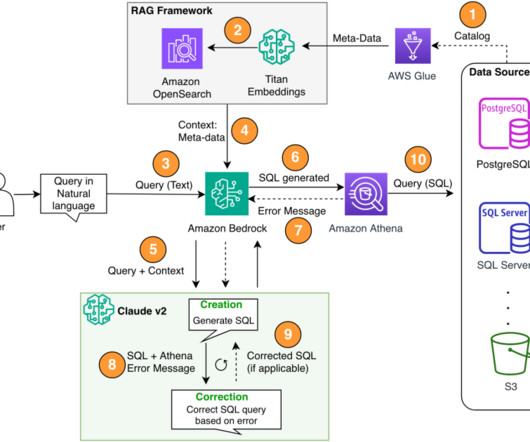
To overcome this limitation and provide dynamism and adaptability to knowledge base changes, we decided to follow a Retrieval Augmented Generation (RAG) approach, in which the LLMs are presented with relevant information extracted from external data sources to provide up-to-date data without the need to retrain the models.
The ability for companies to collect, store, and manage vast amounts of digital information has paved the way for bigdata to shape corporate strategy for a variety of departments. Which leads to another challenge surrounding cognitive AI—knowing what data to collect. Then figure out what to do later.”
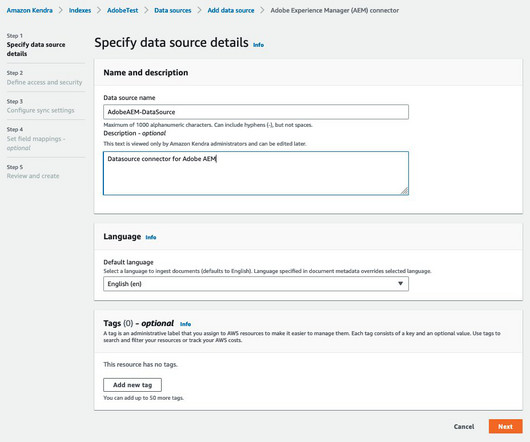
Prerequisites To try out the Amazon Kendra connector for AEM using this post as a reference, you need the following: An AWS account with privileges to create AWS Identity and Access Management (IAM) roles and policies. She is passionate about designing bigdata workloads cloud-natively. Choose Save or Add Secret.
It also launched "bigdata" into the mainstream, and support teams had more information about their customers than ever before. Assuming you have historical customer and data in your support software solution, machine learning can be powerful in driving interactions that matter.
We demonstrate CDE using simple examples and provide a step-by-step guide for you to experience CDE in an Amazon Kendra index in your own AWS account. A centralized data lake with informative data catalogs would reduce duplication efforts and enable wider sharing of creative content and consistency between teams.
MLOps includes practices that integrate ML workloads into release management, CI/CD, and operations, accounting for the unique aspects of ML projects, including considerations for deploying and monitoring models. In a broader model development picture, models are typically trained in a data science development account.
Using BigData to Make Leadership Advances in the Workplace. Back to Best Buy’s learnings they presented at the Future Miami convention earlier this year, they showed that in addition to dropping employee turnover, they also wanted to focus on retaining their best employees with newer styles of training.
A customer churn analysis is an investigation that uses bigdata analytics methods to go beyond churn rate and identify underlying factors promoting customer churn. For a comprehensive analysis, use a systematic customer churn analysis checklist that takes into account potential problems from each stage of your customer journey.
SIMD describes computers with multiple processing elements that perform the same operation on multiple data points simultaneously. SIMT describes processors that are able to operate on data vectors and arrays (as opposed to just scalars), and therefore handle bigdata workloads efficiently. Tick 2 trade.
This evolution has been driven by advancements in machine learning, natural language processing, and bigdata analytics. These recommendations are highly personalized, increasing the likelihood of conversion by presenting customers with options that resonate with their specific preferences and needs.
This evolution has been driven by advancements in machine learning, natural language processing, and bigdata analytics. These recommendations are highly personalized, increasing the likelihood of conversion by presenting customers with options that resonate with their specific preferences and needs.
The Model dashboard is a centralized repository of all models that have been created in the account. The Model dashboard offers a rich set of information regarding the overall model ecosystem in an account, in addition to the ability to drill into the specific details of a model. SageMaker Model Dashboard. Conclusion.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content