This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
We recently announced the general availability of cross-account sharing of Amazon SageMaker Model Registry using AWS Resource Access Manager (AWS RAM) , making it easier to securely share and discover machine learning (ML) models across your AWS accounts. Mitigation strategies : Implementing measures to minimize or eliminate risks.
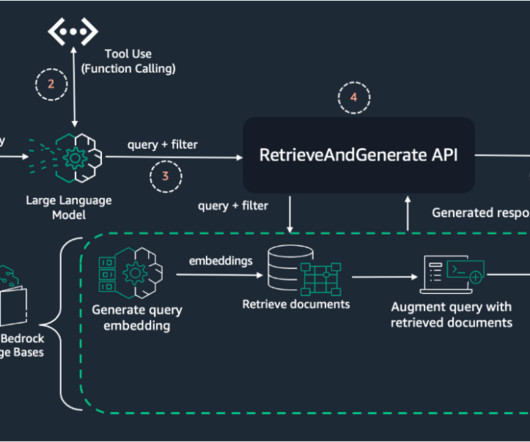
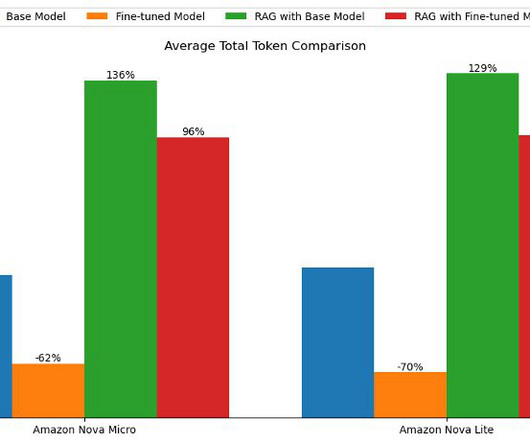
In some use cases, particularly those involving complex user queries or a large number of metadata attributes, manually constructing metadata filters can become challenging and potentially error-prone. By implementing dynamic metadata filtering, you can significantly improve these metrics, leading to more accurate and relevant RAG responses.
Thanks to this construct, you can evaluate any LLM by configuring the model runner according to your model. Evaluation algorithm Computes evaluation metrics to model outputs. Different algorithms have different metrics to be specified. For example, spider plots are often used to make visual comparison across multiple metrics.
Unfortunately, Reichheld says too many organizations use NPS as a stick or a metric for earning bonuses. He says that the financial metrics most companies use for valuations point you toward the wrong investments. Reichheld also wanted it to be accounting-based because it is well regulated, and there are rules for measurement.
For enterprises, a well-constructed customer health score isnt just a nice-to-have; its a strategic asset that empowers teams to manage complexity, sustain customer satisfaction, and scale their customer success efforts. The enterprise solution Large customer accounts often have layered needs.
Under Input data , enter the location of the source S3 bucket (training data) and target S3 bucket (model outputs and training metrics), and optionally the location of your validation dataset. For Job name , enter a name for the fine-tuning job.
Having accounting skills is very important for entrepreneurs and managers from every industry sector. To help you with that, there are several online accounting courses from different levels. To help you with that, there are several online accounting courses from different levels. Accounting & Financial Statement Analysis.
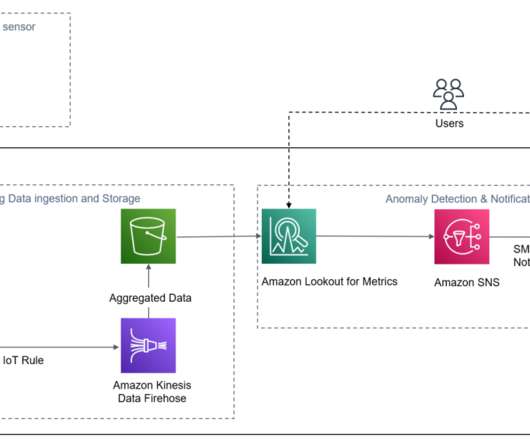
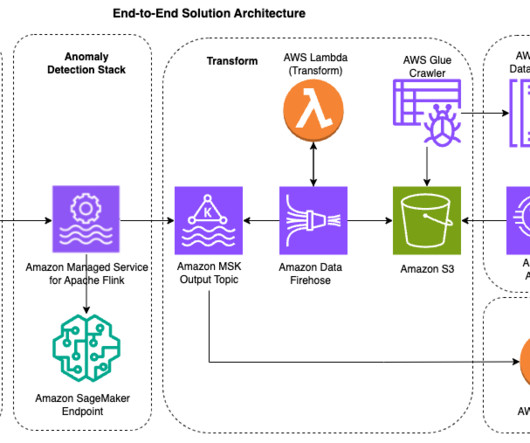
This post shows you how to use an integrated solution with Amazon Lookout for Metrics and Amazon Kinesis Data Firehose to break these barriers by quickly and easily ingesting streaming data, and subsequently detecting anomalies in the key performance indicators of your interest. You don’t need ML experience to use Lookout for Metrics.
Where discrete outcomes with labeled data exist, standard ML methods such as precision, recall, or other classic ML metrics can be used. These metrics provide high precision but are limited to specific use cases due to limited ground truth data. If the use case doesnt yield discrete outputs, task-specific metrics are more appropriate.
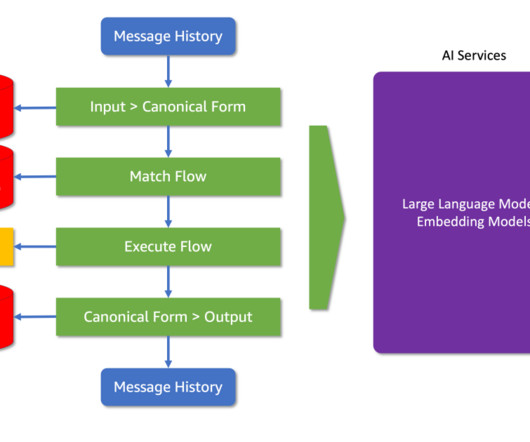
Some links for security best practices are shared below but we strongly recommend reaching out to your account team for detailed guidance and to discuss the appropriate security architecture needed for a secure and compliant deployment. What is Nemo Guardrails? First, lets try to understand what guardrails are and why we need them.
Some Customer Success metrics are considered standard but there’s often more than meets the eye. Sales and marketing professionals that geek out on metrics can find themselves in deep philosophical debates about the best numbers to track. That nuance is derived from three underlying factors: Construct.
This means understanding the metrics that need to be monitored, transcribed, and analyzed in order to glean actionable insights. . Average speed of answer is one of the most important metrics for call centers to measure. Included in this metric is the time a caller waits in a queue. Customer Abandonment.
Graphs and charts benchmark accuracy is based on business reports and presentations constructed internally. Design files benchmark accuracy is based on a product design retrieval dataset constructed internally. Recall@5 is a specific metric used in information retrieval evaluation, including in the BEIR benchmark.
Giving more power to the user comes on account of simple user experience (UX). Constructing SQL queries from natural language isn’t a simple task. Figure 2: High level database access using an LLM flow The challenge An LLM can construct SQL queries based on natural language. The challenge is to assure quality.
Identify nuanced sentiment: AI detects subtle emotional cues, providing a deeper understanding of customer satisfaction beyond surface-level metrics. Ensure agents fully understand these standards, including the metrics used for evaluation. Transparency and clarity are paramount for agents to perform at their best.
Choose the right metrics to inform your forecasting model. Focus on collecting and tracking the metrics that are most meaningful to your teams retention strategy. With metrics in hand, its time to start pulling out the trends, themes, and stories behind the numbers. Collecting the right historical data is key.
Take advantage of this phenomenon by constructing your scripts to promote positive responses.” They are an easy way to track metrics and discover trends within your agents. “The nature of a call center operator’s job is very sensitive, as there is account information available every time they assist a customer.
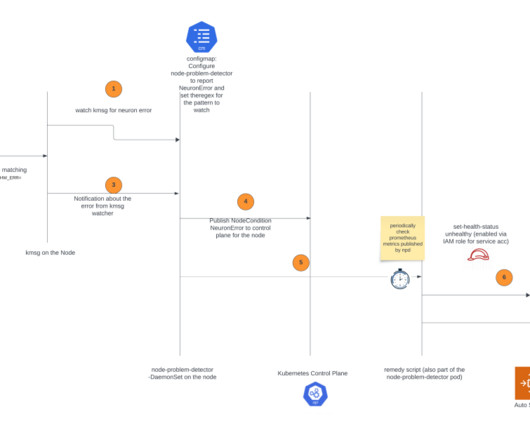
The node recovery agent is a separate component that periodically checks the Prometheus metrics exposed by the node problem detector. Additionally, the node recovery agent will publish Amazon CloudWatch metrics for users to monitor and alert on these events. The following diagram illustrates the solution architecture and workflow.
The implementation used in this post utilizes the Amazon Textract IDP CDK constructs – AWS Cloud Development Kit (CDK) components to define infrastructure for Intelligent Document Processing (IDP) workflows – which allow you to build use case specific customizable IDP workflows.
Performance metrics and benchmarks Pixtral 12B is trained to understand both natural images and documents, achieving 52.5% You can review the Mistral published benchmarks Prerequisites To try out Pixtral 12B in Amazon Bedrock Marketplace, you will need the following prerequisites: An AWS account that will contain all your AWS resources.
You now have the same construct, but it is far more complex to measure. Changing the way AHT is measured to accommodate communication via social media allows the call center to continue using known metrics for conversations and reporting, but will enhance the accuracy of the data. Enter social media. FCR – First Contact Resolution.
Provide control through transparency of models, guardrails, and costs using metrics, logs, and traces The control pillar of the generative AI framework focuses on observability, cost management, and governance, making sure enterprises can deploy and operate their generative AI solutions securely and efficiently.
In our use case, a financial institution wants to extract the following fields from a check: payee name, payer name, account number, routing number, payment amount (in numbers), payment amount (in words), check number, date, and memo. What is the account#? What is the account name/payer/drawer name? Who is the payee?
Generative AI CDK Constructs , an open-source extension of AWS CDK, provides well-architected multi-service patterns to quickly and efficiently create repeatable infrastructure required for generative AI projects on AWS. Prerequisites To follow along with this post, you should have the following prerequisites: Python version greater than 3.9
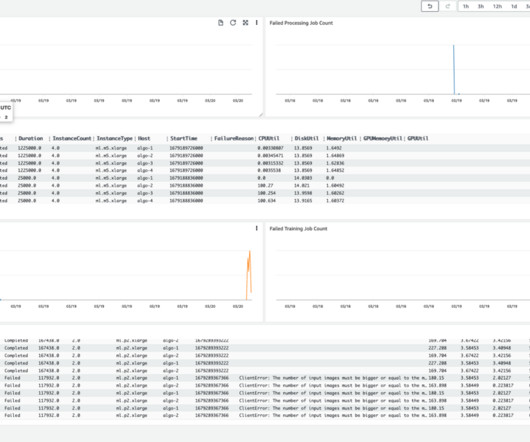
You can also fetch these metrics and analyze them using TrainingJobAnalytics : df = TrainingJobAnalytics(training_job_name=training_job_name).dataframe() dataframe() #It will produce a dataframe with different metrics df.head(10) The following graph shows different metrics collected from the CloudWatch log using TrainingJobAnalytics.
Ownership over Accountability. When your focus is on how to hold people accountable, it takes your focus off an important question: “Why do we need to hold people accountable in the first place?”. She states that if you believe people need to be held accountable, what is YOUR underlying belief? Why is that? Ownership.
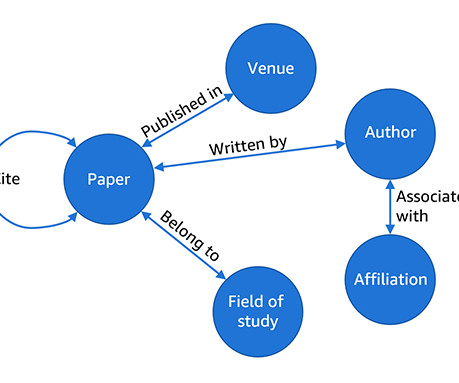
With GraphStorm, you can build solutions that directly take into account the structure of relationships or interactions between billions of entities, which are inherently embedded in most real-world data, including fraud detection scenarios, recommendations, community detection, and search/retrieval problems.
With GraphStorm, you can build solutions that directly take into account the structure of relationships or interactions between billions of entities, which are inherently embedded in most real-world data, including fraud detection scenarios, recommendations, community detection, and search/retrieval problems.
The company’s Data & Analytics team regularly receives client requests for unique reports, metrics, or insights, which require custom development. Business metadata can be constructed using services like Amazon DataZone. Similarly, Amazon Bedrock metrics are available by navigating to Metrics , Bedrock on the CloudWatch console.
The sheer number of metrics make it hard to filter down to ones that are truly relevant for their use-cases. Amazon SageMaker Clarify now provides AWS customers with foundation model (FM) evaluations, a set of capabilities designed to evaluate and compare model quality and responsibility metrics for any LLM, in minutes.
The second approach is a turnkey deployment of various infrastructure components using AWS Cloud Development Kit (AWS CDK) constructs. The AWS CDK construct provides a resilient and flexible framework to process your documents and build an end-to-end IDP pipeline. Now on to our second solution for documents at scale.
It offers an AWS CloudFormation template for straightforward deployment in an AWS account. The application, once deployed, constructs an ML model using the Random Cut Forest (RCF) algorithm. The template creates the essential resources like the Apache Flink application and Amazon SageMaker real-time endpoint in the customer account.
As recommended by AWS as a best practice , customers have used separate accounts to simplify policy management for users and isolate resources by workloads and account. SageMaker services, such as Processing, Training, and Hosting, collect metrics and logs from the running instances and push them to users’ Amazon CloudWatch accounts.
For example, in some e-commerce platforms, account registration is wide open. Fraudsters can behave maliciously just once with an account and never use the same account again. Additionally, it’s challenging to construct a streaming data pipeline that can feed incoming events to a GNN real-time serving API.
Customer satisfaction is a potent metric that directly influences the profitability of an organization. Reviewing the Account Balance chatbot. As an example, this demo deploys a bot to perform three automated tasks, or intents : Check Balance , Transfer Funds , and Open Account. Account Type. Deploying the solution.
The goal of NAS is to find the optimal architecture for a given problem by searching over a large set of candidate architectures using techniques such as gradient-free optimization or by optimizing the desired metrics. The performance of the architecture is typically measured using metrics such as validation loss. Choose Request.
Let’s first look at the three most popular customer survey metrics and how they’re measured and then I’ll share a way to approach the results more holistically. We found that many of our clients track this metric but few give any visibility to the contact center or hold them directly accountable. Customer Satisfaction (CSAT).
The reason is that customer service impacts the satisfaction metrics that influence customer perception, too. Perception involves three psychological constructs: sensing, organizing, and reacting. What factors should companies take into account? Customer perception is directly tied to the bottom line. Net Promoter Score (NPS).
Understanding the intrinsic value of data network effects, Vidmob constructed a product and operational system architecture designed to be the industry’s most comprehensive RLHF solution for marketing creatives. Aperture – Important aspects to take into account for a user question.
software bug fixes, wrong information corrected on the website) Product development decisions : reprioritizing things on the product development roadmap taking the feedback into account (e.g. more friendly behavior in customer service) Marketing to take the info into account in better targeting (e.g. Wondering which metric to choose?
What if you need more constructive feedback to make things better for your customers? Accordingly, customer satisfaction metrics are important business assets that show how happy your customers are with the products or services that you provide. . Define the relevant customer satisfaction metrics for your business .
Each business unit has each own set of development (automated model training and building), preproduction (automatic testing), and production (model deployment and serving) accounts to productionize ML use cases, which retrieve data from a centralized or decentralized data lake or data mesh, respectively.
Some Customer Success metrics are considered standard but there’s often more than meets the eye. SaaS professionals who geek out on metrics can find themselves in deep philosophical debates about the best numbers to track. That nuance is derived from three underlying factors: Construct.
One risk many organizations face is the inadvertent exposure of sensitive data through logs, voice chat transcripts, and metrics. For example, you may have the following data types: Name Address Phone number Email address Account number Email address and physical mailing address are often considered a medium classification level.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content