This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This post dives deep into how to set up data governance at scale using Amazon DataZone for the data mesh. The data mesh is a modern approach to data management that decentralizes data ownership and treats data as a product.
The solution integrates large language models (LLMs) with your organization’s data and provides an intelligent chat assistant that understands conversation context and provides relevant, interactive responses directly within the Google Chat interface. A Business or Enterprise Google Workspace account with access to Google Chat.
Let’s say your IT system requires getting your email address for every customer to access the details of the account. When you are frustrated, stressed, and upset, how do you feel about entering your account number followed by the pound sign? In many cases, they will also use a Call Center script. Let me give you an example.
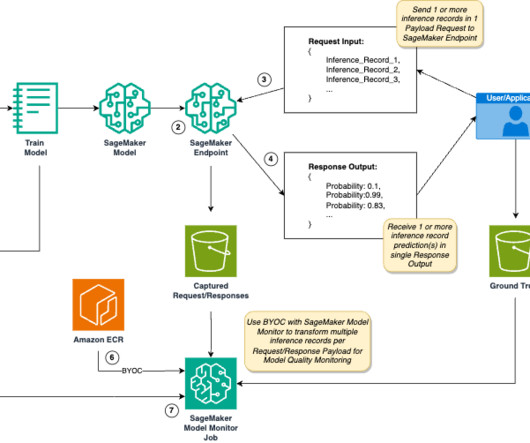
Examples include financial systems processing transaction data streams, recommendation engines processing user activity data, and computer vision models processing video frames. A preprocessor script is a capability of SageMaker Model Monitor to preprocess SageMaker endpoint data capture before creating metrics for model quality.
If Artificial Intelligence for businesses is a red-hot topic in C-suites, AI for customer engagement and contact center customer service is white hot. This white paper covers specific areas in this domain that offer potential for transformational ROI, and a fast, zero-risk way to innovate with AI.
In this post, we explore how you can use Amazon Bedrock to generate high-quality categorical ground truth data, which is crucial for training machine learning (ML) models in a cost-sensitive environment. For the multiclass classification problem to label support case data, synthetic data generation can quickly result in overfitting.
Amazon Bedrock empowers teams to generate Terraform and CloudFormation scripts that are custom fitted to organizational needs while seamlessly integrating compliance and security best practices. Traditionally, cloud engineers learning IaC would manually sift through documentation and best practices to write compliant IaC scripts.
The value is in the timing—customers will give the most accurate accounts of their service experiences shortly after they’ve happened. You might have a carefully crafted questionnaire or script for your after-call survey. Have you collected enough data? Fonolo’s Portal could help with real-time insights and data-rich reporting.
Let’s say your IT system requires getting your email address for every customer to access the details of the account. When you are frustrated, stressed, and upset, how do you feel about entering your account number followed by the pound sign? In many cases, they will also use a Call Center script. Let me give you an example.
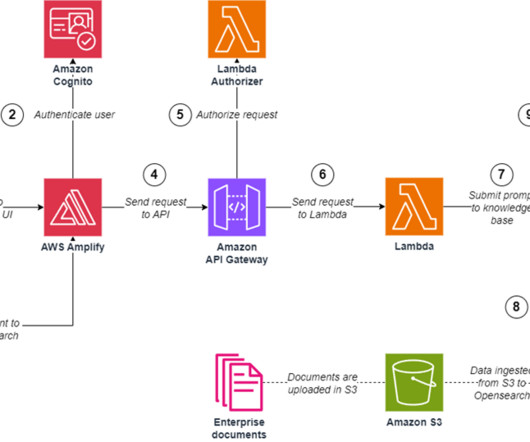
One of the most critical applications for LLMs today is Retrieval Augmented Generation (RAG), which enables AI models to ground responses in enterprise knowledge bases such as PDFs, internal documents, and structured data. These five webpages act as a knowledge base (source data) to limit the RAG models response.
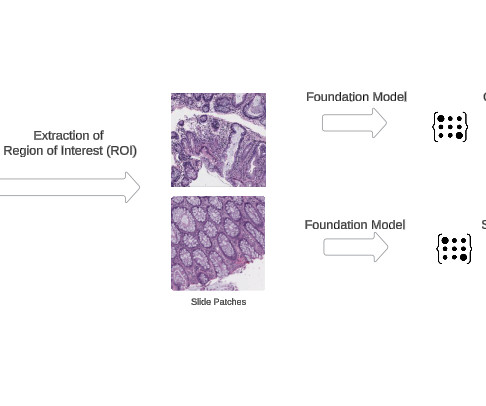
The power of FMs lies in their ability to learn robust and generalizable data embeddings that can be effectively transferred and fine-tuned for a wide variety of downstream tasks, ranging from automated disease detection and tissue characterization to quantitative biomarker analysis and pathological subtyping.
script to automatically copy the cdk configuration parameters to a configuration file by running the following command, still in the /cdk folder: /scripts/postdeploy.sh Drawing from her background in data science, Arian assists customers in effectively using generative AI and other AI technologies.
Amazon Bedrock offers a serverless experience, so you can get started quickly, privately customize FMs with your own data, and integrate and deploy them into your applications using AWS tools without having to manage any infrastructure. One consistent pain point of fine-tuning is the lack of data to effectively customize these models.
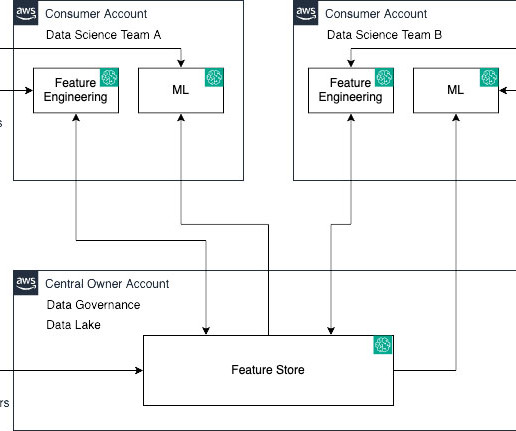
SageMaker Feature Store now makes it effortless to share, discover, and access feature groups across AWS accounts. With this launch, account owners can grant access to select feature groups by other accounts using AWS Resource Access Manager (AWS RAM).
After writing over one thousand call center scripts, we know that there isn’t a single stand-alone ingredient we’d consider the ‘secret sauce’ for creating the perfect script. Instead, scripts are purposeful and serve as a guide to accomplish the objective of the call. No, it doesn’t.
Concerns about legal implications, accuracy of AI-generated outputs, data privacy, and broader societal impacts have underscored the importance of responsible AI development. This can be useful when you have requirements for sensitive data handling and user privacy.
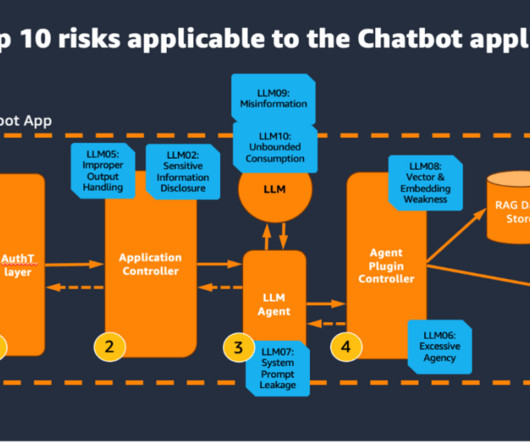
These steps might involve both the use of an LLM and external data sources and APIs. Agent plugin controller This component is responsible for the API integration to external data sources and APIs. Amazon Cognito complements these defenses by enabling user authentication and data synchronization.
Many organizations have been using a combination of on-premises and open source data science solutions to create and manage machine learning (ML) models. Data science and DevOps teams may face challenges managing these isolated tool stacks and systems.
Dimension Data research says that 56 percent of businesses expect transactions via telephone to fall over the next two years. But there remains an emotional intelligence divide between robots and humans as there is yet to be an AI able to effectively quantify human feelings and moods into unique data points or profiles.
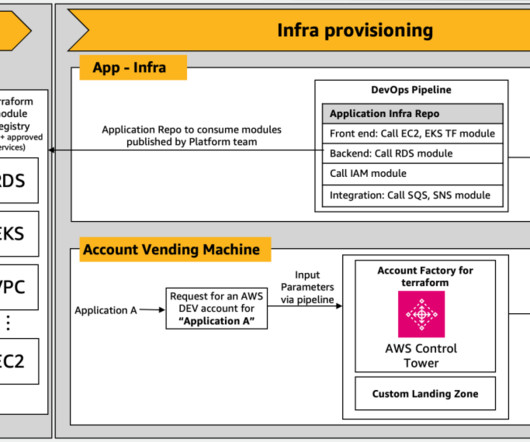
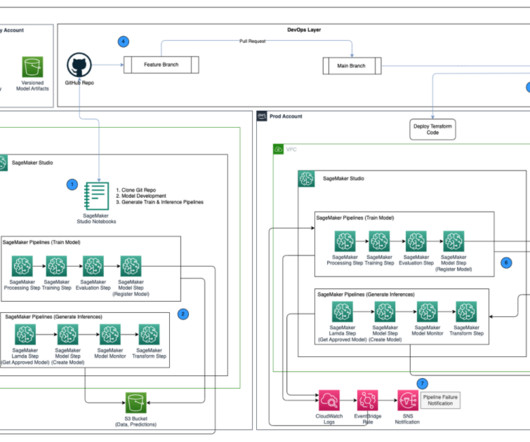
When designing production CI/CD pipelines, AWS recommends leveraging multiple accounts to isolate resources, contain security threats and simplify billing-and data science pipelines are no different. Some things to note in the preceding architecture: Accounts follow a principle of least privilege to follow security best practices.
Medusa-1 achieves an inference speedup of around two times without sacrificing model quality, with the exact improvement varying based on model size and data used. For details, refer to Creating an AWS account. Make sure you have sufficient capacity for this instance in your AWS account by requesting a quota increase if required.
The opportunities to unlock value using AI in the commercial real estate lifecycle starts with data at scale. Although CBRE provides customers their curated best-in-class dashboards, CBRE wanted to provide a solution for their customers to quickly make custom queries of their data using only natural language prompts.
“A good outbound sales script contains a strong connecting statement. ” – Grace Sweeney, 5 Outbound Sales Scripts You Can Adjust on the Fly , Copper; Twitter: @copperinc. ” – Brad Beutler, 6 Examples of Using Employee Email as a New Account Based Marketing Channel , Terminus; Twitter: @Terminus.
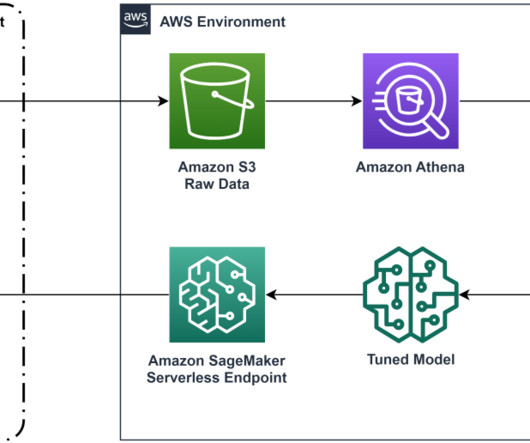
If you use the default lifecycle configuration for your domain or user profile in Amazon SageMaker Studio and use Amazon SageMaker Data Wrangler for data preparation, then this post is for you. Data Wrangler supports standard data types such as CSV, JSON, ORC, and Parquet. For more information, see Jupyter Kernel Gateway.
In this post, we show how to configure a new OAuth-based authentication feature for using Snowflake in Amazon SageMaker Data Wrangler. Snowflake is a cloud data platform that provides data solutions for data warehousing to data science. For more information about prerequisites, see Get Started with Data Wrangler.
This post shows how Amazon SageMaker enables you to not only bring your own model algorithm using script mode, but also use the built-in HPO algorithm. We walk through the following steps: Use SageMaker script mode to bring our own model on top of an AWS-managed container. Solution overview. Find the metric in CloudWatch Logs.
To build a generative AI -based conversational application integrated with relevant data sources, an enterprise needs to invest time, money, and people. First, you would need build connectors to the data sources. For a full list of supported data source connectors, see Amazon Q Business connectors.
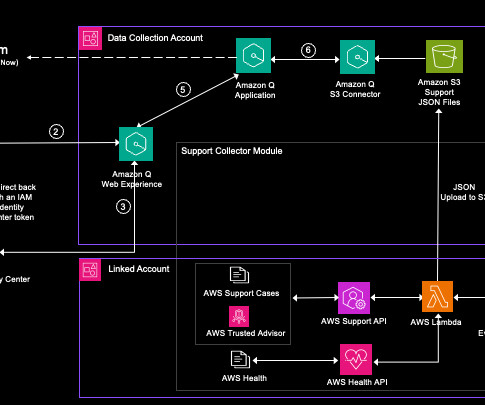
This post shows how to use AWS generative artificial intelligence (AI) services , like Amazon Q Business , with AWS Support cases, AWS Trusted Advisor , and AWS Health data to derive actionable insights based on common patterns, issues, and resolutions while using the AWS recommendations and best practices enabled by support data.
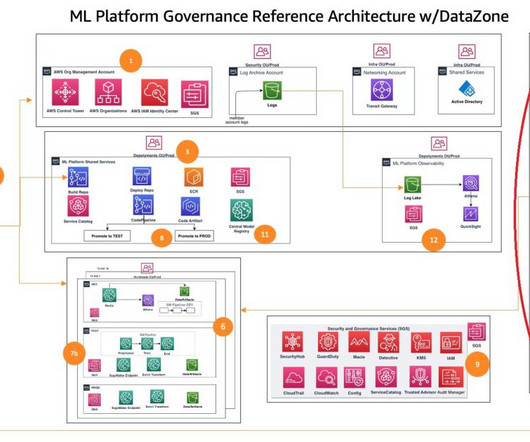
This is the second part of a series that showcases the machine learning (ML) lifecycle with a data mesh design pattern for a large enterprise with multiple lines of business (LOBs) and a Center of Excellence (CoE) for analytics and ML. In this post, we address the analytics and ML platform team as a consumer in the data mesh.
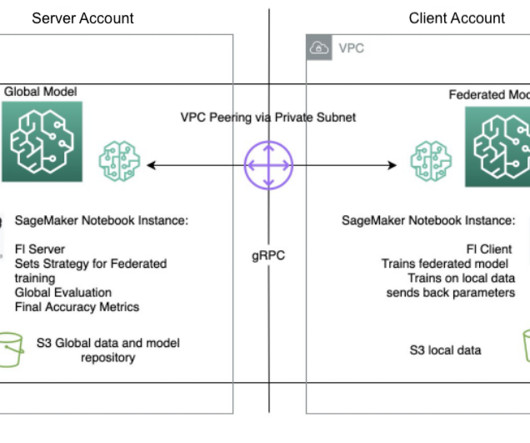
Machine learning (ML) is revolutionizing solutions across industries and driving new forms of insights and intelligence from data. Many ML algorithms train over large datasets, generalizing patterns it finds in the data and inferring results from those patterns as new unseen records are processed. What is federated learning?
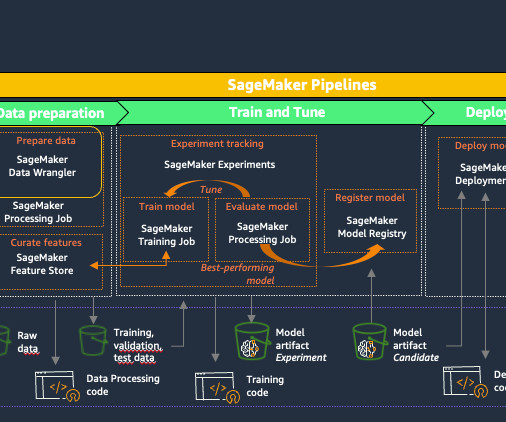
Building out a machine learning operations (MLOps) platform in the rapidly evolving landscape of artificial intelligence (AI) and machine learning (ML) for organizations is essential for seamlessly bridging the gap between data science experimentation and deployment while meeting the requirements around model performance, security, and compliance.
Analyzing real-world healthcare and life sciences (HCLS) data poses several practical challenges, such as distributed data silos, lack of sufficient data at a single site for rare events, regulatory guidelines that prohibit data sharing, infrastructure requirement, and cost incurred in creating a centralized data repository.
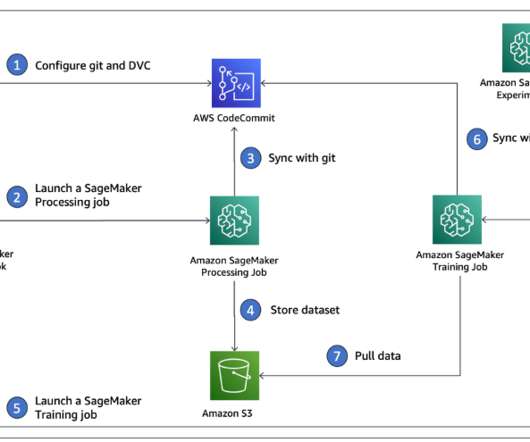
Data scientists often work towards understanding the effects of various data preprocessing and feature engineering strategies in combination with different model architectures and hyperparameters. Data Version Control. These placeholders point to the original data, which is decoupled from source code management.
Offline reinforcement learning is a control strategy that allows industrial companies to build control policies entirely from historical data without the need for an explicit process model. In offline reinforcement learning, one can train a policy on historical data before deploying it into production.
These customers need to balance governance, security, and compliance against the need for machine learning (ML) teams to quickly access their data science environments in a secure manner. One important aspect of this foundation is to organize their AWS environment following a multi-account strategy.
Whether you are managing multiple accounts, scraping data for market research, or simply trying to maintain your privacy online, choosing the right proxy service is crucial. This demonstrates their commitment to being there when needed mostwhether you’re managing key campaigns or ensuring data scraping scripts run smoothly.
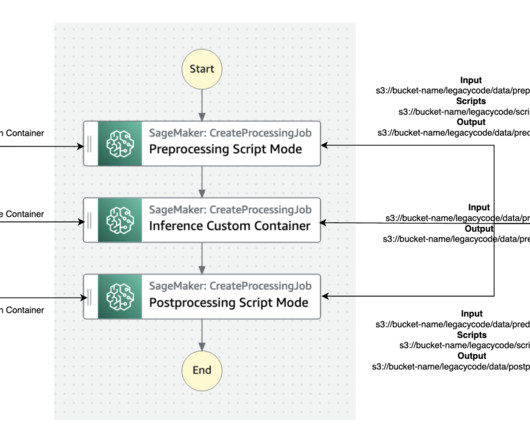
We demonstrate how two different personas, a data scientist and an MLOps engineer, can collaborate to lift and shift hundreds of legacy models. SageMaker runs the legacy script inside a processing container. We assume the involvement of two personas: a data scientist and an MLOps engineer.
Building and deploying these components can be complex and error-prone, especially when dealing with large-scale data and models. The solution simplifies the setup process, allowing you to quickly deploy and start querying your data using the selected FM. After the script is complete, note the S3 URL of the main-template-out.yml.
Customers increasingly want to use deep learning approaches such as large language models (LLMs) to automate the extraction of data and insights. For many industries, data that is useful for machine learning (ML) may contain personally identifiable information (PII).
Twilio enables companies to use communications and data to add intelligence and security to every step of the customer journey, from sales and marketing to growth and customer service, and many more engagement use cases in a flexible, programmatic way. Twilio needed to implement an MLOps pipeline that queried data from PrestoDB.
With the rise of generative artificial intelligence (AI), an increasing number of organizations use digital assistants to have their end-users ask domain-specific questions, using Retrieval Augmented Generation (RAG) over their enterprise data sources. Refer to the Amazon Bedrock FAQs for further details. installed Node.js
Retrieval Augmented Generation (RAG) is a popular paradigm that provides additional knowledge to large language models (LLMs) from an external source of data that wasn’t present in their training corpus. Prerequisites For this walkthrough, you should have the following prerequisites: An AWS account set up.
“Instead of focusing on the code, companies should focus on developing systematic engineering practices for improving data in ways that are reliable, efficient, and systematic. This can be a tedious task involving data collection, discovery, profiling, cleansing, structuring, transforming, enriching, validating, and securely storing the data.
Or an organization may be operating in a Region where a primary cloud provider is not available, and in order to meet the data sovereignty or data residency requirements, they can use a secondary cloud provider. Prerequisites You should have the following prerequisites: An AWS account. image and Python 3.0
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



























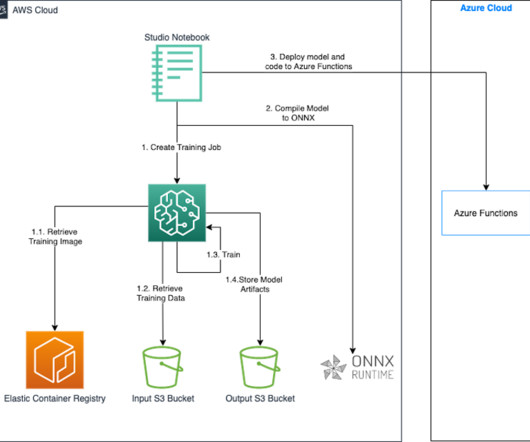









Let's personalize your content