This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this post, we focus on one such complex workflow: document processing. Rule-based systems or specialized machine learning (ML) models often struggle with the variability of real-world documents, especially when dealing with semi-structured and unstructured data.
Observability refers to the ability to understand the internal state and behavior of a system by analyzing its outputs, logs, and metrics. Security – The solution uses AWS services and adheres to AWS Cloud Security best practices so your data remains within your AWS account.
Amazon Textract is a machine learning (ML) service that automatically extracts text, handwriting, and data from scanned documents. Queries is a feature that enables you to extract specific pieces of information from varying, complex documents using natural language. personal or cashier’s checks), financial institution and country (e.g.,
Current RAG pipelines frequently employ similarity-based metrics such as ROUGE , BLEU , and BERTScore to assess the quality of the generated responses, which is essential for refining and enhancing the models capabilities. More sophisticated metrics are needed to evaluate factual alignment and accuracy.
Organizations across industries want to categorize and extract insights from high volumes of documents of different formats. Manually processing these documents to classify and extract information remains expensive, error prone, and difficult to scale. Categorizing documents is an important first step in IDP systems.
We recently announced the general availability of cross-account sharing of Amazon SageMaker Model Registry using AWS Resource Access Manager (AWS RAM) , making it easier to securely share and discover machine learning (ML) models across your AWS accounts. Mitigation strategies : Implementing measures to minimize or eliminate risks.
Lets say the task at hand is to predict the root cause categories (Customer Education, Feature Request, Software Defect, Documentation Improvement, Security Awareness, and Billing Inquiry) for customer support cases. These metrics provide high precision but are limited to specific use cases due to limited ground truth data.
By narrowing down the search space to the most relevant documents or chunks, metadata filtering reduces noise and irrelevant information, enabling the LLM to focus on the most relevant content. This approach narrows down the search space to the most relevant documents or passages, reducing noise and irrelevant information.
For modern companies that deal with enormous volumes of documents such as contracts, invoices, resumes, and reports, efficiently processing and retrieving pertinent data is critical to maintaining a competitive edge. What if there was a way to process documents intelligently and make them searchable in with high accuracy?
By documenting the specific model versions, fine-tuning parameters, and prompt engineering techniques employed, teams can better understand the factors contributing to their AI systems performance. Evaluation algorithm Computes evaluation metrics to model outputs. Different algorithms have different metrics to be specified.
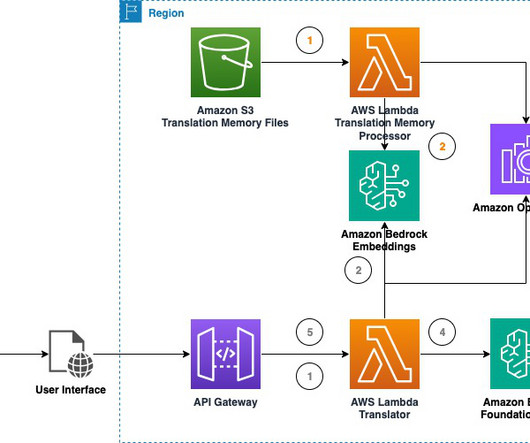
The solution offers two TM retrieval modes for users to choose from: vector and document search. When using the Amazon OpenSearch Service adapter (document search), translation unit groupings are parsed and stored into an index dedicated to the uploaded file. This is covered in detail later in the post.
AWS customers in healthcare, financial services, the public sector, and other industries store billions of documents as images or PDFs in Amazon Simple Storage Service (Amazon S3). In this post, we focus on processing a large collection of documents into raw text files and storing them in Amazon S3.
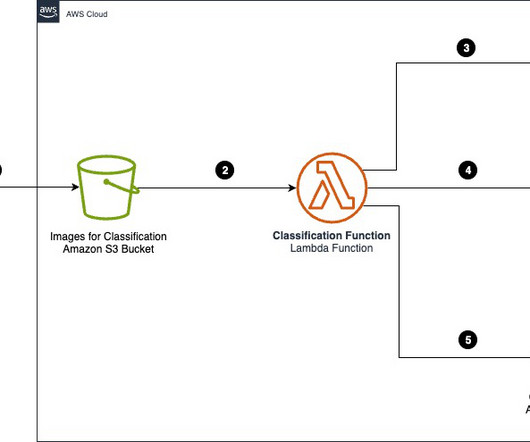
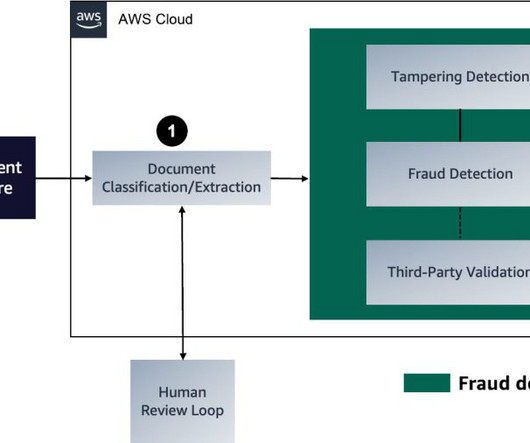
In the first post of this three-part series, we presented a solution that demonstrates how you can automate detecting document tampering and fraud at scale using AWS AI and machine learning (ML) services for a mortgage underwriting use case. The following diagram represents each stage in a mortgage document fraud detection pipeline.
This approach allows organizations to assess their AI models effectiveness using pre-defined metrics, making sure that the technology aligns with their specific needs and objectives. Prerequisites To use the LLM-as-a-judge model evaluation, make sure that you have satisfied the following requirements: An active AWS account.
But without numbers or metric data in hand, coming up with any new strategy would only consume your valuable time. For example, you need access to metrics like NPS, average response time and others like it to make sure you come up with relevant strategies that help you retain more customers. 8: Average Revenue Per Account. #9:
I’m not going to waste time trying to document how to correctly (mathematically) calculate all the three letter acronyms—but feel free to check out our Customer Success Definitions, Calculations, and Lingo…Oh My! Instead, I want to do some level setting on some specific metrics and flaws I see in the industry.
Although automated metrics are fast and cost-effective, they can only evaluate the correctness of an AI response, without capturing other evaluation dimensions or providing explanations of why an answer is problematic. Human evaluation, although thorough, is time-consuming and expensive at scale.
Amazon Lookout for Metrics is a fully managed service that uses machine learning (ML) to detect anomalies in virtually any time-series business or operational metrics—such as revenue performance, purchase transactions, and customer acquisition and retention rates—with no ML experience required. To learn more, see the documentation.
For automatic model evaluation jobs, you can either use built-in datasets across three predefined metrics (accuracy, robustness, toxicity) or bring your own datasets. Regular evaluations allow you to adjust and steer the AI’s behavior based on feedback and performance metrics.
Such data often lacks the specialized knowledge contained in internal documents available in modern businesses, which is typically needed to get accurate answers in domains such as pharmaceutical research, financial investigation, and customer support. For example, imagine that you are planning next year’s strategy of an investment company.
The ability to effectively handle and process enormous amounts of documents has become essential for enterprises in the modern world. Due to the continuous influx of information that all enterprises deal with, manually classifying documents is no longer a viable option.
SageMaker JumpStart is a machine learning (ML) hub that provides a wide range of publicly available and proprietary FMs from providers such as AI21 Labs, Cohere, Hugging Face, Meta, and Stability AI, which you can deploy to SageMaker endpoints in your own AWS account. This logic sits in a hybrid search component.
Metrics, Measure, and Monitor – Make sure your metrics and associated goals are clear and concise while aligning with efficiency and effectiveness. Make each metric public and ensure everyone knows why that metric is measured. Jeff Greenfield is the co-founder and chief operating officer of C3 Metrics.
This post shows how to configure an Amazon Q Business custom connector and derive insights by creating a generative AI-powered conversation experience on AWS using Amazon Q Business while using access control lists (ACLs) to restrict access to documents based on user permissions. Who are the data stewards for my proprietary database sources?
One of the most critical applications for LLMs today is Retrieval Augmented Generation (RAG), which enables AI models to ground responses in enterprise knowledge bases such as PDFs, internal documents, and structured data. How do Amazon Nova Micro and Amazon Nova Lite perform against GPT-4o mini in these same metrics?
Besides the efficiency in system design, the compound AI system also enables you to optimize complex generative AI systems, using a comprehensive evaluation module based on multiple metrics, benchmarking data, and even judgements from other LLMs. The DSPy lifecycle is presented in the following diagram in seven steps.
Link your WhatsApp Business account to your organization’s professional phone number for added credibility. A WhatsApp Shared Inbox for Teams allows multiple support agents to respond to customer messages from the same WhatsApp account. Attach PDFs such as invoices, receipts, or warranty documentation directly in the chat.
Intelligent document processing , translation and summarization, flexible and insightful responses for customer support agents, personalized marketing content, and image and code generation are a few use cases using generative AI that organizations are rolling out in production.
In addition, RAG architecture can lead to potential issues like retrieval collapse , where the retrieval component learns to retrieve the same documents regardless of the input. This makes it difficult to apply standard evaluation metrics like BERTScore ( Zhang et al.
Its a dynamic document that, like your partnership, requires time and attention. It also holds everyone accountable for the role theyre supposed to play. The contact center SOW will outline exactly what and how often metrics are to be reported and analyzed. Do metrics need to be adjusted?
Recall@5 is a specific metric used in information retrieval evaluation, including in the BEIR benchmark. decode("utf-8")) response = response["embeddings"]["float"][0] elif is_txt(doc): # Doc is a text file, encode it as a document with open(doc, "r") as fIn: text = fIn.read() print("Encode img desc:", doc, " - Content:", text[0:100]+".")
Organizations across industries such as retail, banking, finance, healthcare, manufacturing, and lending often have to deal with vast amounts of unstructured text documents coming from various sources, such as news, blogs, product reviews, customer support channels, and social media. Extract and analyze data from documents.
Its agent for software development can solve complex tasks that go beyond code suggestions, such as building entire application features, refactoring code, or generating documentation. Learn how they created specialized agents for different tasks like account management, repos, pipeline management, and more to help their developers go faster.
Designed for both image and document comprehension, Pixtral demonstrates advanced capabilities in vision-related tasks, including chart and figure interpretation, document question answering, multimodal reasoning, and instruction followingseveral of which are illustrated with examples later in this post. Pixtral_data/a01-000u-04.png'
This fosters a sense of shared ownership and accountability. Regular Meetings: Conduct regular business reviews to track progress on action plans, discuss performance metrics, and address any roadblocks that may arise. Documented Procedures: Document all service level agreements (SLAs) and operating procedures clearly and concisely.
They are an easy way to track metrics and discover trends within your agents. “The nature of a call center operator’s job is very sensitive, as there is account information available every time they assist a customer. Implement call centre etiquette tests regularly. This is short-sighted. ” – F. .”
Automated safety guards Integrated Amazon CloudWatch alarms monitor metrics on an inference component. AlarmName This CloudWatch alarm is configured to monitor metrics on an InferenceComponent. For more information, check out the SageMaker AI documentation or connect with your AWS account team.
While we were looking at your account we saw some searches for McDonald Heating and Cooling and added that as a negative keyword to prevent any wrong number calls coming through your ads." I've never focused on this as a metric so I have a couple of questions - 1. How do you metric-ize this? So far it is looking great!
In Part 1 of this series, we discussed intelligent document processing (IDP), and how IDP can accelerate claims processing use cases in the insurance industry. We discussed how we can use AWS AI services to accurately categorize claims documents along with supporting documents. Part 1: Classification and extraction of documents.
They learn that great coaches are deliberate about recognizing even small associate accomplishments, but also hold associates accountable for their improvements. While improving overall metrics is the end goal, coaching to metrics seldom brings sustainable results. Accountability is essential for coaches as well as associates.
When designing production CI/CD pipelines, AWS recommends leveraging multiple accounts to isolate resources, contain security threats and simplify billing-and data science pipelines are no different. Some things to note in the preceding architecture: Accounts follow a principle of least privilege to follow security best practices.
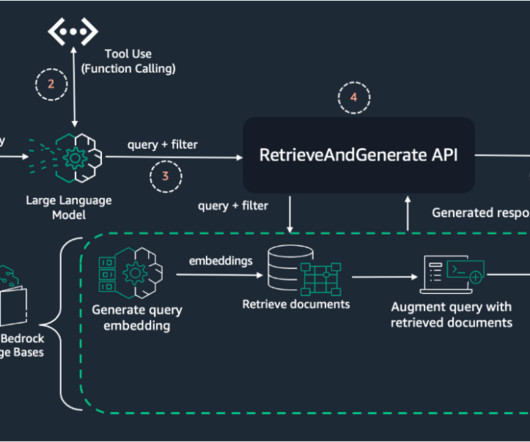
To find an answer, RAG takes an approach that uses vector search across the documents. Rather than scanning every single document to find the answer, with the RAG approach, you turn the texts (knowledge base) into embeddings and store these embeddings in the database. Generate questions from the document using an Amazon Bedrock LLM.
For example, a digitized agent coaching system enables team leaders to document their support interactions with agents and simultaneously capture key metrics about every touchpoint relevant to their routine. Analysts can correlate workflow intelligence with desired outcomes such as CSAT, NPS, FCR and other vital metrics.?
Data sources We use Spack documentation RST (ReStructured Text) files uploaded in an Amazon Simple Storage Service (Amazon S3) bucket. Whenever the assistant returns it as a source, it will be a link in the specific portion of the Spack documentation and not the top of a source page. For example, Spack images on Docker Hub.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content