This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
AWS offers powerful generative AI services , including Amazon Bedrock , which allows organizations to create tailored use cases such as AI chat-based assistants that give answers based on knowledge contained in the customers’ documents, and much more. A Business or Enterprise Google Workspace account with access to Google Chat.
Amazon Bedrock empowers teams to generate Terraform and CloudFormation scripts that are custom fitted to organizational needs while seamlessly integrating compliance and security best practices. Traditionally, cloud engineers learning IaC would manually sift through documentation and best practices to write compliant IaC scripts.
AWS customers in healthcare, financial services, the public sector, and other industries store billions of documents as images or PDFs in Amazon Simple Storage Service (Amazon S3). In this post, we focus on processing a large collection of documents into raw text files and storing them in Amazon S3.
The value is in the timing—customers will give the most accurate accounts of their service experiences shortly after they’ve happened. You might have a carefully crafted questionnaire or script for your after-call survey. It offers your call center a well-documented view of response rates, survey answers, and timing information.
One of the most critical applications for LLMs today is Retrieval Augmented Generation (RAG), which enables AI models to ground responses in enterprise knowledge bases such as PDFs, internal documents, and structured data. script provided with the CRAG benchmark for accuracy evaluations.
Question and answering (Q&A) using documents is a commonly used application in various use cases like customer support chatbots, legal research assistants, and healthcare advisors. In this collaboration, the AWS GenAIIC team created a RAG-based solution for Deltek to enable Q&A on single and multiple government solicitation documents.
Lets say the task at hand is to predict the root cause categories (Customer Education, Feature Request, Software Defect, Documentation Improvement, Security Awareness, and Billing Inquiry) for customer support cases. We suggest consulting LLM prompt engineering documentation such as Anthropic prompt engineering for experiments.
Such data often lacks the specialized knowledge contained in internal documents available in modern businesses, which is typically needed to get accurate answers in domains such as pharmaceutical research, financial investigation, and customer support. For example, imagine that you are planning next year’s strategy of an investment company.
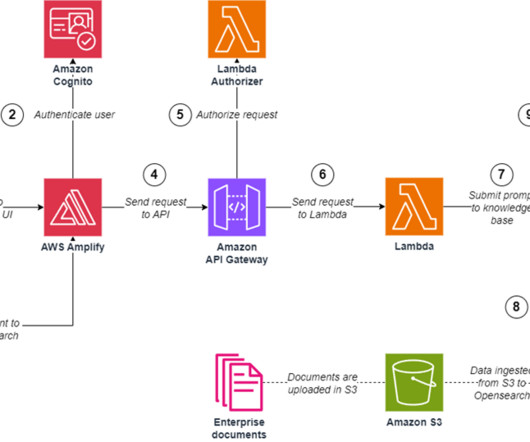
This post shows how to configure an Amazon Q Business custom connector and derive insights by creating a generative AI-powered conversation experience on AWS using Amazon Q Business while using access control lists (ACLs) to restrict access to documents based on user permissions. Who are the data stewards for my proprietary database sources?
Prerequisites To follow along and set up this solution, you must have the following: An AWS account A device with access to your AWS account with the following: Python 3.12 During the creation of the knowledge base, a vector store will also be created to ingest documents encoded as vectors, using an embeddings model.
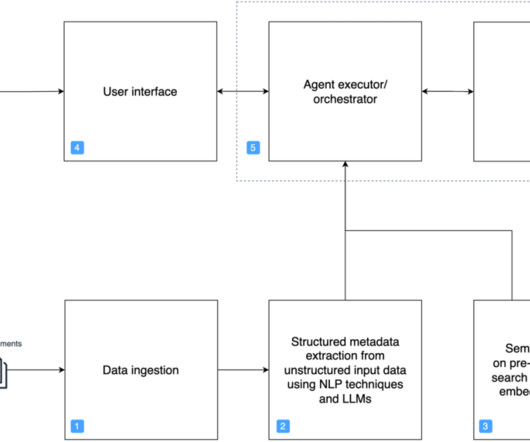
Organizations across industries such as retail, banking, finance, healthcare, manufacturing, and lending often have to deal with vast amounts of unstructured text documents coming from various sources, such as news, blogs, product reviews, customer support channels, and social media. Extract and analyze data from documents.
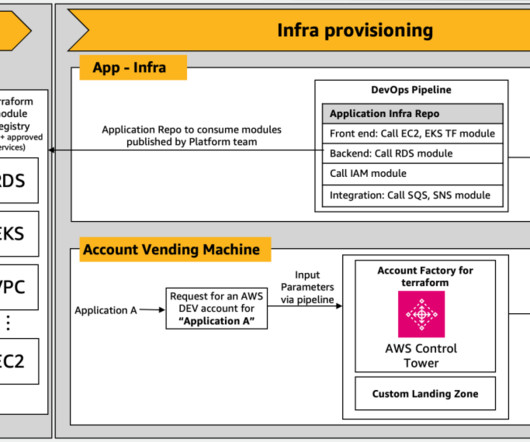
When designing production CI/CD pipelines, AWS recommends leveraging multiple accounts to isolate resources, contain security threats and simplify billing-and data science pipelines are no different. Some things to note in the preceding architecture: Accounts follow a principle of least privilege to follow security best practices.
Encourage agents to cheer up callers with more flexible scripting. “A 2014 survey suggested that 69% of customers feel that their call center experience improves when the customer service agent doesn’t sound as though they are reading from a script. Minimise language barriers with better hires.
Your task is to understand a system that takes in a list of documents, and based on that, answers a question by providing citations for the documents that it referred the answer from. Our dataset includes Q&A pairs with reference documents regarding AWS services. The following table shows an example.
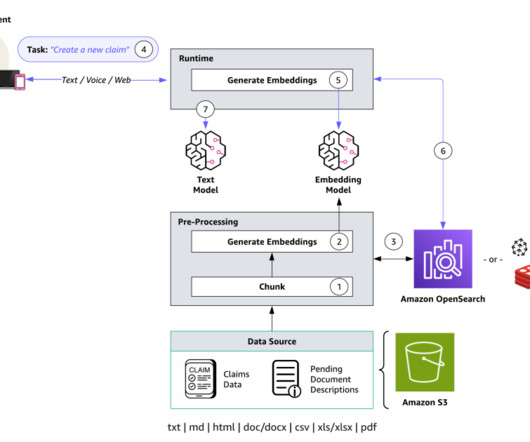
Prerequisites To implement the solution provided in this post, you should have the following: An active AWS account and familiarity with FMs, Amazon Bedrock, and OpenSearch Serverless. An S3 bucket where your documents are stored in a supported format (.txt,md,html,doc/docx,csv,xls/.xlsx,pdf). txt,md,html,doc/docx,csv,xls/.xlsx,pdf).
For early detection, implement custom testing scripts that run toxicity evaluations on new data and model outputs continuously. Integrating scheduled toxicity assessments and custom testing scripts into your development pipeline helps you continuously monitor and adjust model behavior.
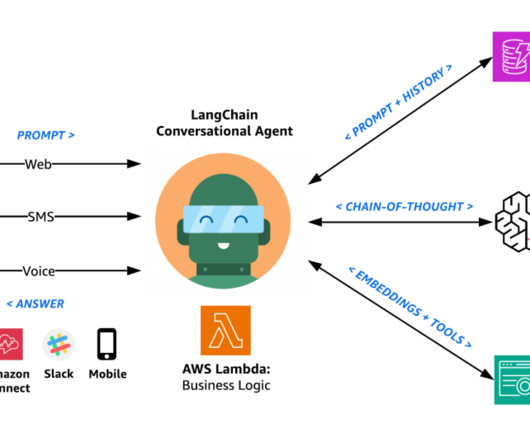
The agent can assist users with finding their account information, completing a loan application, or answering natural language questions while also citing sources for the provided answers. This memory allows the agent to provide responses that take into account the context of the ongoing conversation.
Accelerate research and analysis – Instead of manually searching through SharePoint documents, users can use Amazon Q to quickly find relevant information, summaries, and insights to support their research and decision-making. The site content space also provides access to add lists, pages, document libraries, and more.
Also make sure you have the account-level service limit for using ml.p4d.24xlarge The documents provided show that the development of these systems had a profound effect on the way people and goods were able to move around the world. You can change these configurations by specifying non-default values in JumpStartModel.
Your Amazon Bedrock-powered insurance agent can assist human agents by creating new claims, sending pending document reminders for open claims, gathering claims evidence, and searching for information across existing claims and customer knowledge repositories. Send a pending documents reminder to the policy holder of claim 2s34w-8x.
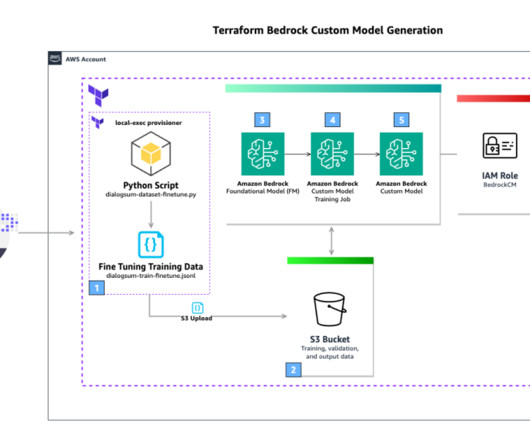
The workflow includes the following steps: The user runs the terraform apply The Terraform local-exec provisioner is used to run a Python script that downloads the public dataset DialogSum from the Hugging Face Hub. Prerequisites This solution requires the following prerequisites: An AWS account.
Prerequisites To build the solution yourself, there are the following prerequisites: You need an AWS account with an AWS Identity and Access Management (IAM) role that has permissions to manage resources created as part of the solution (for example AmazonSageMakerFullAccess and AmazonS3FullAccess ).
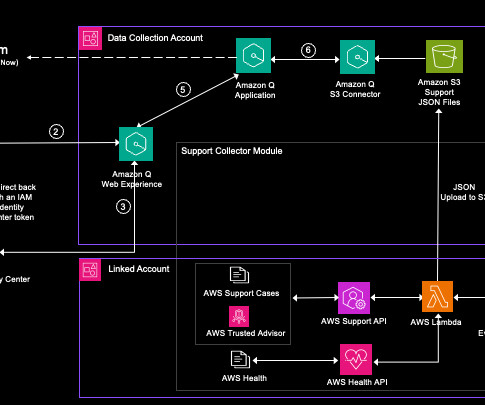
QSI enables insights on your AWS Support datasets across your AWS accounts. First, as illustrated in the Linked Accounts group in Figure 1, this solution supports datasets from linked accounts and aggregates your data using the various APIs, AWS Lambda , and Amazon EventBridge. Synchronize the data source to index the data.
Prerequisites For this walkthrough, you should have the following prerequisites: Familiarity with SageMaker Ground Truth labeling jobs and the workforce portal Familiarity with the AWS Cloud Development Kit (AWS CDK) An AWS account with the permissions to deploy the AWS CDK stack A SageMaker Ground Truth private workforce Python 3.9+
No matter how many Google accounts you sign up for, the process is the same every time. You can give your team a script that they either memorize or copy and paste. Juggling multiple documents and windows is cumbersome and inefficient. If you pay FedEx for overnight shipping, you know that package will be there the next day.
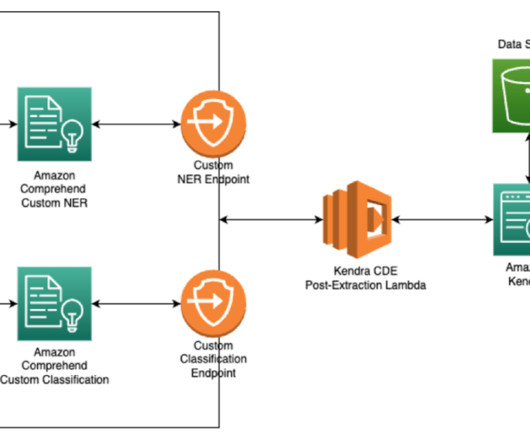
Amazon Kendra uses deep learning and reading comprehension to deliver precise answers, and returns a list of ranked documents that match the search query for you to choose from. We first ingest a set of documents, along with their metadata, into an Amazon Kendra index. Solution overview.
Typically, call scripts guide agents through calls and outline addressing issues. Well-written scripts improve compliance, reduce errors, and increase efficiency by helping agents quickly understand problems and solutions. In particular, complete the following prerequisite steps: Deploy an Amazon SageMaker domain.
This post takes you through the most common challenges that customers face when searching internal documents, and gives you concrete guidance on how AWS services can be used to create a generative AI conversational bot that makes internal information more useful. The cost associated with training models on recent data is high.
Amazon Q returns the response as a JSON object (detailed in the Amazon Q documentation ). sourceAttributions – The source documents used to generate the conversation response. In Retrieval Augmentation Generation (RAG), this always refers to one or more documents from enterprise knowledge bases that are indexed in Amazon Q.
By performing operations (applications, infrastructure) as code, you can provide consistent and reliable deployments in multiple AWS accounts and AWS Regions, and maintain versioned and auditable infrastructure configurations. For latest information, please refer to the documentation above.
It should be noted that both our question and LoyaltyOne’s only scratch the surface of this topic and also don’t (seem to) account for the difference in feelings people might have for industries that are generally expected to be open on holidays, like movie theaters and restaurants. Photo Credit: [link].
A typical RAG solution for knowledge retrieval from documents uses an embeddings model to convert the data from the data sources to embeddings and stores these embeddings in a vector database. When a user asks a question, it searches the vector database and retrieves documents that are most similar to the user’s query.
Once agents feel calm and ready to tackle even the most heated interactions, they can flip the script and use positive language with the customer. How agents can handle complainers (+ example scripts): Empathize. Read Next] The 6 live chat support scripts you need in your internal knowledge base. Commit to going the extra mile.
Batch transform The batch transform pipeline consists of the following steps: The pipeline implements a data preparation step that retrieves data from a PrestoDB instance (using a data preprocessing script ) and stores the batch data in Amazon Simple Storage Service (Amazon S3). Follow the instructions in the GitHub README.md
For instance, according to International Data Corporation (IDC), the world’s data volume is expected to increase tenfold by 2025, with unstructured data accounting for a significant portion. For example, you can provide search results for cities across the world, where documents are filtered by a specific city with which they are associated.
Vonage API Account. To complete this tutorial, you will need a Vonage API account. Once you have an account, you can find your API Key and API Secret at the top of the Vonage API Dashboard. Web Component polyfill --> <script src="[link]. <!-- ” The documentation has more info and offers alternatives.
For information on additional Slurm commands and configuration, refer to the Slurm Workload Manager documentation. Prerequisites Before you create your SageMaker HyperPod, you first need to configure your VPC, create an FSx for Lustre file system, and establish an S3 bucket with your desired cluster lifecycle scripts. Choose Save.
Use the supplied Python scripts for quantization. Run the provided Python test scripts to invoke the SageMaker endpoint for both INT8 and FP32 versions. To access the code and documentation, refer to the GitHub repo. For more information, refer to Lower Numerical Precision Deep Learning Inference and Training.
Live chat and text (combined) account of 27 percent of preferred service channels. For each chat, agents will need to reply to customer questions, research account activity and notes, troubleshoot any issues, provide supporting help documentation, and any number of other tasks. Doesn’t Need a Script.
Requiring customers to make a phone call to cancel or modify their account, when everything else can be done online, is infuriating. Tarek Khalil took to Twitter to document his quest to cancel his Baremetrics account. Be careful about scripting customer service responses too tightly. How Bare you?
Make sure the AWS account has a service quota for hosting a SageMaker endpoint for an ml.g5.2xlarge instance. You use the same script for downloading the model file when creating the SageMaker endpoint. Make sure your AWS Identity and Access Management (IAM) user has the necessary access permissions for creating a SageMaker role.
To achieve this multi-user environment, you can take advantage of Linux’s user and group mechanism and statically create multiple users on each instance through lifecycle scripts. Create a VPC, subnets, and a security group Follow the instructions in the Own Account section of the HyperPod workshop. strip(), pysss.password().AES_256))"
For details, see Creating an AWS account. Ensure sufficient capacity for this instance in your AWS account by requesting a quota increase if required. The script also merges the LoRA weights into the model weights after training. You can follow the steps in the documentation to enable model access.
SageMaker Profiler provides Python modules for annotating PyTorch or TensorFlow training scripts and activating SageMaker Profiler. You can also use optional custom annotations to add markers in the training script to visualize hardware activities during particular operations in each step. For more information, refer to documentation.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





































Let's personalize your content