This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
From essentials like average handle time to broader metrics such as call center service levels , there are dozens of metrics that call center leaders and QA teams must stay on top of, and they all provide visibility into some aspect of performance. Kaye Chapman @kayejchapman. First contact resolution (FCR) measures might be…”.
A reverse image search engine enables users to upload an image to find related information instead of using text-based queries. Solution overview The solution outlines how to build a reverse image search engine to retrieve similar images based on input image queries. Engine : Select nmslib. Distance metric : Select Euclidean.
For automatic model evaluation jobs, you can either use built-in datasets across three predefined metrics (accuracy, robustness, toxicity) or bring your own datasets. Regular evaluations allow you to adjust and steer the AI’s behavior based on feedback and performance metrics.
However, keeping track of numerous experiments, their parameters, metrics, and results can be difficult, especially when working on complex projects simultaneously. SageMaker is a comprehensive, fully managed ML service designed to provide data scientists and ML engineers with the tools they need to handle the entire ML workflow.
This approach allows organizations to assess their AI models effectiveness using pre-defined metrics, making sure that the technology aligns with their specific needs and objectives. Curated judge models : Amazon Bedrock provides pre-selected, high-quality evaluation models with optimized prompt engineering for accurate assessments.
By documenting the specific model versions, fine-tuning parameters, and prompt engineering techniques employed, teams can better understand the factors contributing to their AI systems performance. Evaluation algorithm Computes evaluation metrics to model outputs. Different algorithms have different metrics to be specified.
Observability refers to the ability to understand the internal state and behavior of a system by analyzing its outputs, logs, and metrics. Security – The solution uses AWS services and adheres to AWS Cloud Security best practices so your data remains within your AWS account.
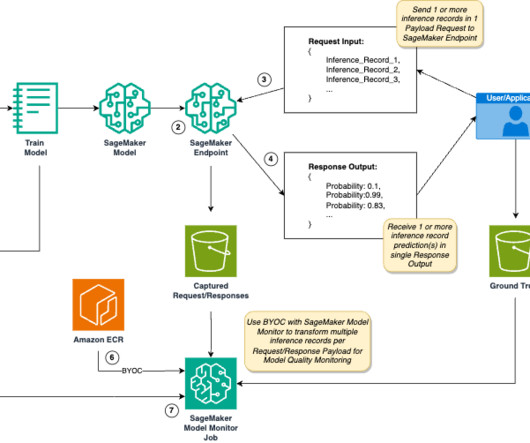
Examples include financial systems processing transaction data streams, recommendation engines processing user activity data, and computer vision models processing video frames. A preprocessor script is a capability of SageMaker Model Monitor to preprocess SageMaker endpoint data capture before creating metrics for model quality.
Datadog is excited to launch its Neuron integration , which pulls metrics collected by the Neuron SDK’s Neuron Monitor tool into Datadog, enabling you to track the performance of your Trainium and Inferentia based instances. If you don’t already have a Datadog account, you can sign up for a free 14-day trial today.
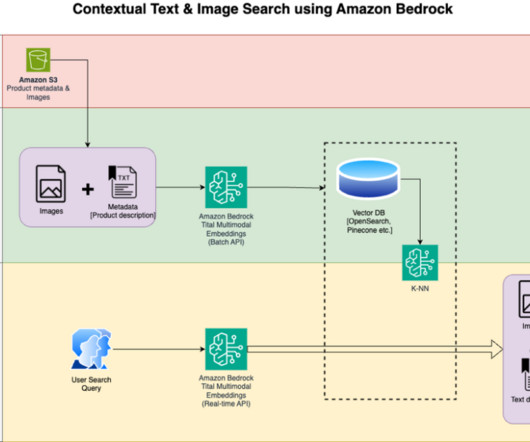
Search engines and recommendation systems powered by generative AI can improve the product search experience exponentially by understanding natural language queries and returning more accurate results. Amazon OpenSearch Service now supports the cosine similarity metric for k-NN indexes.
The solution proposed in this post relies on LLMs context learning capabilities and prompt engineering. The project also requires that the AWS account is bootstrapped to allow the deployment of the AWS CDK stack. Also note the completion metrics on the left pane, displaying latency, input/output tokens, and quality scores.
Amazon Lookout for Metrics is a fully managed service that uses machine learning (ML) to detect anomalies in virtually any time-series business or operational metrics—such as revenue performance, purchase transactions, and customer acquisition and retention rates—with no ML experience required.
Current RAG pipelines frequently employ similarity-based metrics such as ROUGE , BLEU , and BERTScore to assess the quality of the generated responses, which is essential for refining and enhancing the models capabilities. More sophisticated metrics are needed to evaluate factual alignment and accuracy.
This requirement translates into time and effort investment of trained personnel, who could be support engineers or other technical staff, to review tens of thousands of support cases to arrive at an even distribution of 3,000 per category. If the use case doesnt yield discrete outputs, task-specific metrics are more appropriate.
Although automated metrics are fast and cost-effective, they can only evaluate the correctness of an AI response, without capturing other evaluation dimensions or providing explanations of why an answer is problematic. Human evaluation, although thorough, is time-consuming and expensive at scale.
The ability to quickly retrieve and analyze session data empowers developers to optimize their applications based on actual usage patterns and performance metrics. Prerequisites To follow along with this post, you need an AWS account with the appropriate permissions. He enjoys playing tennis and biking on mountain trails.
One aspect of this data preparation is feature engineering. Feature engineering refers to the process where relevant variables are identified, selected, and manipulated to transform the raw data into more useful and usable forms for use with the ML algorithm used to train a model and perform inference against it.
SageMaker JumpStart is a machine learning (ML) hub that provides a wide range of publicly available and proprietary FMs from providers such as AI21 Labs, Cohere, Hugging Face, Meta, and Stability AI, which you can deploy to SageMaker endpoints in your own AWS account. They’re illustrated in the following figure.
Compound AI system and the DSPy framework With the rise of generative AI, scientists and engineers face a much more complex scenario to develop and maintain AI solutions, compared to classic predictive AI. DSPy supports iteratively optimizing all prompts involved against defined metrics for the end-to-end compound AI solution.
So much exposure naturally brings added risks like account takeover (ATO). Each year, bad actors compromise billions of accounts through stolen credentials, phishing, social engineering, and multiple forms of ATO. To put it into perspective: account takeover fraud increased by 90% to an estimated $11.4
Automated safety guards Integrated Amazon CloudWatch alarms monitor metrics on an inference component. AlarmName This CloudWatch alarm is configured to monitor metrics on an InferenceComponent. For more information, check out the SageMaker AI documentation or connect with your AWS account team.
How do Amazon Nova Micro and Amazon Nova Lite perform against GPT-4o mini in these same metrics? Vector database FloTorch selected Amazon OpenSearch Service as a vector database for its high-performance metrics. How well do these models handle RAG use cases across different industry domains? Each provisioned node was r7g.4xlarge,
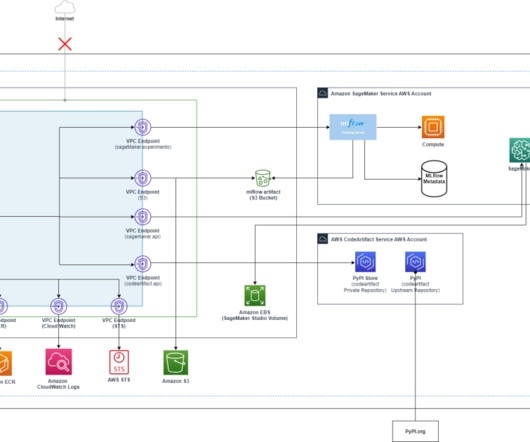
We implemented an AWS multi-account strategy, standing up Amazon SageMaker Studio in a build account using a network-isolated Amazon VPC. The solution consists of the following components: Data ingestion: Data is ingested into the data account from on-premises and external sources. Analytic data is stored in Amazon Redshift.
When designing production CI/CD pipelines, AWS recommends leveraging multiple accounts to isolate resources, contain security threats and simplify billing-and data science pipelines are no different. Some things to note in the preceding architecture: Accounts follow a principle of least privilege to follow security best practices.
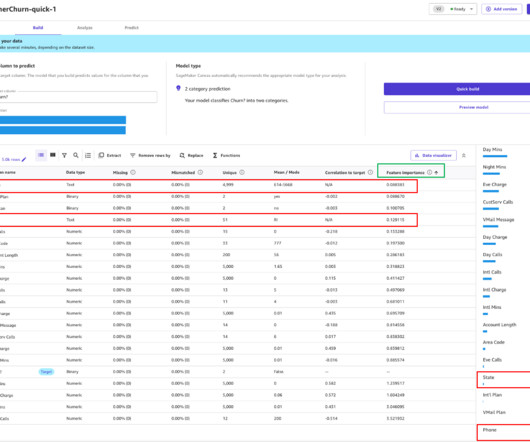
It also enables you to evaluate the models using advanced metrics as if you were a data scientist. In this post, we show how a business analyst can evaluate and understand a classification churn model created with SageMaker Canvas using the Advanced metrics tab. The F1 score provides a balanced evaluation of the model’s performance.
Amazon Q Business only provides metric information that you can use to monitor your data source sync jobs. Prerequisites For this walkthrough, you should have the following prerequisites: An AWS account Access to the Alation service with the ability to create new policies and access tokens.
We are excited to launch a causal contribution analysis capability in Amazon Lookout for Metrics that helps you to understand the potential root causes for the business-critical anomalies in the data. Lookout for Metrics reduces the time to implement AI/ML services for business-critical problems.
Previously, OfferUps search engine was built with Elasticsearch (v7.10) on Amazon Elastic Compute Cloud (Amazon EC2), using a keyword search algorithm to find relevant listings. These challenges include: Context understanding Keyword searches dont account for the context in which a term is used.
Additionally, evaluation can identify potential biases, hallucinations, inconsistencies, or factual errors that may arise from the integration of external sources or from sub-optimal prompt engineering. This makes it difficult to apply standard evaluation metrics like BERTScore ( Zhang et al.
Prerequisites To build the solution yourself, there are the following prerequisites: You need an AWS account with an AWS Identity and Access Management (IAM) role that has permissions to manage resources created as part of the solution (for example AmazonSageMakerFullAccess and AmazonS3FullAccess ).
Proactive quality control is the engine that powers this positive cycle. This fosters a sense of shared ownership and accountability. Regular Meetings: Conduct regular business reviews to track progress on action plans, discuss performance metrics, and address any roadblocks that may arise.
Recall@5 is a specific metric used in information retrieval evaluation, including in the BEIR benchmark. Breanne holds a Bachelor of Science in Computer Engineering from University of Illinois at Urbana Champaign. If so, skip to the next section in this post. Deployment starts when you choose the Deploy option.
Our field organization includes customer-facing teams (account managers, solutions architects, specialists) and internal support functions (sales operations). Personalized content will be generated at every step, and collaboration within account teams will be seamless with a complete, up-to-date view of the customer.
Every trend points to customer success becoming the growth engine of businesses, and since customer success typically owns NRR (net revenue retention) , tracking how the teams investments impact performance is also part of that need. 1: You notice your CRM holding your team back. Meetings or calls with that hard-to-reach customer.
This is guest post by Andy Whittle, Principal Platform Engineer – Application & Reliability Frameworks at The Very Group. However, this can mean processing customer data in the form of personally identifiable information (PII) in relation to activities such as purchases, returns, use of flexible payment options, and account management.
Three tricks we used to accomplish this include: Be RACI: Using a responsibility assignment matrix (aka a RACI—Responsible, Accountable, Consulted, Informed—matrix) has helped us to clearly define the roles and responsibilities between our CS and sales teams. At the same time, you can build out new opportunities to drive that value.
The most important mindset shift I made as a CRO is recognizing that CS isnt a revenue centerits a value engine. The metrics were great. Had I not also sat down with the CS team, I would have missed a lot of the factors that allowed us to have that metric. Revenue is the outcome, not the input.
This process enhances task-specific model performance, allowing the model to handle custom use cases with task-specific performance metrics that meet or surpass more powerful models like Anthropic Claude 3 Sonnet or Anthropic Claude 3 Opus. Under Output data , for S3 location , enter the S3 path for the bucket storing fine-tuning metrics.
About the Authors Nick Biso is a Machine Learning Engineer at AWS Professional Services. He solves complex organizational and technical challenges using data science and engineering. In addition, he builds and deploys AI/ML models on the AWS Cloud. His passion extends to his proclivity for travel and diverse cultural experiences.
There are unique considerations when engineering generative AI workloads through a resilience lens. If you’re performing prompt engineering, you should persist your prompts to a reliable data store. In the low-latency case, you need to account for the time it takes to generate the embedding vectors.
These systems manage basic tasks like appointment scheduling, payment processing, and account inquiries without human intervention. Smart routing systems direct calls to the most qualified agents based on skills, availability, and past performance metrics. This creates a more efficient workflow and reduces customer wait times.
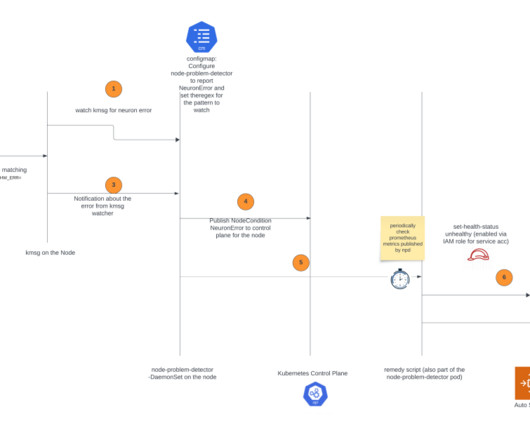
The node recovery agent is a separate component that periodically checks the Prometheus metrics exposed by the node problem detector. Additionally, the node recovery agent will publish Amazon CloudWatch metrics for users to monitor and alert on these events. You can see the CloudWatch NeuronHasError_DMA_ERROR metric has the value 1.
In this part of the blog series, we review techniques of prompt engineering and Retrieval Augmented Generation (RAG) that can be employed to accomplish the task of clinical report summarization by using Amazon Bedrock. Prompt engineering helps to effectively design and improve prompts to get better results on different tasks with LLMs.
This enables data scientists to quickly build and iterate on ML models, and empowers ML engineers to run through continuous integration and continuous delivery (CI/CD) ML pipelines faster, decreasing time to production for models. Solution overview The proposed framework code starts by reading the configuration files. The model_unit.py
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content