
Governing the ML lifecycle at scale, Part 3: Setting up data governance at scale
AWS Machine Learning
NOVEMBER 22, 2024
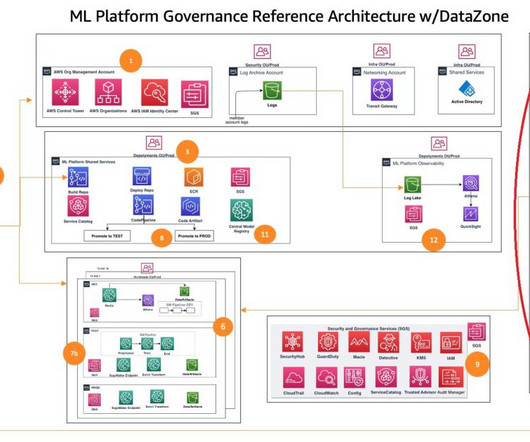
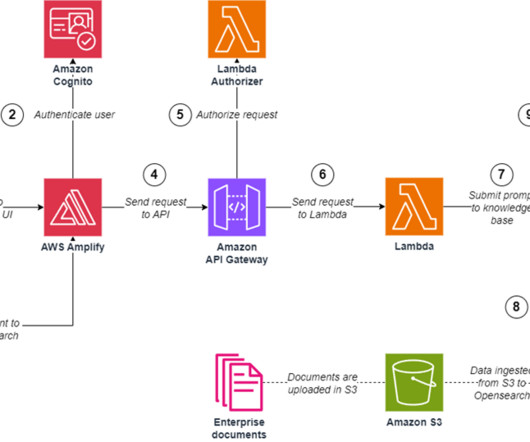
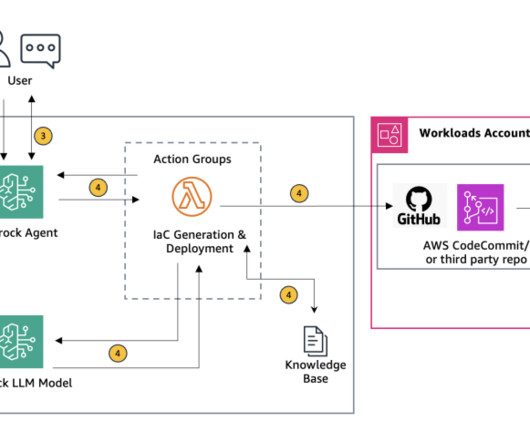
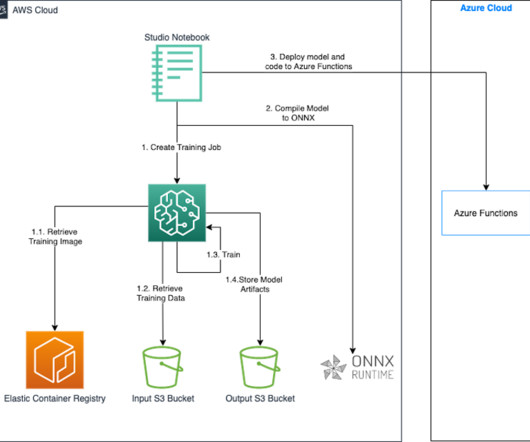
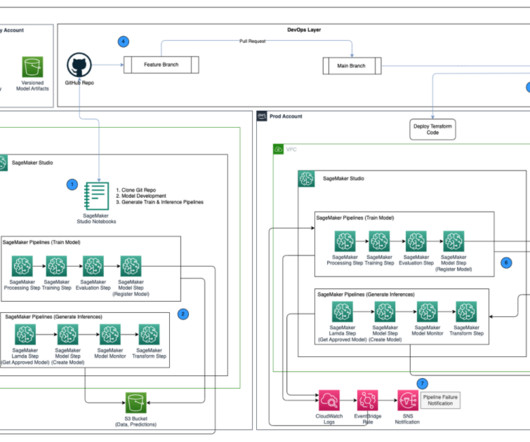
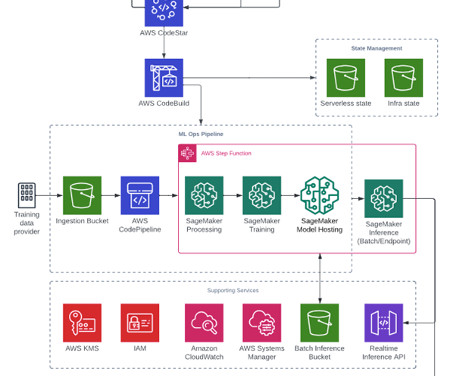
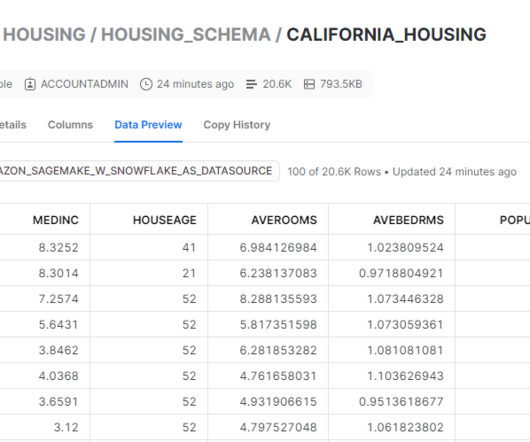
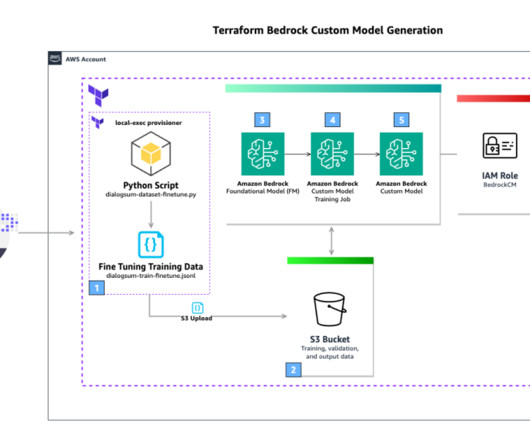
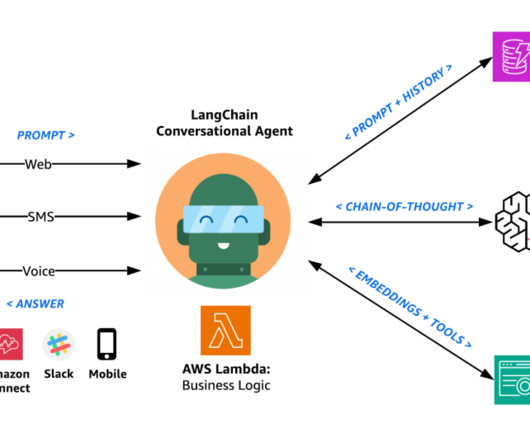
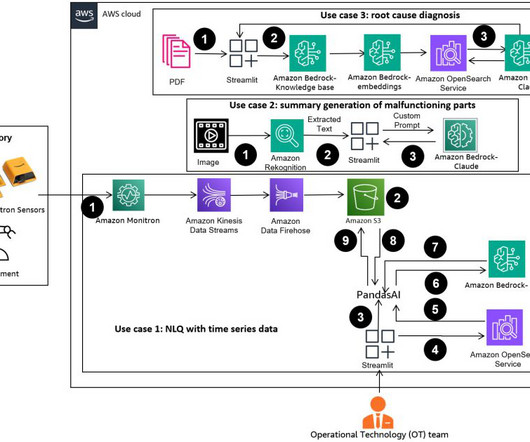
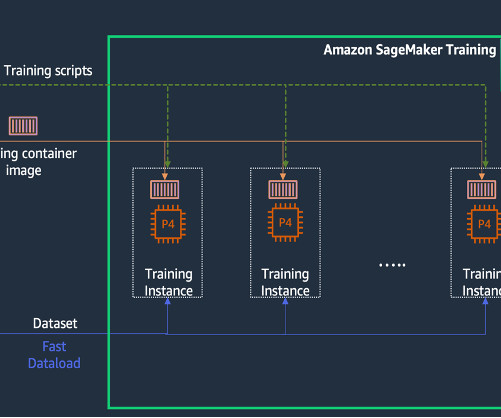
Challenges in data management Traditionally, managing and governing data across multiple systems involved tedious manual processes, custom scripts, and disconnected tools. The diagram shows several accounts and personas as part of the overall infrastructure. The following diagram gives a high-level illustration of the use case.




























Let's personalize your content