This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
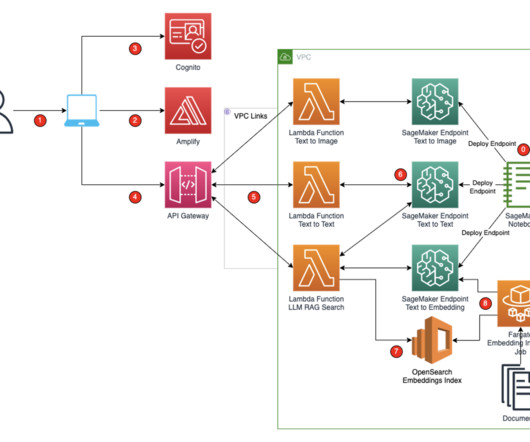
We also explore best practices for optimizing your batch inference workflows on Amazon Bedrock, helping you maximize the value of your data across different use cases and industries. Solution overview The batch inference feature in Amazon Bedrock provides a scalable solution for processing large volumes of data across various domains.
For this example, we use train.cc_casebooks.jsonl.xz Prerequisites Before getting started, make sure you have the following prerequisites: An AWS account. For more information, refer to Amazon SageMaker Identity-Based Policy Examples. This dataset is a large corpus of legal and administrative data. within this repository.
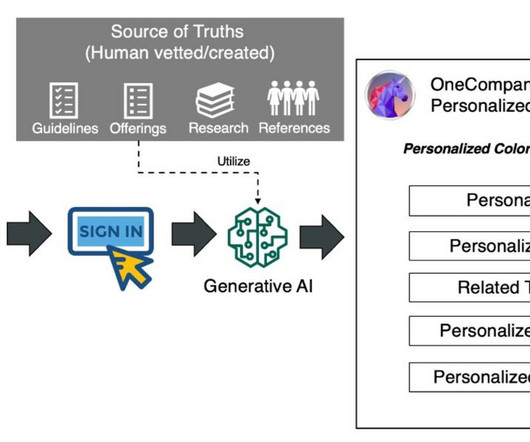
The following is an example of a synthetically generated offering for the construction industry: OneCompany Consulting Construction Consulting Services Offerings Introduction OneCompany Consulting is a premier construction consulting firm dedicated to. Our examples were manually created only for high-level guidance for simplicity.
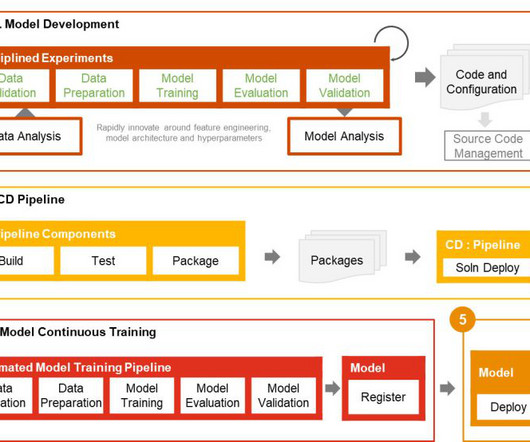
Customers can configure an AWS account, the repository, the model, the data used, the pipeline name, the training framework, the number of instances to use for training, the inference framework, and any pre- and post-processing steps and several other configurations to check the model quality, bias, and explainability.
According to a Forbes survey , there is widespread consensus among ML practitioners that data preparation accounts for approximately 80% of the time spent in developing a viable ML model. To demonstrate the orchestrated workflow, we use an example dataset regarding diabetic patient readmission. Prerequisites. An S3 bucket.
This post also provides an example end-to-end notebook and GitHub repository that demonstrates SageMaker geospatial capabilities, including ML-based farm field segmentation and pre-trained geospatial models for agriculture. This example user interface depicts common geospatial data overlays consumed by farmers and agricultural stakeholders.
We include an example of how to use the decorator function and the associated settings later in this post. In the following example code, we run a simple divide function as a SageMaker Training job: import boto3 import sagemaker from sagemaker.remote_function import remote sm_session = sagemaker.Session(boto_session=boto3.session.Session(region_name="us-west-2"))
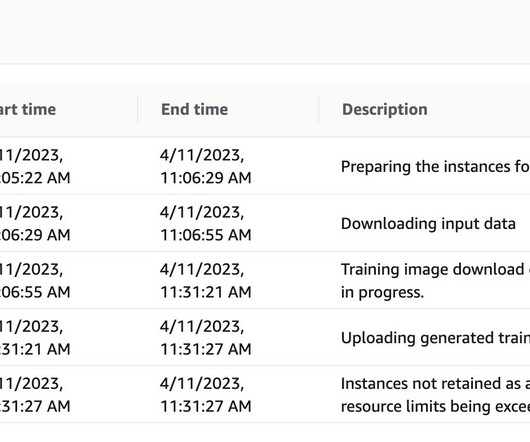
The drift notification emails will look similar to the examples in Figure 8. Across accounts, automate deployment using export and import dataset, data source, and analysis API calls provided by QuickSight. About the Authors Stephen Randolph is a Senior Partner Solutions Architect at Amazon Web Services (AWS).
In later years, STIR/SHAKEN was developed jointly by the SIP Forum and the Alliance for Telecommunications IndustrySolutions (ATIS) to efficiently implement the Internet Engineering Task Force (IETF). In 1984, the idea got its first public trial with Bell Atlantic and a follow-up in 1987.
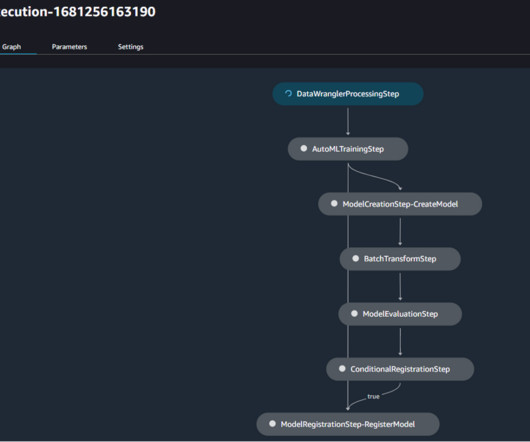
The majority of enterprise customers already have a well-established MLOps practice with a standardized environment in place—for example, a standardized repository, infrastructure, and security guardrails—and want to extend their MLOps process to no-code and low-code AutoML tools as well. For this post, you use a CloudFormation template.
The context will be coming from your RAG solutions like Amazon Bedrock Knowledgebases. For this example, we take a sample context and add to demo the concept: input_output_demarkation_key = "nn### Response:n" question = "Tell me what was the improved inflow value of cash?" See Amazon Bedrock Recipes and GitHub for more examples.
Lastly, install Docker based on your operating system: Mac – Install Docker Desktop on Mac Windows – Install Docker Desktop on Windows Deploy the application to the AWS Cloud This reference solution is available on GitHub, and you can deploy it with the AWS CDK. Make sure to match the work team name in the same AWS Region and account.
To address this challenge, this post demonstrates a proactive approach for security vulnerability assessment of your accounts and workloads, using Amazon GuardDuty , Amazon Bedrock , and other AWS serverless technologies. The example rule in the following screenshot filters high-severity findings at severity level 8 and above.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















Let's personalize your content