This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
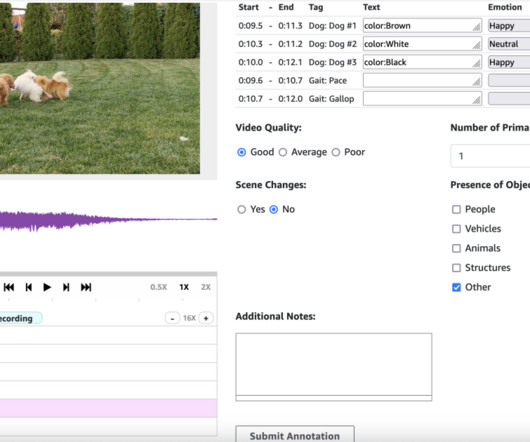
Audio and video segmentation provides a structured way to gather this detailed feedback, allowing models to learn through reinforcement learning from human feedback (RLHF) and supervised fine-tuning (SFT). The path to creating effective AI models for audio and video generation presents several distinct challenges.
Amazon has introduced two new creative content generation models on Amazon Bedrock : Amazon Nova Canvas for image generation and Amazon Nova Reel for video creation. These models transform text and image inputs into custom visuals, opening up creative opportunities for both professional and personal projects.
Within 30 minutes of the scheduled call, you make them a quick self-recorded video thanking them and sharing your excitement. Step 3: Due to your generosity, personalized advisory, and ability to identify and solve their problems for free up-front, they decide to sign up with you five days later. Conclusion.
Watch Colin talking about this on YouTube: Subscribe to our YouTube channel here to see all the latest videos! They were asking for the account number right off the bat. The senior managers thought customers would be ready to present their account numbers upon getting through the call center queue.
Nevertheless, we treat them as if they’re an entity, almost human-like, and we form something close to a personal connection with them. Forming an attachment is vital, here, establishing an Emotional Bank account. Watch Colin talking about this on YouTube: Subscribe to our YouTube channel here to see all the latest videos!
You should understand Mental Accounting as it pertains to customer behavior before you set the price and before you ruin how your customers feel about your experience. So, What is Mental Accounting? Airlines Run Mental Accounting Too Often in the Red. How else is a person going to pay for an airline ticket in 2018?
Let’s imagine that you’re an account manager with 200 customers. If you know that 80 percent of your revenue comes from 20 percent of those customers, what do you think happens to the other 80 percent that only accounts for 20 percent of the revenue? I understand this concept from personal experience.
Video chat assistance is on the rise. “FaceTime video chatting was just the beginning. Video customer service is coming. Requests are coming in from clients who want to offer video customer service. One-way video chatting (they see our agent, but the agent does not see them) or an app could be used to offer this.
Engage with video. Video helps store information for more extended periods than other forms, such as audio and kinesthetic learning. Video helps store information for more extended periods than other forms, such as audio and kinesthetic learning. I have dozens of YouTube videos you can use in your training.
In brief, the study asked a number of participants to “drive” a car in a video game and they measured several factors, including speed, power, aggressive behavior and risk-taking. Back in 2011, Boston College performed an interesting study involving everyone’s favorite energy drink, Red Bull, and the behavior it evoked in study participants.
Video Chat. Consider incorporating video chat if you have not already done so. According to an IPSOS survey in May 2020, 57% of Americans regularly used video chat. 38% of respondents had never used this channel before the outbreak, but 85% could see themselves using video chat going forward. Self-Help Channels.
This brief 2-minute video shares some of the ways Nudges do work: In each of the video’s examples, you can see how nudging works best when it works with our natural instincts. A good example is in personalizing a text from a job center that booked interviews for candidates. When Nudges Work, They Work Well. Attractive.
In Florida, the sheer volume of vehicle-related injuries in 2023, totaling 250,037, underscores the need for effective management of personal injury claims. Ensuring that every aspect of your injury, including future medical needs, is accounted for in your claim is crucial.
And if the employee that handles the interaction is more engaging and personable, then, what’s there to get your knickers in a twist about? do not have a bank account at an insured institution (unbanked), which translates to about nine million households. Per the CBS New story, at least in the U.S., households, around 24.5
Embedd this video in blog. And you probably felt a little embarrassed for the person. Like any tone of voice, it works best if it carries through to all aspects of a business’s marketing efforts, from advertisements to product packaging, to in-store displays and social media accounts. The video quickly went viral.
ByteDance, the parent company that owns TikTok, found that the most viral videos are 22 seconds long. Your audience needs to watch until the end of the video. Spark Ads performs differently than if you were to post from your brand account because everything on TikTok needs to feel human and personal. Advertise on TikTok.
So as we go through these four theories of humor, let’s consider how we can apply these concepts to business, whether through the contact center, account management, or marketing. . Other examples would be physical comedy, like Fails videos where you watch people slip and fall or crash their go carts or break their ceiling fans.
Most people applied shocks marked “XXX” to the other person merely because the person telling them to was wearing a white lab coat, an icon of authority. Whether firm or soft, the intensity communicates clues about your personality—and these opinions tend to correlate with your grip. 2: Practice my handshake. Maybe or maybe not.
Here is an example: If you didn’t watch the video, I summarized five of the excuses he mentions: So, going out of my drive this morning, I drove straight into a bus. It might reflect real or fabricated circumstances, but its main purpose is to shield somebody from accountability. So, I am not a rude person; it was just a bad moment.
It’s mentally, emotionally, and physically draining, and it’s so easy and tempting to push aside our personal health while we’re focused on our jobs. Or to keep track of all your personal to-do items. There are tons of great options out there, but my personal favorite is Asana. A Unified Communication/Video Tool.
In today’s data-driven world, industries across various sectors are accumulating massive amounts of video data through cameras installed in their warehouses, clinics, roads, metro stations, stores, factories, or even private facilities. It enables real-time video ingestion, storage, encoding, and streaming across devices.
Personalized customer experiences are essential for engaging today’s users. However, delivering truly personalized experiences that adapt to changes in user behavior can be both challenging and time-consuming. A higher coverage means Amazon Personalize recommends more of your catalog. compared to previous versions.
By using social accounts for addressing all kinds of customer queries, companies are expanding their customer experience strategy. . Brands like Starbucks use their parent Twitter account to address complaints and generally talk to customers. Netflix has a dedicated Twitter account called NetflixHelps to respond to customer complaints.
Ali Cudby , CEO of Alignment Growth Strategies , a Customer Experience consultancy, sent us a video about human and AI relationships and how to leverage AI to build customer relationships. Let’s play the video : I found that video helpful in considering how to use AI to build an experience.
These assistive technologies provide employees with hints, prompts, tips and even personalized promotions based on real-time, dynamic interpretation of what the customer needs or would find appealing. The superagent can easily shift between channels such as video, voice and text to make each interaction sound authentic and personal.
They offer free deliveries, Amazon Prime Video, Amazon Prime Music and also Amazon Prime Reading. Let me share a few tips from my personal experiences of how you can achieve this with absolute ease. I gave them my feedback, and I felt like they actually cared and will take those recommendations into account for future guests.
But it turns out that just 10 percent of its shoppers account for half of its sales! Potentially, then, a trip to Walmart on a party day becomes something more than a race to get the last of the video game consoles on sale. This kind of personal touch gives customers a reason to come into the store instead of shopping online.
For example, if a customer asks a basic Agentic AI to reset their account password, the AI can follow a predefined sequence of steps to complete the task with little variation. They started with account balance inquiries and system outage updates. Make autonomous decisions that result in more complex, personalized solutions for users.
It’s mentally, emotionally, and physically draining, and it’s so easy and tempting to push aside our personal health while we’re focused on our jobs. Or to keep track of all your personal to-do items. There are tons of great options out there, but my personal favorite is Asana. A Unified Communication/Video Tool.
Transforming raw data into a format that is suitable for a model is key to getting better personalized recommendations for end-users. To be able to develop this understanding of users, Amazon Personalize needs to train on the historical user behavior so that it can find patterns that are generalizable towards the future.
Instant communication, visual options (images, videos), and the ability to respond anytime, anywhere, make it one of the most customer-friendly channels available today. Link your WhatsApp Business account to your organization’s professional phone number for added credibility. With WhatsApp: Address customers by their name.
Facial expression analysis uses these landmarks to determine if the person is showing joy or sadness or anger. They didn’t record video and the participants were anonymous. Google used to mine all kinds of data from people’s Gmail accounts and people were OK with that because they got free email. So, Is it Creepy?
Amazon Personalize is excited to announce the new Trending-Now recipe to help you recommend items gaining popularity at the fastest pace among your users. Amazon Personalize is a fully managed machine learning (ML) service that makes it easy for developers to deliver personalized experiences to their users.
Top Takeaways: TIM’S GENEROUS GIFT : To start with, Tim has offered a free video course on body language. The brain loves to use shortcuts, so if it associates a person with the word “yes,” then the relationship is strengthened. Starting the conversation with agreement puts the person on the other end at ease right off the bat.
This personalized service leads to a higher perception of quality, and if your IVR can tap into your customer data from other channels, previous interactions, and your CRM, each call can be a quality experience. The IVR can link back to your customer data, modify survey questions in real-time, and collect personalized feedback.
So how can service organizations find the right long-term cost optimizations that will make an impact on the bottom line while still ensuring effective and fast service that takes into account COVID-19’s safety demands ? Two words: visual assistance. Visual Assistance in Customer Service. Visual Assistance in Self-Service.
From AI-powered chatbots to hyper-personalization, and with the aid of knowledge-base management solutions , the future of customer service is bright and full of potential. With the switch-to-video feature, customers can seamlessly switch to a live video chat with a customer service representative without leaving their preferred channel.
Personalization in customer service – What is it and how to deliver it 71% of consumers expect companies to deliver personalized interactions, according to the latest McKinsey & Co. To achieve this, organizations must deliver support that is fast, convenient, and now more than ever – personalized.
Businesses today heavily rely on video conferencing platforms for effective communication, collaboration, and decision-making. AWS account – You’ll need an active AWS account. Enable Claude Anthropic models – These models should be enabled in your AWS account. I am your account executive here at Aws. spk_0: Yeah.
While working remotely, I have been in online meetings where people are missing because they failed to take time zone differences into account. That is faulty thinking regardless of whether you’re leading in-person or in a virtual leadership role. Yep, I’m guilty of all these virtual leadership sins!
Watch Colin talking about this on YouTube: Subscribe to our YouTube channel here to see all the latest videos! The CEO once told me that the only thing he would have done differently would have been to put a measure in every person’s compensation tied to customer experience metrics from the beginning. NICE Systems, Inc.,
It’s mentally, emotionally, and physically draining, and it’s so easy and tempting to push aside our personal health while we’re focused on our jobs. Or to keep track of all your personal to-do items. There are tons of great options out there, but my personal favorite is Asana. We’re doing really hard work!
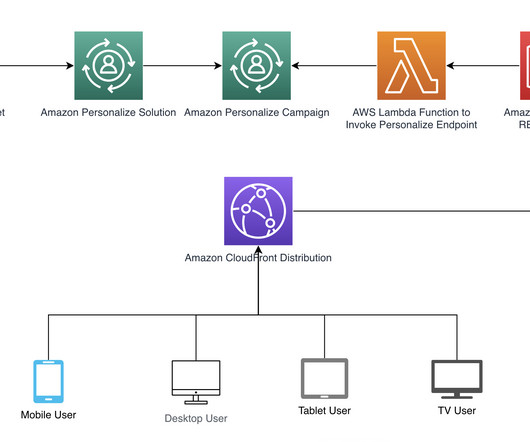
In this post, we show how to use the user’s current device type as context to enhance the effectiveness of your Amazon Personalize -based recommendations. Although this post shows how Amazon Personalize can be used for a video on demand (VOD) use case, it’s worth noting that Amazon Personalize can be used across multiple industries.
Onboarding Training Welcome new customers with informative guides, video tutorials , and walk-throughs to help them get started smoothly. For instance, a fitness equipment brand offering personalized workout plans and video demonstrations encourages long-term use of their products while building community trust.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content