This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this post, we explore how you can use Amazon Bedrock to generate high-quality categorical ground truth data, which is crucial for training machine learning (ML) models in a cost-sensitive environment. This results in an imbalanced class distribution for training and test datasets.
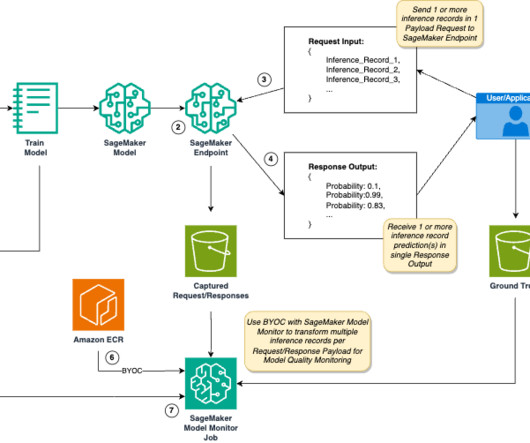
A preprocessor script is a capability of SageMaker Model Monitor to preprocess SageMaker endpoint data capture before creating metrics for model quality. However, even with a preprocessor script, you still face a mismatch in the designed behavior of SageMaker Model Monitor, which expects one inference payload per request.
What makes live chat scripts so important for sales and customer service? To realize all the benefits of live chat scripts, you need to understand the importance of chat etiquette for your customers’ experience and satisfaction. Useful Customer Service Scripts Templates And Examples. Customer Service Greetings Scripts.
Organizations typically counter these hurdles by investing in extensive training programs or hiring specialized personnel, which often leads to increased costs and delayed migration timelines. Traditionally, cloud engineers learning IaC would manually sift through documentation and best practices to write compliant IaC scripts.
If Artificial Intelligence for businesses is a red-hot topic in C-suites, AI for customer engagement and contact center customer service is white hot. This white paper covers specific areas in this domain that offer potential for transformational ROI, and a fast, zero-risk way to innovate with AI.
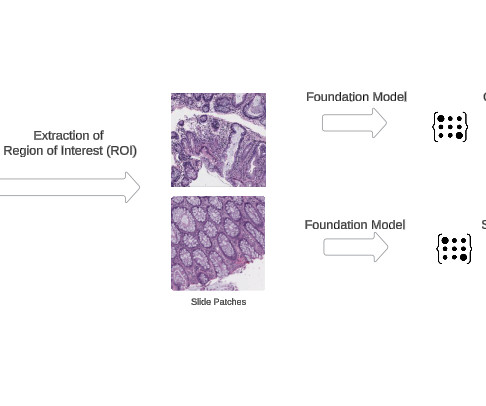
These models are trained using self-supervised learning algorithms on expansive datasets, enabling them to capture a comprehensive repertoire of visual representations and patterns inherent within pathology images. Prerequisites We assume you have access to and are authenticated in an AWS account.
The question is, can call centers improve agents’ emotional intelligence through training and employee engagement strategies ? A customer service agent trained to use empathy in their interactions has the power to develop a relationship with you even over the phone. Train your agents’ empathy skills with these 5 tips: 1.
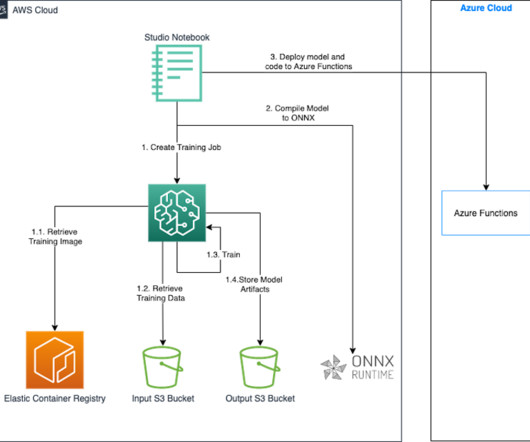
For example, you may want to make use of Amazon SageMaker to build and train ML model, or use Amazon SageMaker Jumpstart to deploy pre-built foundation or third party ML models, which you can deploy at the click of a few buttons. We show how you can build and train an ML model in AWS and deploy the model in another platform.
After writing over one thousand call center scripts, we know that there isn’t a single stand-alone ingredient we’d consider the ‘secret sauce’ for creating the perfect script. Instead, scripts are purposeful and serve as a guide to accomplish the objective of the call. No, it doesn’t.
Building foundation models (FMs) requires building, maintaining, and optimizing large clusters to train models with tens to hundreds of billions of parameters on vast amounts of data. Customers such as Stability AI use SageMaker HyperPod to train their foundation models, including Stable Diffusion.
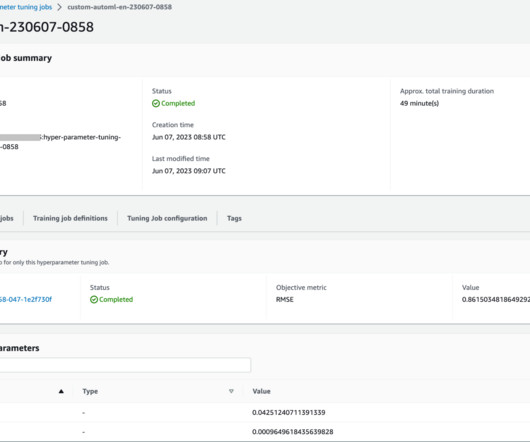
The success of any machine learning (ML) pipeline depends not just on the quality of model used, but also the ability to train and iterate upon this model. However, doing this tuning manually can often be cumbersome due to the size of the search space, sometimes involving thousands of training iterations. Solution overview.
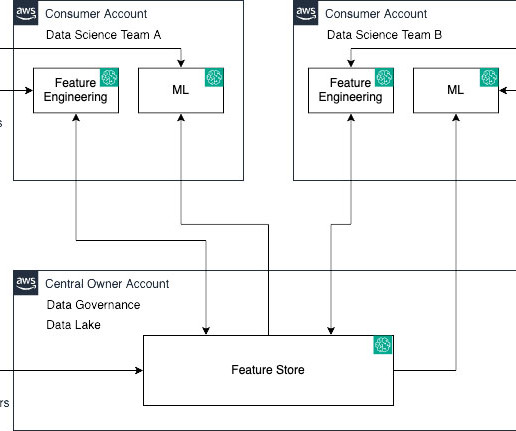
Features are inputs to ML models used during training and inference. Also, when features used to train models offline in batch are made available for real-time inference, it’s hard to keep the two feature stores synchronized. For a deep dive, refer to Cross account feature group discoverability and access.
For early detection, implement custom testing scripts that run toxicity evaluations on new data and model outputs continuously. Integrating scheduled toxicity assessments and custom testing scripts into your development pipeline helps you continuously monitor and adjust model behavior.
This vision model developed by KT relies on a model pre-trained with a large amount of unlabeled image data to analyze the nutritional content and calorie information of various foods. The teacher model remains unchanged during KD, but the student model is trained using the output logits of the teacher model as labels to calculate loss.
It is important to consider the massive amount of compute often required to train these models. When using compute clusters of massive size, a single failure can often throw a training job off course and may require multiple hours of discovery and remediation from customers. In recent years, FM sizes have been increasing.
Trained on broad, generic datasets spanning a wide range of topics and domains, LLMs use their parametric knowledge to perform increasingly complex and versatile tasks across multiple business use cases. For details, refer to Creating an AWS account. We use JupyterLab in Amazon SageMaker Studio running on an ml.t3.medium
With the right training, they can, and the humans will continue to do the jobs that AI isn’t ready to handle. A superagent will be a fast consumer of data and information, making them contextually aware of customer situations — and never needing to rely on a prepackaged script. Fewer phone calls, but more complex conversations.
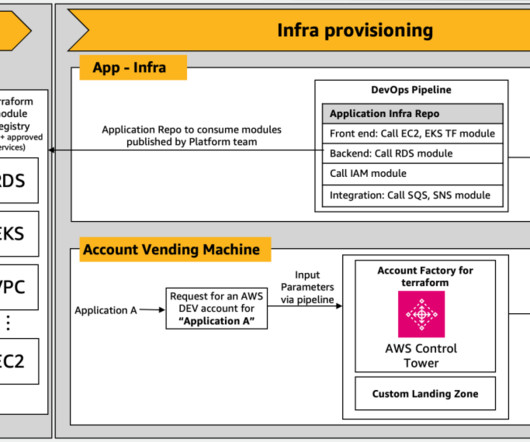
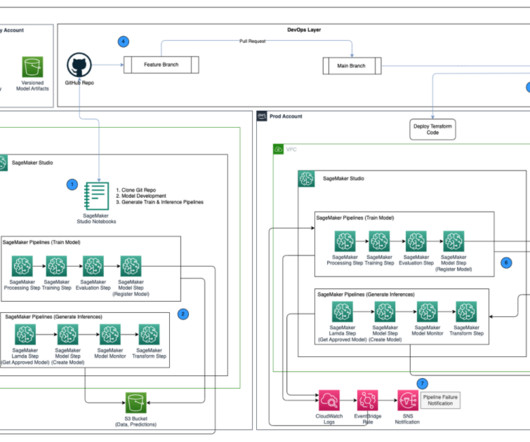
When designing production CI/CD pipelines, AWS recommends leveraging multiple accounts to isolate resources, contain security threats and simplify billing-and data science pipelines are no different. Some things to note in the preceding architecture: Accounts follow a principle of least privilege to follow security best practices.
It comes in a range of parameter sizes—7 billion, 13 billion, and 70 billion—as well as pre-trained and fine-tuned variations. Many practitioners fine-tune or pre-train these Llama 2 models with their own text data to improve accuracy for their specific use case.
Outbound call centers depend on skilled and well-trained agents as much as useful software to consistently meet business goals. Call centers that implement agent performance management solutions equip their agents with the ongoing coaching and training needed to perform at their best. Aim to connect.
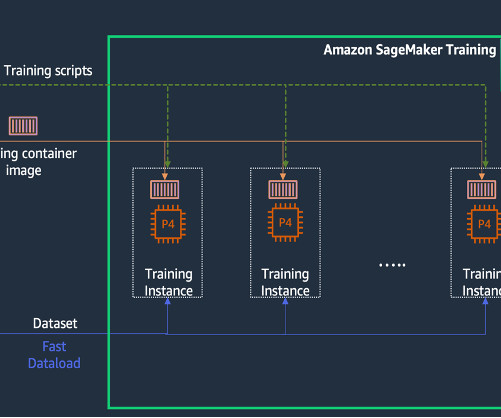
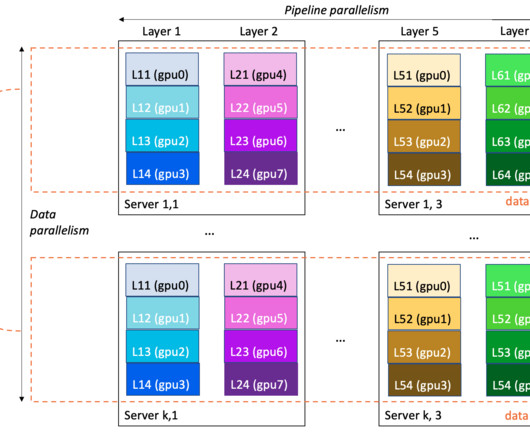
Modern model pre-training often calls for larger cluster deployment to reduce time and cost. At the server level, such training workloads demand faster compute and increased memory allocation. As models grow to hundreds of billions of parameters, they require a distributed training mechanism that spans multiple nodes (instances).
Use call recordings and ongoing training to nurture emotional competence among agents. Training agents to excel at their positions falls largely on teaching them to calmly coax positive results from negative situations. Emotional intelligence can be trained most effectively by refocusing your agents’ attention on their own behaviors.
Handling Basic Inquiries : Chat GPT can assist with basic inquiries such as order status, account information, shipping details, or product specifications. Language Support : Chat GPT can be trained in multiple languages, enabling contact centers to provide support to customers globally without the need for multilingual agents.
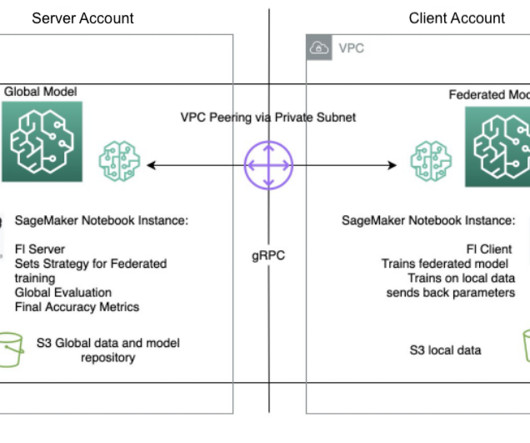
Many ML algorithms train over large datasets, generalizing patterns it finds in the data and inferring results from those patterns as new unseen records are processed. Native support for distributed training is offered through the Amazon SageMaker SDK, along with example notebooks in popular frameworks. What is federated learning?
Their emphasis customer service training delivers end-to-end service excellence that is driving strong loyalty, competitive differentiation and direct revenue generation. They don’t want ten minutes of on-hold music only to hear canned, scripted responses that ignore their real issues and needs. Customers want empathy.
In part 1 , we addressed the data steward persona and showcased a data mesh setup with multiple AWS data producer and consumer accounts. The data scientists in this team use Amazon SageMaker to build and train a credit risk prediction model using the shared credit risk data product from the consumer banking LoB. Data exploration.
We build a model to predict the severity (benign or malignant) of a mammographic mass lesion trained with the XGBoost algorithm using the publicly available UCI Mammography Mass dataset and deploy it using the MLOps framework. After it’s trained, the model is registered into the central model registry to be approved by a model approver.
I thought about the warehouse full of employees that were waiting to ship out orders the contact center teams took, and I thought about the dozens of account managers that were depending on the contact center teams to sell products and make their clients happy. This company didn’t even have a training department.
With the increasing use of artificial intelligence (AI) and machine learning (ML) for a vast majority of industries (ranging from healthcare to insurance, from manufacturing to marketing), the primary focus shifts to efficiency when building and training models at scale. The steps are as follows: Open AWS Cloud9 on the console.
Large language models (LLMs) are neural network-based language models with hundreds of millions ( BERT ) to over a trillion parameters ( MiCS ), and whose size makes single-GPU training impractical. The size of an LLM and its training data is a double-edged sword: it brings modeling quality, but entails infrastructure challenges.
This post outlines the steps AWS and Twilio took to migrate Twilio’s existing machine learning operations (MLOps), the implementation of training models, and running batch inferences to Amazon SageMaker. The training data used for this pipeline is made available through PrestoDB and read into Pandas through the PrestoDB Python client.
Retrieval Augmented Generation (RAG) is a popular paradigm that provides additional knowledge to large language models (LLMs) from an external source of data that wasn’t present in their training corpus. For more information about fine tuning Sentence Transformer, see Sentence Transformer training overview.
Today, we’re pleased to announce the preview of Amazon SageMaker Profiler , a capability of Amazon SageMaker that provides a detailed view into the AWS compute resources provisioned during training deep learning models on SageMaker. You also need to add domain user profiles for individual users to access the SageMaker Profiler UI application.
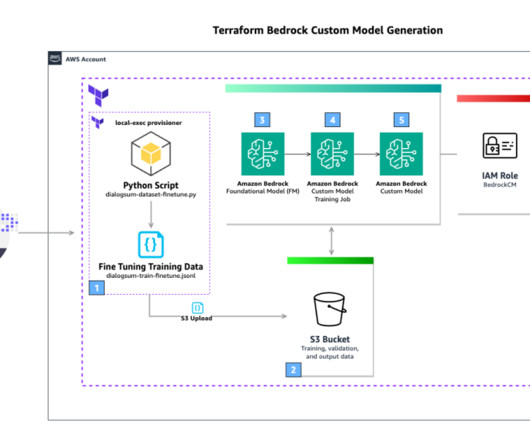
The complete flow is shown in the following figure and it covers the following steps: The user invokes a SageMaker training job to fine-tune the model using QLoRA and store the weights in an Amazon Simple Storage Service (Amazon S3) bucket in the user’s account. This copy will remain until the custom model is deleted.
Amazon Bedrock supports two methods of model customization: Fine-tuning allows you to increase model accuracy by providing your own task-specific labeled training dataset and further specialize your FMs. We then create an Amazon Bedrock custom model using fine-tuning, and create a second model using continued pre-training.
The framework code and examples presented here only cover model training pipelines, but can be readily extended to batch inference pipelines as well. Configuration files (YAML and JSON) allow ML practitioners to specify undifferentiated code for orchestrating training pipelines using declarative syntax.
Call center managers may be involved with hiring and training call center agents , monitoring call center metrics tied to agent performance , using speech analytics tools for ongoing quality monitoring , providing ongoing feedback and coaching, and more. Good scripting can lessen the amount of decision making, but another way to counteract.
Contrast that with Scope 4/5 applications, where not only do you build and secure the generative AI application yourself, but you are also responsible for fine-tuning and training the underlying large language model (LLM).
” – Gregory Ciotti, Go-To Scripts for Handling 10 Tricky Customer Service Scenarios , Help Scout; Twitter: @helpscout. Account for customers’ biases and try to adapt to their communication style. Companies forget this sometimes, however, and fail to adequately train representatives.
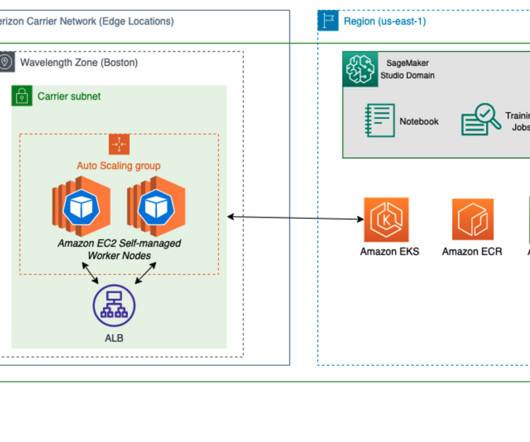
To reduce the barrier to entry of ML at the edge, we wanted to demonstrate an example of deploying a pre-trained model from Amazon SageMaker to AWS Wavelength , all in less than 100 lines of code. As our sample workload, we deploy a pre-trained model from Amazon SageMaker JumpStart. The following diagram illustrates this architecture.
Top 3 methods for training tone of voice. It’s essential for call center managers to take tone of voice into consideration when developing an agent training program. Here are 3 tips on how to train tone of voice to call center agents: 1. Communicate what your brand stands for throughout the training process.
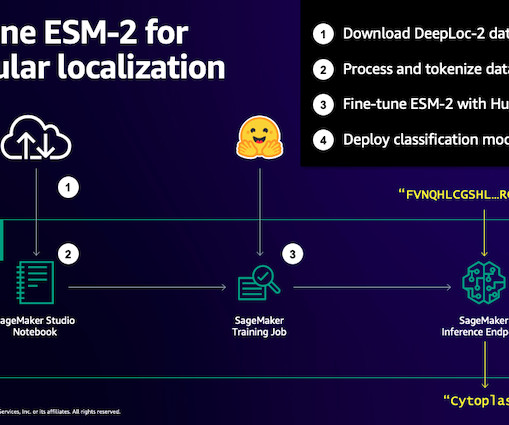
Similarly, pLMs are pre-trained on large protein sequence databases using unlabeled, self-supervised learning. This means that it can take a long time to train them to sufficient accuracy. Long training times, plus large instances, equals high cost, which can put this work out of reach for many researchers.
However, training these gigantic networks from scratch requires a tremendous amount of data and compute. For smaller NLP datasets, a simple yet effective strategy is to use a pre-trained transformer, usually trained in an unsupervised fashion on very large datasets, and fine-tune it on the dataset of interest. trainingscript.
Understanding up front which preprocessing techniques and algorithm types provide best results reduces the time to develop, train, and deploy the right model. large for training job usage and Number of instances across all training jobs. AWS allows by default only 20 parallel SageMaker training jobs for both quotas.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



































Let's personalize your content