This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Using its enterprise software, FloTorch conducted an extensive comparison between Amazon Nova models and OpenAIs GPT-4o models with the Comprehensive Retrieval Augmented Generation (CRAG) benchmark dataset. FloTorch used these queries and their ground truth answers to create a subset benchmark dataset.
Overview of Pixtral 12B Pixtral 12B, Mistrals inaugural VLM, delivers robust performance across a range of benchmarks, surpassing other open models and rivaling larger counterparts, according to Mistrals evaluation. Performance metrics and benchmarks Pixtral 12B is trained to understand both natural images and documents, achieving 52.5%
Amazon Bedrock , a fully managed service offering high-performing foundation models from leading AI companies through a single API, has recently introduced two significant evaluation capabilities: LLM-as-a-judge under Amazon Bedrock Model Evaluation and RAG evaluation for Amazon Bedrock Knowledge Bases. 0]}-{evaluator_model.split('.')[0]}-{datetime.now().strftime('%Y-%m-%d-%H-%M-%S')}"
Oil and gas data analysis – Before beginning operations at a well a well, an oil and gas company will collect and process a diverse range of data to identify potential reservoirs, assess risks, and optimize drilling strategies. Consider a financial data analysis system. We give more details on that aspect later in this post.
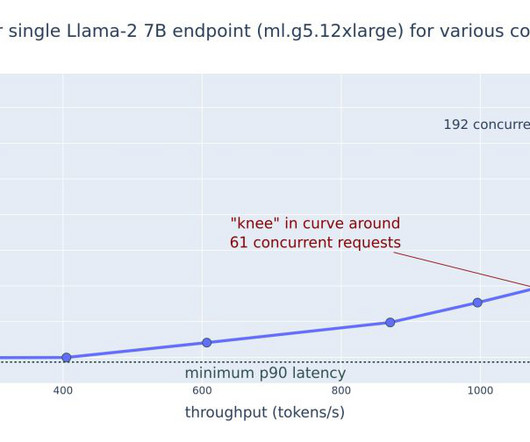
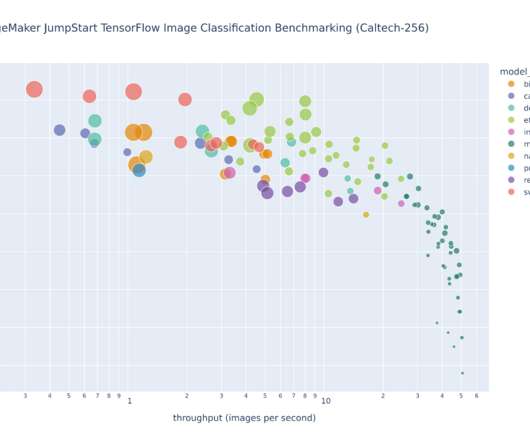
This post explores these relationships via a comprehensive benchmarking of LLMs available in Amazon SageMaker JumpStart, including Llama 2, Falcon, and Mistral variants. We provide theoretical principles on how accelerator specifications impact LLM benchmarking. Additionally, models are fully sharded on the supported instance.
A slight delay in generating a complex analysis might be acceptable, and even a small lag in a conversational exchange can feel disruptive. When conducting your own benchmarks, make sure your test dataset represents your actual production workload characteristics, including typical input lengths and expected output patterns.
These include metrics such as ROUGE or cosine similarity for text similarity, and specific benchmarks for assessing toxicity (Detoxify), prompt stereotyping (cross-entropy loss), or factual knowledge (HELM, LAMA). Refer to Getting started with the API to set up your environment to make Amazon Bedrock requests through the AWS API.
Amazon Bedrock is a fully managed service that makes FMs from leading AI startups and Amazon available through an API, so you can choose from a wide range of FMs to find the model that is best suited for your use case. Solution overview The solution comprises two main steps: Generate synthetic data using the Amazon Bedrock InvokeModel API.
Explore advanced models, like Idefics2 and Chameleon, to build exceptional AI assistants capable of OCR, document analysis, visual reasoning, and creative content generation. First, hear an overview of identity-aware APIs, and then learn how to configure an identity provider as a trusted token issuer.
Acting as a model hub, JumpStart provided a large selection of foundation models and the team quickly ran their benchmarks on candidate models. Regarding the inference, customers using Amazon Ads now have a new API to receive these generated images. The Amazon API Gateway receives the PUT request (step 1).
Example use cases for Jamba-Instruct Jamba-Instruct’s long context length is particularly well-suited for complex Retrieval Augmented Generation (RAG) workloads, or potentially complex document analysis. Programmatic access You can also access Jamba-Instruct through an API, using Amazon Bedrock and AWS SDK for Python (Boto3).
streamlined the analysis of over 70,000 vulnerabilities, automating a process that would have been nearly impossible to accomplish manually. We also provide insights into the model selection process, results analysis, conclusions, recommendations, and Mend.io’s future outlook on integrating artificial intelligence (AI) in cybersecurity.
A common way to select an embedding model (or any model) is to look at public benchmarks; an accepted benchmark for measuring embedding quality is the MTEB leaderboard. The Massive Text Embedding Benchmark (MTEB) evaluates text embedding models across a wide range of tasks and datasets.
The DITEX department engaged with the Safety, Sustainability & Energy Transition team for a preliminary analysis of their pain points and deemed it feasible to use generative AI techniques to speed up the resolution of compliance queries faster. However, a manual process is time-consuming and not scalable.
It was built for organizations with the resources to manage layered feedback systems, not for lean teams that need quick, actionable customer feedback analysis. Were a full-service survey company handling everything you need including survey design, deployment, analysis, reporting, and more. Metrics Cards display real-time scores.
Use APIs and middleware to bridge gaps between CPQ and existing enterprise systems, ensuring smooth data flow. Automate Price Calculations and Adjustments Utilize real-time pricing engines within CPQ to dynamically calculate prices based on market trends, cost fluctuations, and competitor benchmarks.
The current benchmark is set for 96% customer satisfaction, but they regularly surpass this number. Using Aircall’s open API, users can create customizable integrations. The post GetApp Analysis Declares Aircall a Call Center Software Leader appeared first on Customer Experience & Cloud Call Center | Aircall Blog.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models from leading AI companies and Amazon via a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI. A limitation of the approach is its larger computational cost.
Red-teaming engages human testers to probe an AI system for flaws in an adversarial style, and complements our other testing techniques, which include automated benchmarking against publicly available and proprietary datasets, human evaluation of completions against proprietary datasets, and more.
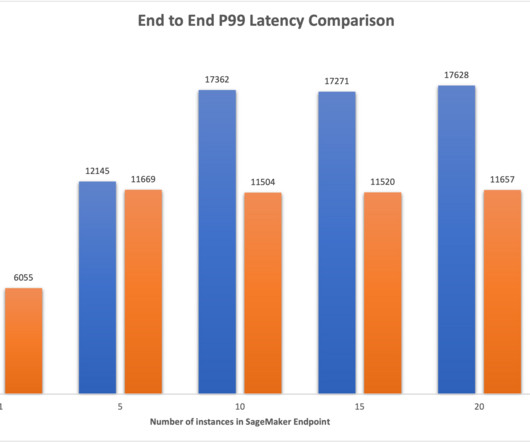
When ML models deployed on instances receive API calls from a large number of clients, a random distribution of requests can work very well when there is not a lot of variability in your requests and responses. Finally, we present a comparative analysis of latency improvements with LOR over the default routing strategy of random routing.
The former question addresses model selection across model architectures, while the latter question concerns benchmarking trained models against a test dataset. This post provides details on how to implement large-scale Amazon SageMaker benchmarking and model selection tasks. swin-large-patch4-window7-224 195.4M efficientnet-b5 29.0M
These examples include speeding up market trend analysis, ensuring accurate risk management and compliance, and facilitating data collection or report generation. You can use resources such as the Amazon Sustainability Data Initiative or the AWS Data Exchange to simplify and expedite the acquisition and analysis of comprehensive datasets.
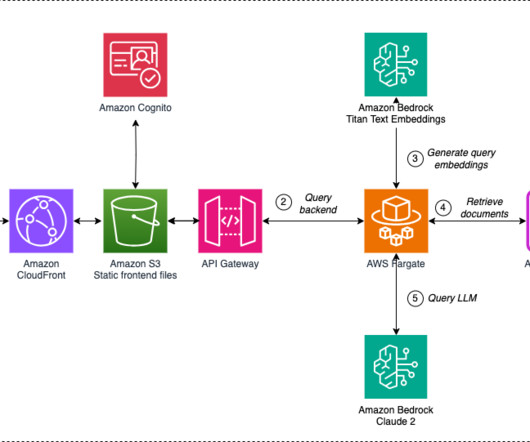
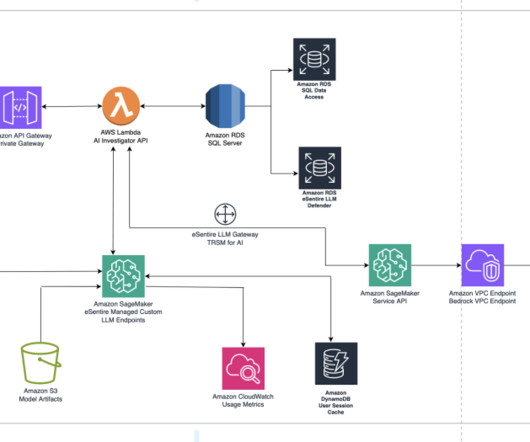
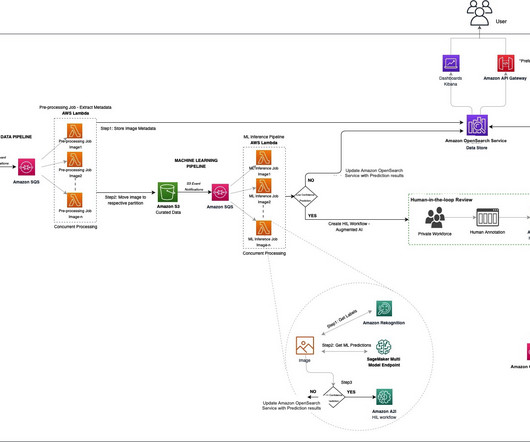
eSentire used instances with CPU for data preprocessing and post-inference analysis and GPU for the actual model (LLM) training. The application’s frontend is accessible through Amazon API Gateway , using both edge and private gateways. The following diagram visualizes the architecture diagram and workflow.
In terms of resulting speedups, the approximate order is programming hardware, then programming against PBA APIs, then programming in an unmanaged language such as C++, then a managed language such as Python. Analysis of publications containing accelerated compute workloads by Zeta-Alpha shows a breakdown of 91.5%
This is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading artificial intelligence (AI) companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon through a single API. It’s serverless, so you don’t have to manage any infrastructure.
Split documents into single pages for specific FeatureType processing – FeatureType is a parameter for the Document AnalysisAPI calls (both synchronous and asynchronous ) in Amazon Textract. AWS Cost Explorer – Configure AWS Cost Explorer for your workload and accounts to visualize your cost data for further analysis.
It provides an integrated Jupyter authoring notebook instance for easy access to your data sources for exploration and analysis, so you don’t have to manage servers. We first benchmark the performance of our model on a single instance to identify the TPS it can handle per our acceptable latency requirements.
Sentiment analysis for contextual next best action. CSML helps developers build and deploy chatbots easily with its expressive syntax and its capacity to connect to any third party API. Self-service APIs to help you create, manage, test and publish custom skills. Key features. Reinforcement learning and ongoing optimization.
Real-Time Response Collection and Analysis. The flagship feature of Qualaroo is sentiment analysis. AI-powered sentiment analysis to track customer sentiments and opinions. Other exciting features of this tool include sentimental analysis, keyword tracking, emotion analysis, and more. Pricing: Custom Pricing. (d)
Snowflake Arctic is a family of enterprise-grade large language models (LLMs) built by Snowflake to cater to the needs of enterprise users, exhibiting exceptional capabilities (as shown in the following benchmarks ) in SQL querying, coding, and accurately following instructions. To learn more, refer to API documentation.
Defining Call Center Analytics Call center analytics refers to the collection, measurement, and analysis of call center data to improve performance and customer experience. While automation can process this data efficiently, human analysis remains crucial. The winning approach combines automated analytics with human judgment.
In this blog post, we will introduce how to use an Amazon EC2 Inf2 instance to cost-effectively deploy multiple industry-leading LLMs on AWS Inferentia2 , a purpose-built AWS AI chip, helping customers to quickly test and open up an API interface to facilitate performance benchmarking and downstream application calls at the same time.
In addition, they use the developer-provided instruction to create an orchestration plan and then carry out the plan by invoking company APIs and accessing knowledge bases using Retrieval Augmented Generation (RAG) to provide an answer to the user’s request. In Part 1, we focus on creating accurate and reliable agents.
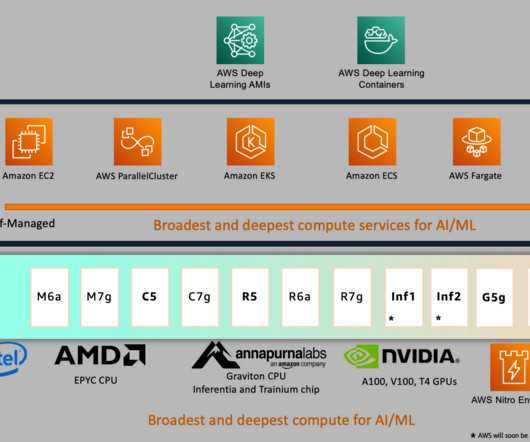
This post further walks through a step-by-step implementation of fine-tuning a RoBERTa (Robustly Optimized BERT Pretraining Approach) model for sentiment analysis using AWS Deep Learning AMIs (AWS DLAMI) and AWS Deep Learning Containers (DLCs) on Amazon Elastic Compute Cloud (Amazon EC2 p4d.24xlarge) torch.compile + bf16 + fused AdamW.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon via a single API. Kojima et al. 2022) introduced an idea of zero-shot CoT by using FMs’ untapped zero-shot capabilities.
Although existing large language model (LLM) benchmarks like MT-bench evaluate model capabilities, they lack the ability to validate the application layers. Evaluator considerations By default, evaluators use the InvokeModel API with On-Demand mode, which will incur AWS charges based on input tokens processed and output tokens generated.
Syne Tune allows us to find a better hyperparameter configuration that achieves a relative improvement between 1-4% compared to default hyperparameters on popular GLUE benchmark datasets. Furthermore, we add another callback function to Hugging Face’s Trainer API that reports the validation performance after each epoch back to Syne Tune.
Two key distinctions are the low altitude, oblique perspective of the imagery and disaster-related features, which are rarely featured in computer vision benchmarks and datasets. Amazon Rekognition makes it easy to add image and video analysis into our applications, using proven, highly scalable, deep learning technology.
Tools and APIs – For example, when you need to teach Anthropic’s Claude 3 Haiku how to use your APIs well. Following this financial data table, a detailed question-answer set is presented to demonstrate the complexity and depth of analysis possible with the TAT-QA dataset.
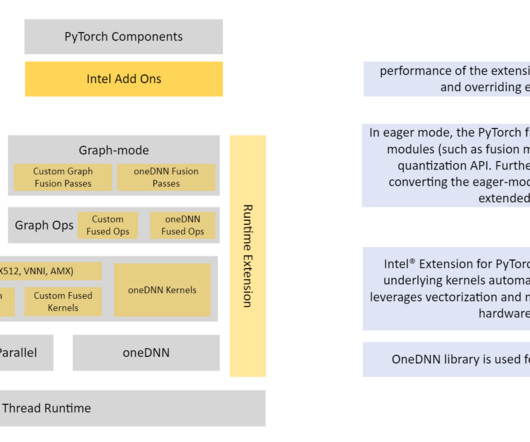
Refer to the appendix for instance details and benchmark data. Quantizing the model in PyTorch is possible with a few APIs from Intel PyTorch extensions. Benchmark data The following table compares the cost and relative performance between c5 and c6 instances. times greater with INT8 quantization. 2xLarge-FP32 70 110.8
For benchmark performance figures, refer to AWS Neuron Performance. Currently, it has examples for the GPT2, GPT-J, and OPT model types, and different model sizes that have their forward functions re-implemented in a compiled language for extensive code analysis and optimizations. This is particularly useful for large language models.
The plentiful and jointly trained parameters of DL models have a large representational capacity that brought improvements in numerous customer use cases, including image and speech analysis, natural language processing (NLP), time series processing, and more. Speedup techniques implemented in Composer can be accessed with its functional API.
Patsnap provides a global one-stop platform for patent search, analysis, and management. as_trt_engine(output_fpath=trt_path, profiles=profiles) gpt2_trt = GPT2TRTDecoder(gpt2_engine, metadata, config, max_sequence_length=42, batch_size=10) Latency comparison: PyTorch vs. TensorRT JMeter is used for performance benchmarking in this project.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content