This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
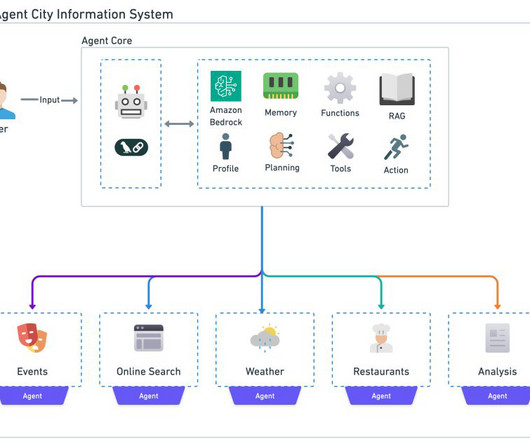
By using the power of LLMs and combining them with specialized tools and APIs, agents can tackle complex, multistep tasks that were previously beyond the reach of traditional AI systems. Whenever local database information is unavailable, it triggers an online search using the Tavily API. Its used by the weather_agent() function.
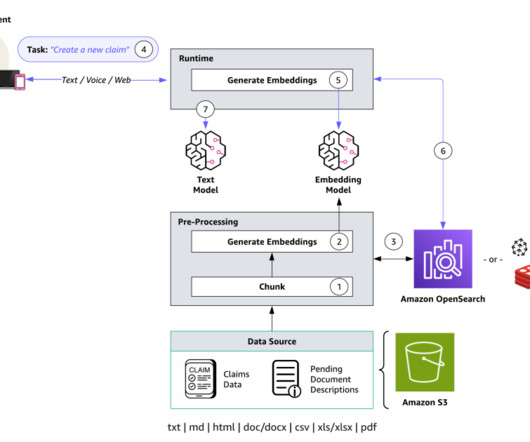
Amazon Bedrock APIs make it straightforward to use Amazon Titan Text Embeddings V2 for embedding data. The implementation used the universal gateway provided by the FloTorch enterprise version to enable consistent API calls using the same function and to track token count and latency metrics uniformly. get("message", {}).get("content")
The goal was to refine customer service scripts, provide coaching opportunities for agents, and improve call handling processes. Frontend and API The CQ application offers a robust search interface specially crafted for call quality agents, equipping them with powerful auditing capabilities for call analysis.
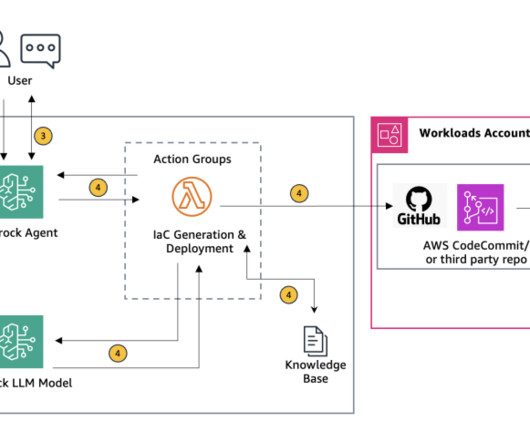
Amazon Bedrock agents use LLMs to break down tasks, interact dynamically with users, run actions through API calls, and augment knowledge using Amazon Bedrock Knowledge Bases. In this post, we demonstrate how to use Amazon Bedrock Agents with a web search API to integrate dynamic web content in your generative AI application.
Refer to Getting started with the API to set up your environment to make Amazon Bedrock requests through the AWS API. Test the code using the native inference API for Anthropics Claude The following code uses the native inference API to send a text message to Anthropics Claude. client = boto3.client("bedrock-runtime",
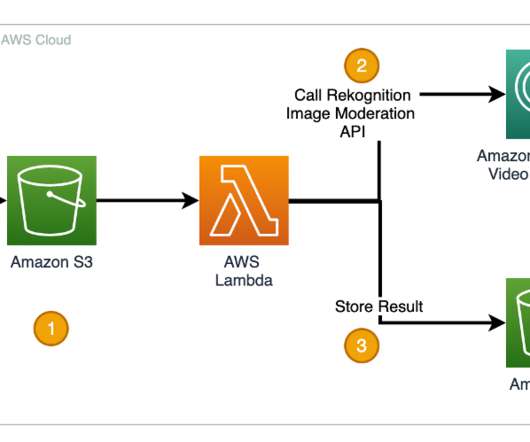
Amazon Rekognition has two sets of APIs that help you moderate images or videos to keep digital communities safe and engaged. Some customers have asked if they could use this approach to moderate videos by sampling image frames and sending them to the Amazon Rekognition image moderation API.
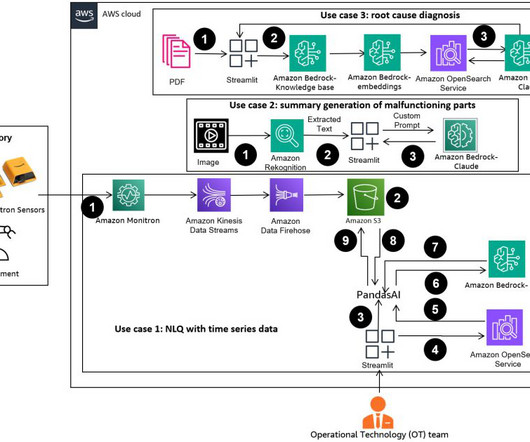
PandasAI is a Python library that adds generative AI capabilities to pandas, the popular data analysis and manipulation tool. However, complex NLQs, such as time series data processing, multi-level aggregation, and pivot or joint table operations, may yield inconsistent Python script accuracy with a zero-shot prompt. setup.sh.
Amazon Comprehend is a fully managed service that can perform NLP tasks like custom entity recognition, topic modelling, sentiment analysis and more to extract insights from data without the need of any prior ML experience. Build your training script for the Hugging Face SageMaker estimator. return tokenized_dataset. to(device).
At the forefront of this evolution sits Amazon Bedrock , a fully managed service that makes high-performing foundation models (FMs) from Amazon and other leading AI companies available through an API. System integration – Agents make API calls to integrated company systems to run specific actions.
This solution uses Retrieval Augmented Generation (RAG) to ensure the generated scripts adhere to organizational needs and industry standards. In this blog post, we explore how Agents for Amazon Bedrock can be used to generate customized, organization standards-compliant IaC scripts directly from uploaded architecture diagrams.
In this post, we enable the provisioning of different components required for performing log analysis using Amazon SageMaker on AWS DeepRacer via AWS CDK constructs. This is where advanced log analysis comes into play. The unit tests are located in DeepRacer/test/deep_racer.test.ts
Amazon Bedrock is a fully managed service that makes FMs from leading AI startups and Amazon available through an API, so you can choose from a wide range of FMs to find the model that is best suited for your use case. Solution overview The solution comprises two main steps: Generate synthetic data using the Amazon Bedrock InvokeModel API.
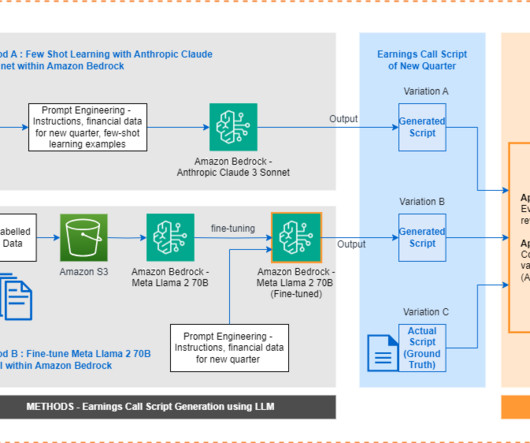
Traditionally, earnings call scripts have followed similar templates, making it a repeatable task to generate them from scratch each time. On the other hand, generative artificial intelligence (AI) models can learn these templates and produce coherent scripts when fed with quarterly financial data.
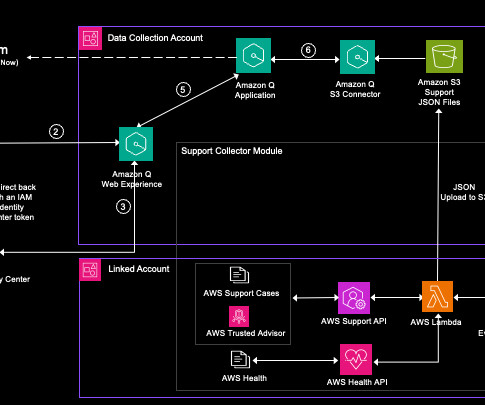
Ingesting data for support cases, Trusted Advisor checks, and AWS Health notifications into Amazon Q Business enables interactions through natural language conversations, sentiment analysis, and root cause analysis without needing to fully understand the underlying data models or schemas. Synchronize the data source to index the data.
Continuous integration and continuous delivery (CI/CD) pipeline – Using the customer’s GitHub repository enabled code versioning and automated scripts to launch pipeline deployment whenever new versions of the code are committed. Wipro has used the input filter and join functionality of SageMaker batch transformation API.
Amazon Rekognition makes it easy to add image analysis capability to your applications without any machine learning (ML) expertise and comes with various APIs to fulfil use cases such as object detection, content moderation, face detection and analysis, and text and celebrity recognition, which we use in this example.
By bridging the gap between raw genetic data and actionable knowledge, genomic language models hold immense promise for various industries and research areas, including whole-genome analysis , delivered care , pharmaceuticals , and agriculture. Lastly the model is tested against a set of known genome sequences using some inference API calls.
Gramener’s GeoBox solution empowers users to effortlessly tap into and analyze public geospatial data through its powerful API, enabling seamless integration into existing workflows. A grid system is established with a 48-meter grid size using Mapbox’s Supermercado Python library at zoom level 19, enabling precise spatial analysis.
Additionally, we won’t be able to make an informed decision post-analysis of those insights prior to building the ML models. The data flow recipe consists of preprocessing steps along with a bias report, multicollinearity report, and model quality analysis. Overview of solution. DeShazo, Chris Gennings, Juan L. Cios, and John N.
Zoho Desk Zoho Desk is a cloud-based QA platform that enables call centers to manage customer support tickets, customer satisfaction analysis tools, and advanced agent scoring techniques. Text Analysis: Use Qualtrics text analysis capabilities to get deeper insights about survey responses.
Users can also interact with data with ODBC, JDBC, or the Amazon Redshift Data API. The use of RStudio on SageMaker and Amazon Redshift can be helpful for efficiently performing analysis on large data sets in the cloud. Running queries and SageMaker API actions on data within Amazon Redshift Serverless through RStudio on SageMaker.
The main AWS services used are SageMaker, Amazon EMR , AWS CodeBuild , Amazon Simple Storage Service (Amazon S3), Amazon EventBridge , AWS Lambda , and Amazon API Gateway. Real-time recommendation inference The inference phase consists of the following steps: The client application makes an inference request to the API gateway.
The Retrieve and RetrieveAndGenerate APIs allow your applications to directly query the index using a unified and standard syntax without having to learn separate APIs for each different vector database, reducing the need to write custom index queries against your vector store.
AWS Prototyping successfully delivered a scalable prototype, which solved CBRE’s business problem with a high accuracy rate (over 95%) and supported reuse of embeddings for similar NLQs, and an API gateway for integration into CBRE’s dashboards. The following diagram illustrates the web interface and API management layer.
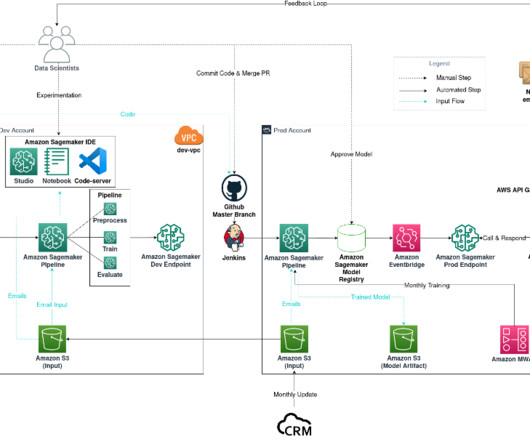
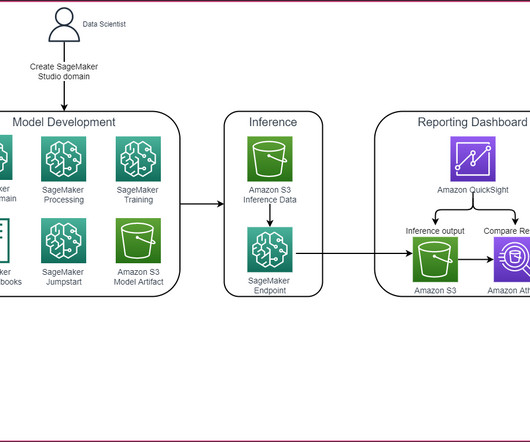
Email classification project diagram The workflow consists of the following components: Model experimentation – Data scientists use Amazon SageMaker Studio to carry out the first steps in the data science lifecycle: exploratory data analysis (EDA), data cleaning and preparation, and building prototype models.
Amazon Rekognition supports adding image and video analysis to your applications. With the IAM permissions configured, you can run the notebook in SageMaker with access to Amazon Rekognition for the video analysis. OpenCv is an open source library with over 250 algorithms for computer vision analysis. See the following figure.
An asynchronous API and Amazon OpenSearch Service connector make it easy to integrate the model into your neural search applications. Before you can write scripts that use the Amazon Bedrock API, you need to install the appropriate version of the AWS SDK in your environment. The vectors power speedy, accurate search experiences.
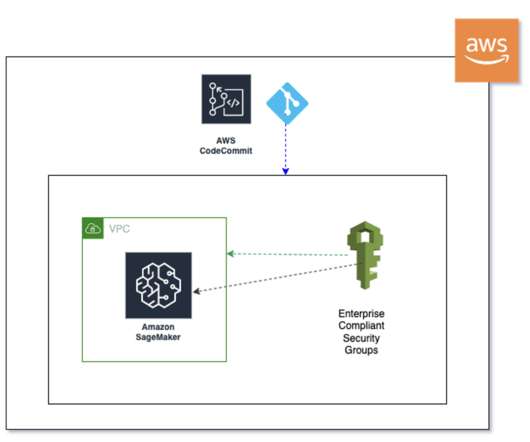
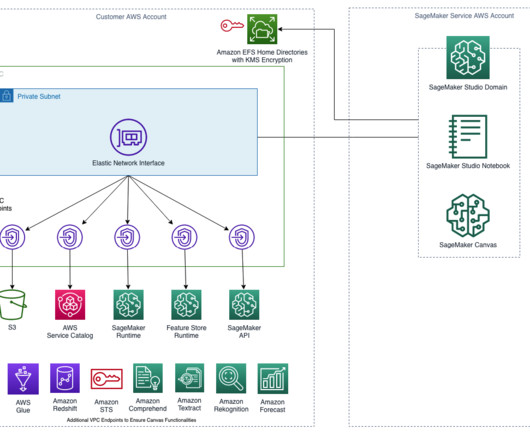
You must also associate a security group for your VPC with these endpoints to allow all inbound traffic from port 443: SageMaker API: com.amazonaws.region.sagemaker.api. This is required to communicate with the SageMaker API. SageMaker runtime: com.amazonaws.region.sagemaker.runtime.
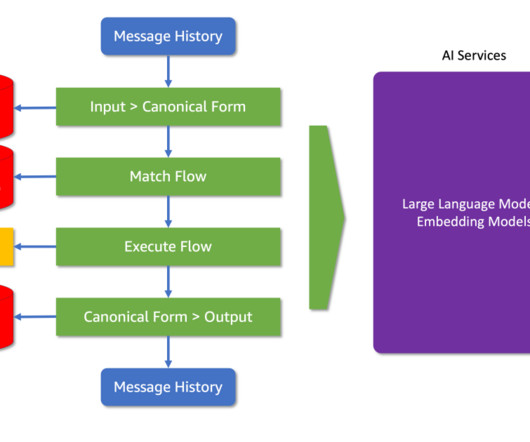
Lets delve into a basic Colang script to see how it works: define user express greeting "hello" "hi" "what's up?" define flow greeting user express greeting bot express greeting bot ask how are you In this script, we see the three fundamental types of blocks in Colang: User Message Blocks (define user ): These define possible user inputs.
You need to complete three steps to deploy your model: Create a SageMaker model: This will contain, among other parameters, the information about the model file location, the container that will be used for the deployment, and the location of the inference script. (If The inference script URI is needed in the INFERENCE_SCRIPT_S3_LOCATION.
Model weights are available via scripts in the GitHub repository , and the MSAs are hosted by the Registry of Open Data on AWS (RODA). We use aws-do-eks , an open-source project that provides a large collection of easy-to-use and configurable scripts and tools to enable you to provision EKS clusters and run your inference.
The solution also uses Amazon Bedrock , a fully managed service that makes foundation models (FMs) from Amazon and third-party model providers accessible through the AWS Management Console and APIs. For this post, we use the Amazon Bedrock API via the AWS SDK for Python. The script instantiates the Amazon Bedrock client using Boto3.
To build a production-grade AI system today (for example, to do multilingual sentiment analysis of customer support conversations), what are the primary technical challenges? This often means the method of using a third-party LLM API won’t do for security, control, and scale reasons. The following figure illustrates this workflow.
Today, we’re excited to announce the new synchronous API for targeted sentiment in Amazon Comprehend, which provides a granular understanding of the sentiments associated with specific entities in input documents. The Targeted Sentiment API provides the sentiment towards each entity. Targeted sentiment use cases.
Accelerate research and analysis – Instead of manually searching through SharePoint documents, users can use Amazon Q to quickly find relevant information, summaries, and insights to support their research and decision-making. Any additional mappings need to be set in the user store using the user store APIs.
As a JumpStart model hub customer, you get improved performance without having to maintain the model script outside of the SageMaker SDK. The inference script is prepacked with the model artifact. nYou can access Amazon Comprehend document analysis capabilities using the Amazon Comprehend console or using the Amazon Comprehend APIs.
You can perform data analysis, train your models, and test them using your own algorithms or use SageMaker-provided ML algorithms that are optimized to run efficiently against large datasets spread across multiple machines. Prepare your trained model and inference script. pth,pkl, and so on) and an inference script.
Access and permissions to configure IDP to register Data Wrangler application and set up the authorization server or API. Configure the IdP To set up your IdP, you must register the Data Wrangler application and set up your authorization server or API. Configure Snowflake. Configure SageMaker Studio.
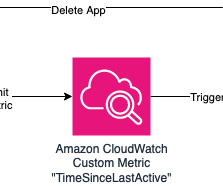
All that is needed to do is change the line of code calling the DeleteApp API into CreateApp , as well as updating the cron expression to reflect the desired app creation time. This metric can be read via Amazon CloudWatch API such as get_metric_data. 7PM on a work day, always shut down during weekends).
For a quantitative analysis of the generated impression, we use ROUGE (Recall-Oriented Understudy for Gisting Evaluation), the most commonly used metric for evaluating summarization. In order to run inference through SageMaker API, make sure to pass the Predictor class.
The JumpStart APIs allow you to programmatically deploy and fine-tune a vast selection of pre-trained models on your own datasets. These features remove the heavy lifting from each step of the ML process, making it easier to develop high-quality models and reducing time to deployment.
It provides an integrated Jupyter authoring notebook instance for easy access to your data sources for exploration and analysis, so you don’t have to manage servers. This model can perform a number of tasks, but we send a payload specifically for sentiment analysis and text classification. Deploy a real-time endpoint.
Customers can also access offline store data using a Spark runtime and perform big data processing for ML feature analysis and feature engineering use cases. A new optional parameter TableFormat can be set either interactively using Amazon SageMaker Studio or through code using the API or the SDK. Select Python Shell script editor.
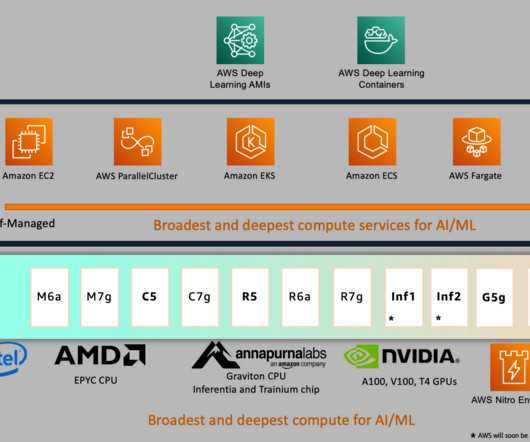
This post further walks through a step-by-step implementation of fine-tuning a RoBERTa (Robustly Optimized BERT Pretraining Approach) model for sentiment analysis using AWS Deep Learning AMIs (AWS DLAMI) and AWS Deep Learning Containers (DLCs) on Amazon Elastic Compute Cloud (Amazon EC2 p4d.24xlarge) torch.compile + bf16 + fused AdamW.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








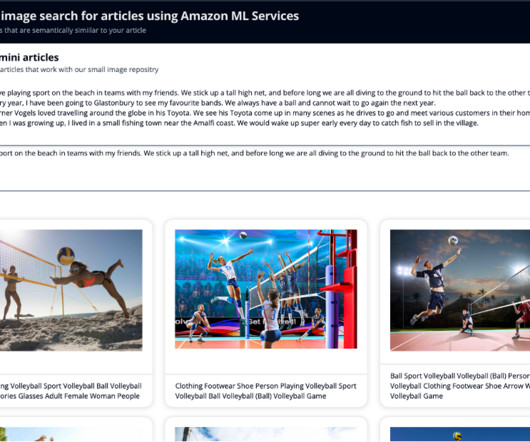

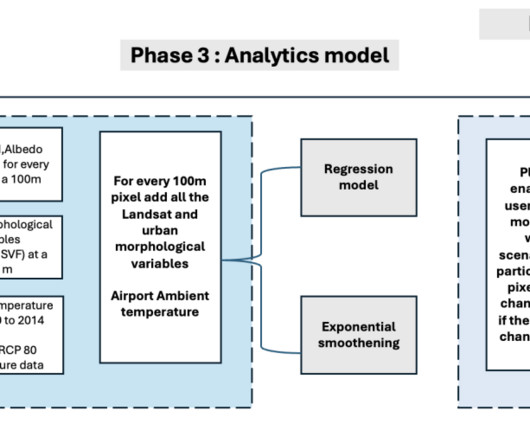


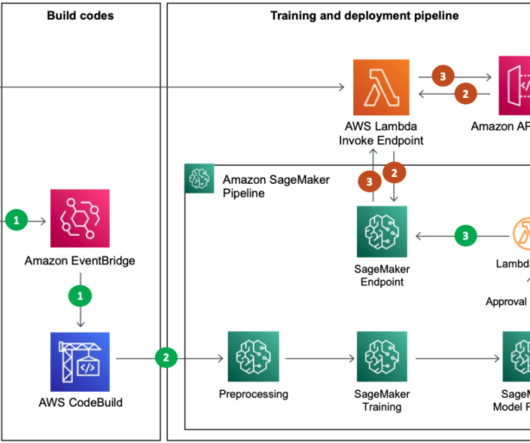






















Let's personalize your content