This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Using its enterprise software, FloTorch conducted an extensive comparison between Amazon Nova models and OpenAIs GPT-4o models with the Comprehensive Retrieval Augmented Generation (CRAG) benchmark dataset. FloTorch used these queries and their ground truth answers to create a subset benchmark dataset.
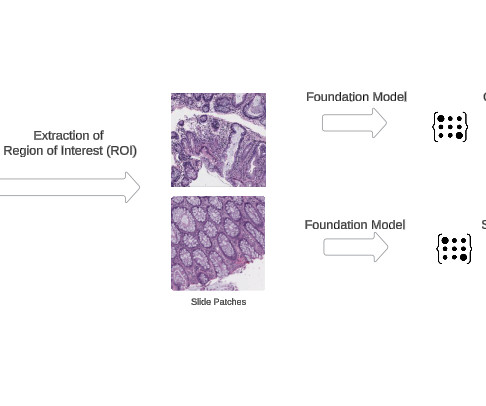
The power of FMs lies in their ability to learn robust and generalizable data embeddings that can be effectively transferred and fine-tuned for a wide variety of downstream tasks, ranging from automated disease detection and tissue characterization to quantitative biomarker analysis and pathological subtyping.
In the case of a call center, you will mark the performance of the agents against key performance indicators like script compliance and customer service. The goal of QA in any call center is to maintain high levels of service quality, ensure agents adhere to company policies and scripts, and identify areas of improvement.
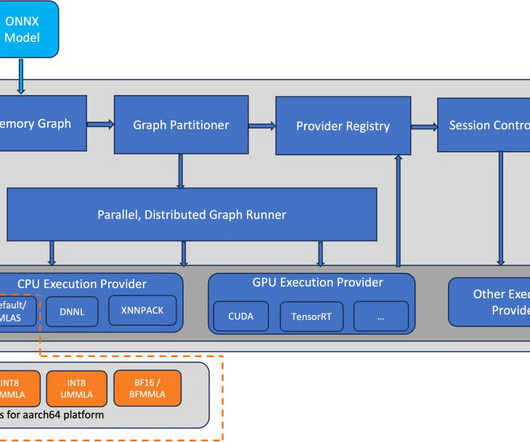
We also demonstrate the resulting speedup through benchmarking. Benchmark setup We used an AWS Graviton3-based c7g.4xl 1014-aws kernel) The ONNX Runtime repo provides inference benchmarkingscripts for transformers-based language models. The scripts support a wide range of models, frameworks, and formats.
Bill Dettering is the CEO and Founder of Zingtree , a SaaS solution for building interactive decision trees and agent scripts for contact centers (and many other industries). Interactive agent scripts from Zingtree solve this problem. Agents can also send feedback directly to script authors to further improve processes.
Encourage agents to cheer up callers with more flexible scripting. “A 2014 survey suggested that 69% of customers feel that their call center experience improves when the customer service agent doesn’t sound as though they are reading from a script. Minimise language barriers with better hires.
Through automation, you can scale in-demand skillsets, such as model and data analysis, introducing and enforcing in-depth analysis of your models at scale across diverse product teams. This allows you to introduce analysis of arbitrary complexity while not being limited by the busy schedules of highly technical individuals.
It can navigate open-ended prompts, and novel scenarios with remarkable fluency, including task automation, hypothesis generation, and analysis of charts, graphs, and forecasts. Media organizations can generate image captions or video scripts automatically. And Sonnet is first available on Amazon Bedrock today.
wheels and set the previously mentioned environment variables # Clone PyTorch benchmark repo git clone [link] # Setup Resnet50 benchmark cd benchmark python3 install.py On successful completion of the inference runs, # the script prints the inference latency and accuracy results python3 run.py
Code generation DBRX models demonstrate benchmarked strengths for coding tasks. user Write a Python script to read a CSV file containing stock prices and plot the closing prices over time using Matplotlib. The file should have columns named 'Date' and 'Close' for this script to work correctly.
LMMs have the potential to profoundly impact various industries, such as healthcare, business analysis, autonomous driving, and so on. Without this fine-grained visual understanding, the language model is constrained to more superficial, high-level analysis and generation capabilities related to images.
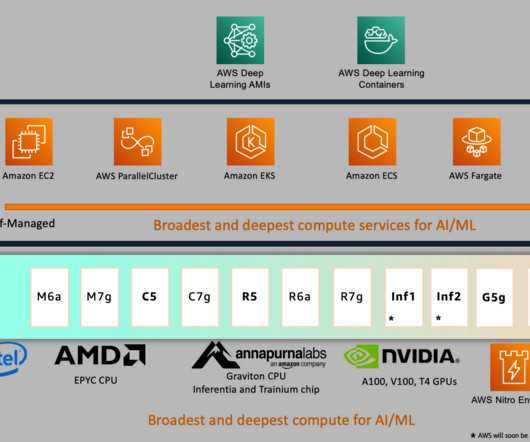
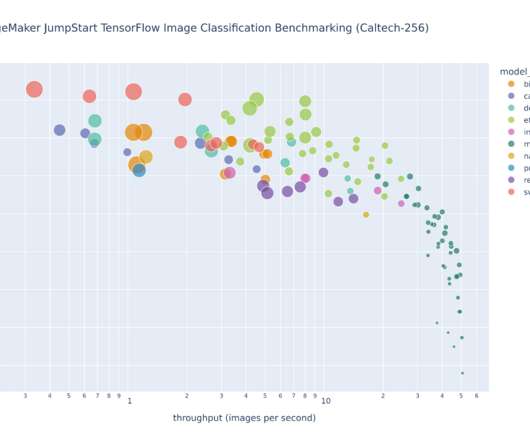
We cover computer vision (CV), natural language processing (NLP), classification, and ranking scenarios for models and ml.c6g, ml.c7g, ml.c5, and ml.c6i SageMaker instances for benchmarking. You can use the sample notebook to run the benchmarks and reproduce the results. Create an endpoint configuration.
For more information on the TPC-H data, its database entities, relationships, and characteristics, refer to TPC Benchmark H. We use a preprocessing script to connect and query data from a PrestoDB instance using the user-specified SQL query in the config file. For more information on processing jobs, see Process data.
of business executives (2020 NTT/DiData Customer Experience Benchmarking Study), see the customer experience that their organizations provide as a key differentiator and the number one indicator of their overall strategic leadership. And it may be no more than an innocent, off-script comment that causes the issue.
These include metrics such as ROUGE or cosine similarity for text similarity, and specific benchmarks for assessing toxicity (Detoxify), prompt stereotyping (cross-entropy loss), or factual knowledge (HELM, LAMA). If the use case doesnt yield discrete outputs, task-specific metrics are more appropriate.
Transcription Services: Tools automatically transcribe voice interactions into text, making them ready for further analysis. Chat Logs & Emails: Every typed interaction is stored, allowing analytics tools to scour them for patterns, keywords, and sentiment analysis. Analysis: The Deep Dive The analysis is where the magic happens.
This post further walks through a step-by-step implementation of fine-tuning a RoBERTa (Robustly Optimized BERT Pretraining Approach) model for sentiment analysis using AWS Deep Learning AMIs (AWS DLAMI) and AWS Deep Learning Containers (DLCs) on Amazon Elastic Compute Cloud (Amazon EC2 p4d.24xlarge) torch.compile + bf16 + fused AdamW.
The former question addresses model selection across model architectures, while the latter question concerns benchmarking trained models against a test dataset. This post provides details on how to implement large-scale Amazon SageMaker benchmarking and model selection tasks. swin-large-patch4-window7-224 195.4M efficientnet-b5 29.0M
It provides an integrated Jupyter authoring notebook instance for easy access to your data sources for exploration and analysis, so you don’t have to manage servers. We first benchmark the performance of our model on a single instance to identify the TPS it can handle per our acceptable latency requirements.
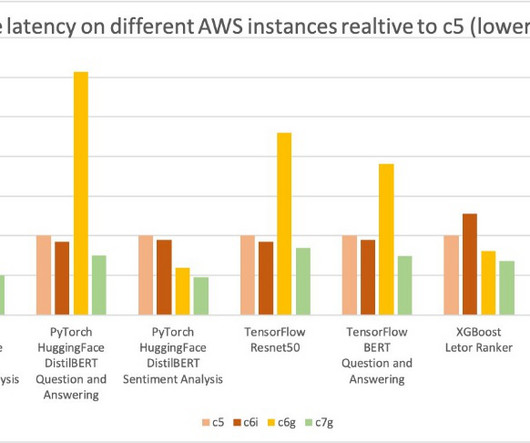
Refer to the appendix for instance details and benchmark data. Use the supplied Python scripts for quantization. Run the provided Python test scripts to invoke the SageMaker endpoint for both INT8 and FP32 versions. Benchmark data The following table compares the cost and relative performance between c5 and c6 instances.
The concepts illustrated in this post can be applied to applications that use PLM features, such as recommendation systems, sentiment analysis, and search engines. The task assigned to the BERT PLM can be a text-based task such as sentiment analysis, text classification, or Q&A. training.py ).
This was the perfect place to start for our prototype—not only would Axfood gain a new AI/ML platform, but we would also get a chance to benchmark our ML capabilities and learn from leading AWS experts. If discrepancies arise, a business logic within the postprocessing script assesses whether retraining the model is necessary.
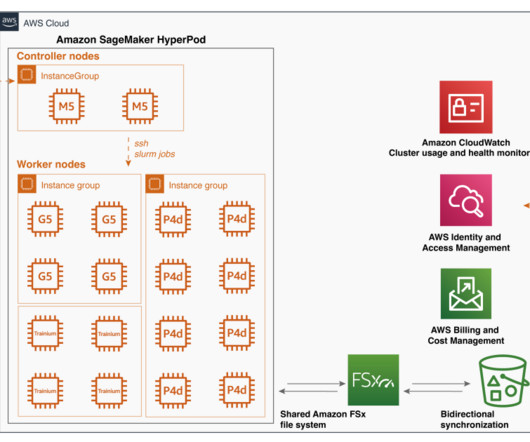
Our benchmarks show up to 46% price performance benefit after enabling heterogeneous clusters in a CPU-bound TensorFlow computer vision model training. Performance benchmark results. You can build logic in your training script to assign the instance groups to certain training and data processing tasks.
As noted in the 2019 Dimension Data Customer Experience (CX) Benchmarking report: 88% of contact center decision-makers expect self-service volumes to increase over the next 12 months. Agents will be presented with increasingly more complex situations which will require more engagement, insight and analysis. Act on the results.
The method is trained on a dataset of video clips and achieves state-of-the-art results on fashion video and human dance synthesis benchmarks, demonstrating its ability to animate arbitrary characters while maintaining appearance consistency and temporal stability. The implementation of AnimateAnyone can be found in this repository.
Flip the script on your results and use that as a motivator. But if you are just starting to explore customer feedback in general, this is a simple way to get started and then benchmark against in the future. Review and benchmark CSAT at several points along the journey. That alone is a powerful way to use CSAT.
The plentiful and jointly trained parameters of DL models have a large representational capacity that brought improvements in numerous customer use cases, including image and speech analysis, natural language processing (NLP), time series processing, and more. Composer is available via pip : pip install mosaicml.
For benchmarkanalysis, we considered the task of predicting the in-hospital mortality of patients [2]. You can place the data in any folder of your choice, as long as the path is consistently referenced in the training script and has access enabled. Import the data loader into the training script. and data_loader.py
Strategies to Improve Customer Satisfaction KPIs: Clearly define each metric and establish benchmarks. Benchmark: Many organizations aim for an AHT of 480 seconds (8 minutes), depending on industry standards. Industry Standard: The 80/20 rule (80% of calls answered within 20 seconds) is a common benchmark.
The demand for multi-object tracking (MOT) in video analysis has increased significantly in many industries, such as live sports, manufacturing, and traffic monitoring. Since its introduction in 2021, ByteTrack remains to be one of best performing methods on various benchmark datasets, among the latest model developments in MOT application.
Syne Tune allows us to find a better hyperparameter configuration that achieves a relative improvement between 1-4% compared to default hyperparameters on popular GLUE benchmark datasets. training script. On a text classification problem, this leads to an additional boost in accuracy of approximately 5% compared to the default model.
He also builds tools to help his team tackle various aspects of the LLM development life cycleincluding fine-tuning, benchmarking, and load-testingthat accelerating the adoption of diverse use cases for AWS customers. in Physics from the University of Iowa, with a focus on astronomical X-ray analysis and instrumentation development.
Satisfied customers and great customer service result from a cycle of data collection, analysis, training, and improvement. Look into benchmarking. The benchmarking process is a continuous loop. The benchmarking process is a continuous loop. For some businesses, benchmarking and maintaining quality can be a challenge.
Amazon Rekognition is a service that makes it simple to perform different types of visual analysis on your applications. The deployments are done using bash scripts, and in this case we use the following command: bash malware_detection_deployment_scripts/deploy.sh -s ' ' -b 'malware- detection- -artifacts' -p -r " " -a.
Call center monitoring is the continuous process of data collection, analysis, and feedback. The recording process is handled by dedicated software, but the analysis and decision-making are more often than not performed by professional data analysts. then gain insight from it, and then implement change relative to that insight.
Even if you already have a pre-trained model, it may still be easier to use its corollary in SageMaker and input the hyperparameters you already know rather than port it over and write a training script yourself. The training and inference scripts for the selected model or algorithm. Benchmarking the trained models.
Report: 2019 Live Chat Benchmark Report. Keep an eye out for the 2020 Live Chat Benchmark Report coming out in January or subscribe and be the first to get it. and clearly defines key related terms like decision trees, natural language processing (NLP), machine learning (ML), and sentiment analysis. Demystifying chatbots and AI.
There is no benchmark that determines whether your CPA is good enough or not. This may involve additional training for your agents, reviewing your sales script, or considering other marketing techniques such as offers and discounts. Analysis of KPI metrics can reveal areas for improvement, such as: A poor quality lead list.
Snowflake Arctic is a family of enterprise-grade large language models (LLMs) built by Snowflake to cater to the needs of enterprise users, exhibiting exceptional capabilities (as shown in the following benchmarks ) in SQL querying, coding, and accurately following instructions.
Sentiment Analysis: An automated process that allows a chatbot to extract verbal cues from chats to determine the mood and feelings of a visitor and adapt responses accordingly. Decision Tree: An “If this… then that” framework that guides the customer to choose from a list of pre-defined scripts and options.
Moment Analysis. Call recordings are analyzed for important moments that indicate whether reps are following or deviating from their call plan/script. Sentiment Analysis. Conversation intelligence software provides sentiment analysis based on voice tone, word choice, and other cues. Analytics and Benchmarking.
You can use few-shot prompting for a variety of tasks, such as sentiment analysis, entity recognition, question answering, translation, and code generation. Their research indicates that zero-shot CoT, using the same single-prompt template, significantly outperforms zero-shot FM performances on diverse benchmark reasoning tasks.
Overview of exploratory data analysis (EDA) and data preparation in Data Wrangler. Import required packages for data analysis and visualization. In Data Wrangler, you can choose a smaller instance type for certain transformations or analysis and then upscale the instance to a larger type and carry out complex transformations.
Laying the groundwork: Collecting ground truth data The foundation of any successful agent is high-quality ground truth data—the accurate, real-world observations used as reference for benchmarks and evaluating the performance of a model, algorithm, or system. To achieve thorough testing, consider using AI to generate diverse test cases.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content