This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
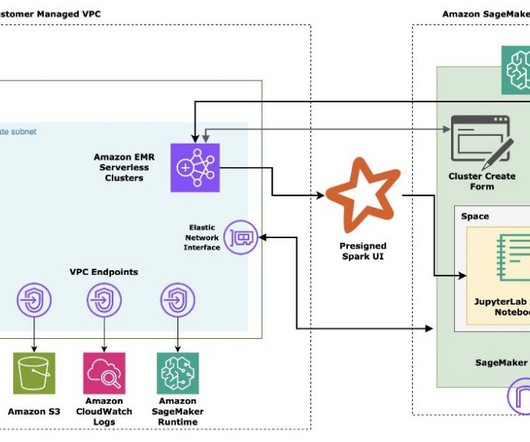
Solution overview Our solution implements a verified semantic cache using the Amazon Bedrock Knowledge Bases Retrieve API to reduce hallucinations in LLM responses while simultaneously improving latency and reducing costs. The function checks the semantic cache (Amazon Bedrock Knowledge Bases) using the Retrieve API.
They provide access to external data and APIs or enable specific actions and computation. With more than 20 years of experience in dataanalytics and enterprise applications, he has driven technological innovation across both the public and private sectors. Tools Tools extend agent capabilities beyond the FM.
Agent Creator is a versatile extension to the SnapLogic platform that is compatible with modern databases, APIs, and even legacy mainframe systems, fostering seamless integration across various data environments. The integration with Amazon Bedrock is achieved through the Amazon Bedrock InvokeModel APIs.
We also look into how to further use the extracted structured information from claims data to get insights using AWS Analytics and visualization services. We highlight on how extracted structured data from IDP can help against fraudulent claims using AWS Analytics services. Extraction phase. client('comprehend').
Harnessing the power of bigdata has become increasingly critical for businesses looking to gain a competitive edge. However, managing the complex infrastructure required for bigdata workloads has traditionally been a significant challenge, often requiring specialized expertise.
However, as a new product in a new space for Amazon, Amp needed more relevant data to inform their decision-making process. Part 1 shows how data was collected and processed using the data and analytics platform, and Part 2 shows how the data was used to create show recommendations using Amazon SageMaker , a fully managed ML service.
The Slack application sends the event to Amazon API Gateway , which is used in the event subscription. API Gateway forwards the event to an AWS Lambda function. About the Authors Rushabh Lokhande is a Senior Data & ML Engineer with AWS Professional Services Analytics Practice.
This is a guest post co-written with Vicente Cruz Mínguez, Head of Data and Advanced Analytics at Cepsa Química, and Marcos Fernández Díaz, Senior Data Scientist at Keepler. About the authors Vicente Cruz Mínguez is the Head of Data & Advanced Analytics at Cepsa Química.
ZOE is a multi-agent LLM application that integrates with multiple data sources to provide a unified view of the customer, simplify analytics queries, and facilitate marketing campaign creation. From our experience, artifact server has some limitations, such as limits on artifact size (because of sending it using REST API).
This virtual conference will cover a ranging of topics, expert speakers, partners and customers about better customer and agent experiences through speech analytics. This is a great opportunity to listen, watch, and learn the latest CX analytics information out there! Text and Speech Analytics are Not Created Equal.
It’s a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like Anthropic, Cohere, Meta, Mistral AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
The Retrieve and RetrieveAndGenerate APIs allow your applications to directly query the index using a unified and standard syntax without having to learn separate APIs for each different vector database, reducing the need to write custom index queries against your vector store.
Today, a large amount of data is available in traditional dataanalytics, data warehousing, and databases, which may be not easy to query or understand for the majority of organization members. In entered the BigData space in 2013 and continues to explore that area. Arghya Banerjee is a Sr.
2019 was the year of artificial intelligence (AI), automation and analytics, a trend that has continued in 2020 and into the foreseeable future, despite the pandemic. Adoption of cloud-based recording is starting to pick up momentum, as is analytics-enabled quality management (QM). . WFO Trends in 2020.
In todays customer-first world, monitoring and improving call center performance through analytics is no longer a luxuryits a necessity. Utilizing call center analytics software is crucial for improving operational efficiency and enhancing customer experience. What Are Call Center Analytics?
The underlying technologies of composability include some combination of artificial intelligence (AI), machine learning, automation, container-based architecture, bigdata, analytics, low-code and no-code development, Agile/DevOps deployment, cloud delivery, and applications with open APIs (microservices).
Generative AI models have the potential to revolutionize enterprise operations, but businesses must carefully consider how to harness their power while overcoming challenges such as safeguarding data and ensuring the quality of AI-generated content.
Snowflake is a cloud data platform that provides data solutions for data warehousing to data science. Snowflake is an AWS Partner with multiple AWS accreditations, including AWS competencies in machine learning (ML), retail, and data and analytics. Configure Snowflake. Configure SageMaker Studio.
Affinities are computed either implicitly from the user’s behavioral data or explicitly from topics of interest (such as pop music, baseball, or politics) as provided in their user profiles. This is Part 2 of a series on using dataanalytics and ML for Amp and creating a personalized show recommendation list platform.
Tweet Managing your API’s has become a very complicated endeavor. If your role to is manage API’s it’s important to figure out how to automate that process. Today 3scale and Pivotal ® announced that the 3scale self-serve API management solution is available through the Pivotal Web Services (PWS) platform.
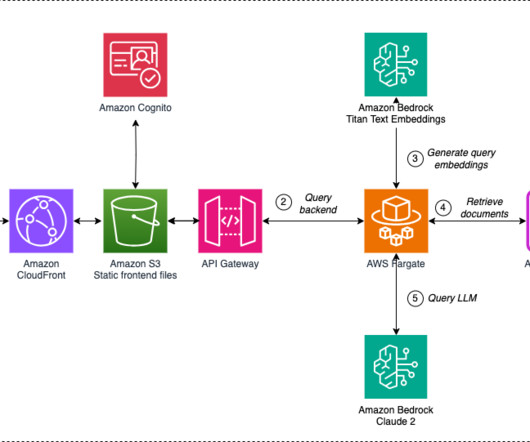
This solution uses an Amazon Cognito user pool as an OAuth-compatible identity provider (IdP), which is required in order to exchange a token with AWS IAM Identity Center and later on interact with the Amazon Q Business APIs. Amazon Q uses the chat_sync API to carry out the conversation.
Homomorphic encryption is a new approach to encryption that allows computations and analytical functions to be run on encrypted data, without first having to decrypt it, in order to preserve privacy in cases where you have a policy that states data should never be decrypted.
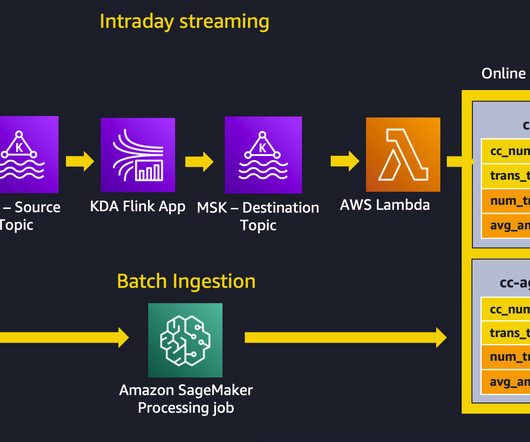
Streaming ingestion – An Amazon Kinesis DataAnalytics for Apache Flink application backed by Apache Kafka topics in Amazon Managed Streaming for Apache Kafka (MSK) (Amazon MSK) calculates aggregated features from a transaction stream, and an AWS Lambda function updates the online feature store.
Customers can also access offline store data using a Spark runtime and perform bigdata processing for ML feature analysis and feature engineering use cases. Table formats provide a way to abstract data files as a table. Apache Iceberg is an open table format for very large analytic datasets.
Among all, the native time series capabilities is a standout feature, making it ideal for a managing high volume of time-series data, such as business critical application data, telemetry, server logs and more. With efficient querying, aggregation, and analytics, businesses can extract valuable insights from time-stamped data.
You can change the configuration later from the SageMaker Canvas UI or using SageMaker APIs. About the Authors Rushabh Lokhande is a Senior Data & ML Engineer with AWS Professional Services Analytics Practice. He helps customers implement bigdata, machine learning, analytics solutions, and generative AI implementations.
The financial services industry (FSI) is no exception to this, and is a well-established producer and consumer of data and analytics. These activities cover disparate fields such as basic data processing, analytics, and machine learning (ML). The CUDA API and SDK were first released by NVIDIA in 2007.
The solution also uses SAML attribute mapping to populate the SAML assertion with specific access-relevant data, such as user ID and user team. Because the solution creates a SAML API, you can use any IdP supporting SAML assertions to create this architecture. The API Gateway calls an SAML backend API. Custom SAML 2.0
Leveraging today’s innovative speech recognition technology and predictive analytics is the key to creating a customer-centric culture in the call center. Leveraging today’s innovative speech recognition technology and predictive analytics is the key to creating a customer-centric culture in the call center.”
Leveraging today’s innovative speech recognition technology and predictive analytics is the key to creating a customer-centric culture in the call center. Leveraging today’s innovative speech recognition technology and predictive analytics is the key to creating a customer-centric culture in the call center.”
The “platform as a service” paradigm, which essentially leverages application programming interfaces (APIs) to build out functional capabilities, makes it easier to build your own solution (BYOS). It’s undeniable that contact center platform vendors are having a highly positive disruptive impact on the pace of innovation in the CBCCI sector.
For production, we wanted to invoke the model as a simple API call. We found that we didn’t need to separate data preparation, model training, and prediction, and it was convenient to package the whole pipeline as a single script and use SageMaker processing. Packaging the solution as a scalable workflow.
The Data Analyst Course With the Data Analyst Course, you will be able to become a professional in this area, developing all the necessary skills to succeed in your career. The course also teaches beginner and advanced Python, basics and advanced NumPy and Pandas, and data visualization. Workload: 20.5
They use bigdata (such as a history of past search queries) to provide many powerful yet easy-to-use patent tools. In this section, we show how to build your own container, deploy your own GPT-2 model, and test with the SageMaker endpoint API. implement the model and the inference API. gpt2 and predictor.py
Let’s invoke the Amazon OpenSearch API to search relevant documents for the generated vector embeddings. His knowledge ranges from application architecture to bigdata, analytics, and machine learning. Add a custom transform with Python (PySpark). Add a custom transform with Python (PySpark).
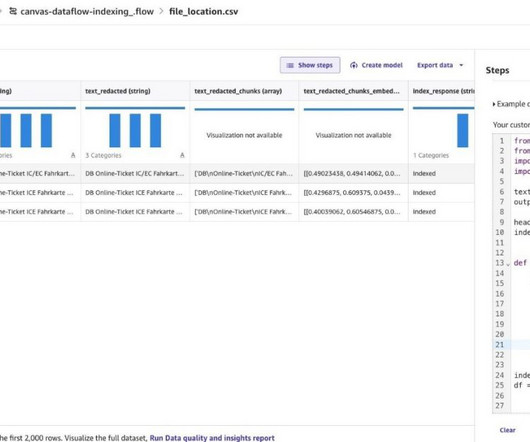
Perform intelligent search with Amazon Kendra Before you try searching on the Amazon Kendra console or using the API, make sure that the data source sync is complete. To check, view the data sources and verify if the last sync was successful. She is passionate about designing bigdata workloads cloud-natively.
With the use of cloud computing, bigdata and machine learning (ML) tools like Amazon Athena or Amazon SageMaker have become available and useable by anyone without much effort in creation and maintenance. This dilemma hampers the creation of efficient models that use data to generate business-relevant insights.
The Step Functions state machine is configured with an AWS Lambda function to retrieve data from the Splunk index using the Splunk Enterprise SDK for Python. The SPL query requested through this REST API call is scoped to only retrieve the data of interest. Lambda supports container images.
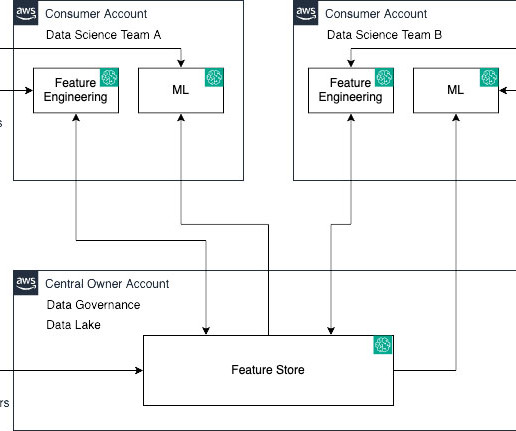
For example, the analytics team may curate features like customer profile, transaction history, and product catalogs in a central management account. His expertise spans a broad spectrum, encompassing scalable architectures, distributed computing, bigdataanalytics, micro services and cloud infrastructures for organizations.
Prior to our adoption of Kubeflow on AWS, our data scientists used a standardized set of tools and a process that allowed flexibility in the technology and workflow used to train a given model. As we noted in the previous section, data scientists perform exploratory data analyses, run dataanalytics, and train ML models.
Amazon Bedrock is a fully managed service that offers a choice of high-performing FMs from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral, Stability AI, and Amazon within a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
This might be a triggering mechanism via Amazon EventBridge , Amazon API Gateway , AWS Lambda functions, or SageMaker Pipelines. In addition to the model endpoint, the CI/CD also tests the triggering infrastructure, such as EventBridge, Lambda functions, or API Gateway. Data lake and MLOps integration.
With AI-powered tools and analytics, it has become easier than ever to build not just one story but customized stories to appear to end-users’ unique tastes and sensibilities. After ingestion, images can be searched via the Amazon Kendra search console, API, or SDK. Tanvi Singhal is a Data Scientist within AWS Professional Services.
Edge is a term that refers to a location, far from the cloud or a bigdata center, where you have a computer device (edge device) capable of running (edge) applications. How do I eliminate the need of installing a big framework like TensorFlow or PyTorch on my restricted device? Edge computing.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content