This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this post, we explore how you can use Amazon Bedrock to generate high-quality categorical ground truth data, which is crucial for training machine learning (ML) models in a cost-sensitive environment. For the multiclass classification problem to label support case data, synthetic data generation can quickly result in overfitting.
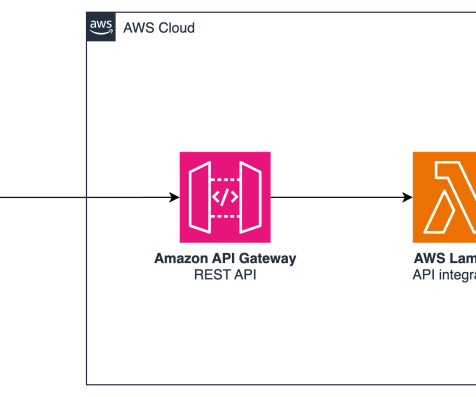
It also uses a number of other AWS services such as Amazon API Gateway , AWS Lambda , and Amazon SageMaker. API Gateway is serverless and hence automatically scales with traffic. API Gateway also provides a WebSocket API. At this point, you need to consider the use case and data isolation requirements.
All of this data is centralized and can be used to improve metrics in scenarios such as sales or call centers. These insights are stored in a central repository, unlocking the ability for analytics teams to have a single view of interactions and use the data to formulate better sales and support strategies.
Generative AI is rapidly transforming the modern workplace, offering unprecedented capabilities that augment how we interact with text and data. Note that these APIs use objects as namespaces, alleviating the need for explicit imports. API Gateway supports multiple mechanisms for controlling and managing access to an API.
In my decade working with customers data journeys, Ive seen that an organizations most valuable asset is its domain-specific data and expertise. The team deployed dozens of models on SageMaker AI endpoints, using Triton Inference Servers model concurrency capabilities to scale globally across AWS data centers.
Furthermore, evaluation processes are important not only for LLMs, but are becoming essential for assessing prompt template quality, input data quality, and ultimately, the entire application stack. SageMaker is a data, analytics, and AI/ML platform, which we will use in conjunction with FMEval to streamline the evaluation process.
Recently, we’ve been witnessing the rapid development and evolution of generative AI applications, with observability and evaluation emerging as critical aspects for developers, data scientists, and stakeholders. This feature allows you to separate data into logical partitions, making it easier to analyze and process data later.
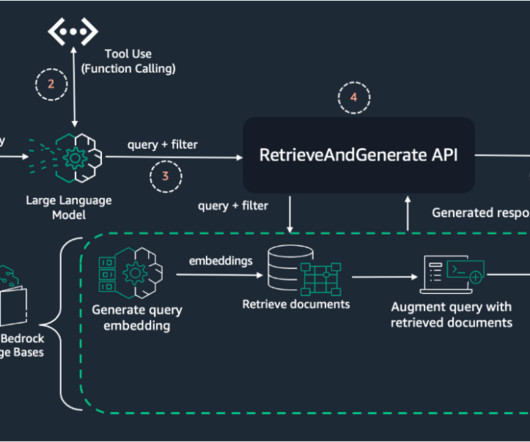
While these models are trained on vast amounts of generic data, they often lack the organization-specific context and up-to-date information needed for accurate responses in business settings. The function checks the semantic cache (Amazon Bedrock Knowledge Bases) using the Retrieve API. which is received by the Invoke Agent function.
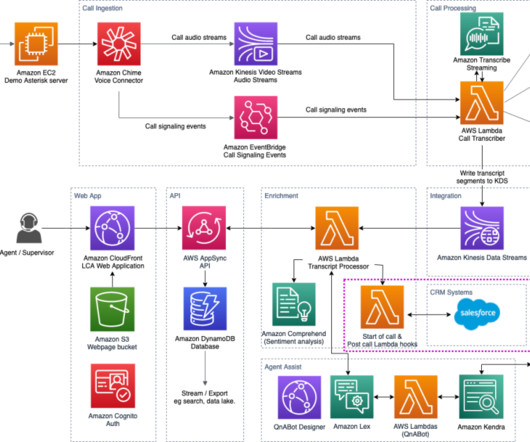
This is the only way to ensure your speech analytics solution is adequately interpreting and transcribing both your agents and your customers. REAL TIME - Does your recording solution capture call audio in a real-time streaming manner so your transcription and analytics engine can process the call as it happens, or post-call?
However, the technology also comes with considerable data security and privacy concerns. Maximizing your investment in AI means navigating these roadblocks without compromising on privacy and data security for sensitive company info, customer data, and proprietary information.
To address these issues, we launched a generative artificial intelligence (AI) call summarization feature in Amazon Transcribe Call Analytics. Simply turn the feature on from the Amazon Transcribe console or using the start_call_analytics_job API. You can upload a call recording in Amazon S3 and start a Transcribe Call Analytics job.
The opportunities to unlock value using AI in the commercial real estate lifecycle starts with data at scale. Although CBRE provides customers their curated best-in-class dashboards, CBRE wanted to provide a solution for their customers to quickly make custom queries of their data using only natural language prompts.
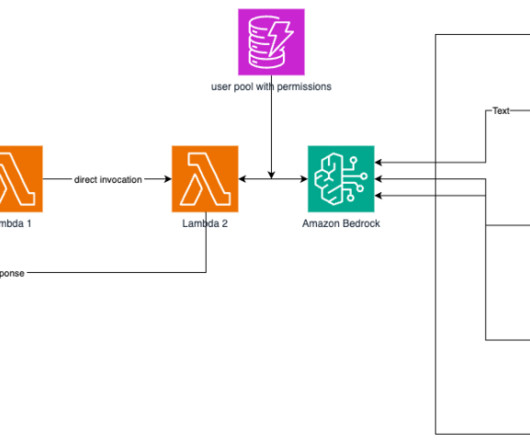
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
Principal wanted to use existing internal FAQs, documentation, and unstructured data and build an intelligent chatbot that could provide quick access to the right information for different roles. The chatbot improved access to enterprise data and increased productivity across the organization.
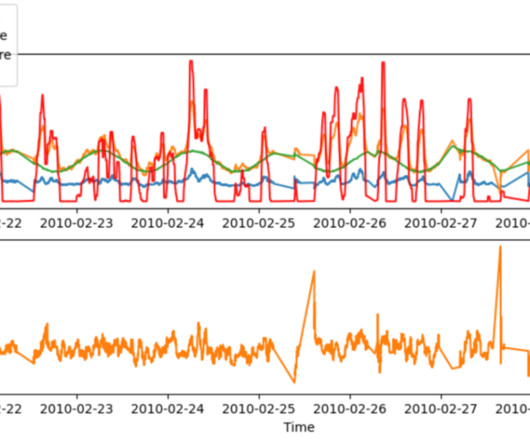
Near-real-time delivery of data and insights enable businesses to rapidly respond to their customers’ needs. Real-time data can come from a variety of sources, including social media, IoT devices, infrastructure monitoring, call center monitoring, and more. After that, documents are free of PII entities and users can consume the data.
Many organizations have been using a combination of on-premises and open source data science solutions to create and manage machine learning (ML) models. Data science and DevOps teams may face challenges managing these isolated tool stacks and systems.
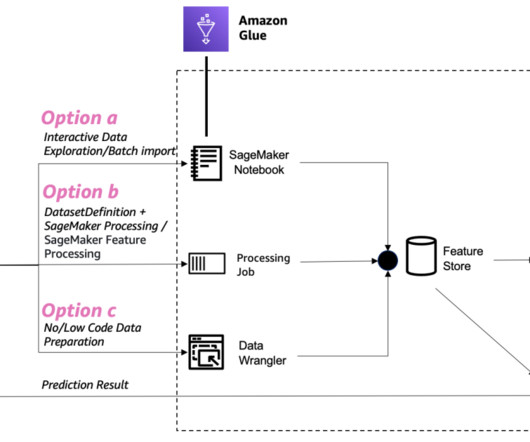
In this post, we show how to configure a new OAuth-based authentication feature for using Snowflake in Amazon SageMaker Data Wrangler. Snowflake is a cloud data platform that provides data solutions for data warehousing to data science. For more information about prerequisites, see Get Started with Data Wrangler.
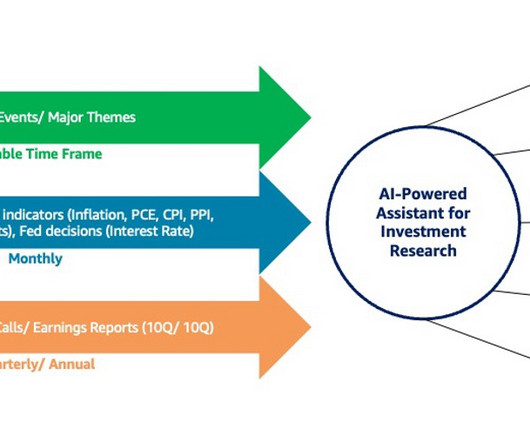
Financial analysts and research analysts in capital markets distill business insights from financial and non-financial data, such as public filings, earnings call recordings, market research publications, and economic reports, using a variety of tools for data mining.
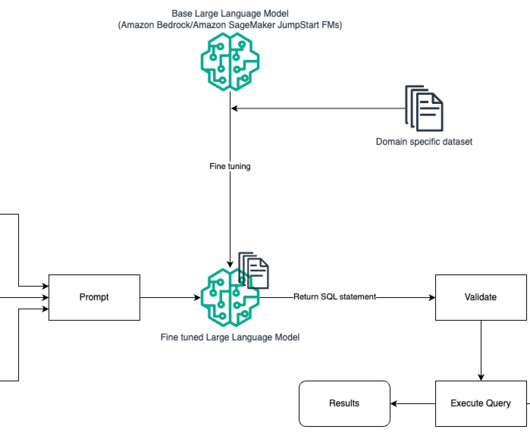
One such area that is evolving is using natural language processing (NLP) to unlock new opportunities for accessing data through intuitive SQL queries. Instead of dealing with complex technical code, business users and data analysts can ask questions related to data and insights in plain language.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
We also look into how to further use the extracted structured information from claims data to get insights using AWS Analytics and visualization services. We highlight on how extracted structured data from IDP can help against fraudulent claims using AWS Analytics services. Part 2: Data enrichment and insights.
Analyzing real-world healthcare and life sciences (HCLS) data poses several practical challenges, such as distributed data silos, lack of sufficient data at any single site for rare events, regulatory guidelines that prohibit data sharing, infrastructure requirement, and cost incurred in creating a centralized data repository.
To build a generative AI -based conversational application integrated with relevant data sources, an enterprise needs to invest time, money, and people. First, you would need build connectors to the data sources. For a full list of supported data source connectors, see Amazon Q Business connectors.
In the context of generative AI , significant progress has been made in developing multimodal embedding models that can embed various data modalities—such as text, image, video, and audio data—into a shared vector space. Each data point in the database is associated with a vector that encapsulates its attributes or features.
Gen AI offers enormous potential for efficiency, knowledge sharing, and analytical insight in the contact center. There are several ways to work with Gen AI and LLMs, from SaaS applications with embedded Gen AI to custom-built LLMs to applications that bring in Gen AI and LLM capabilities via API. Is it an API model?
Implementing a modern data architecture provides a scalable method to integrate data from disparate sources. By organizing data by business domains instead of infrastructure, each domain can choose tools that suit their needs. However, realizing the full benefits requires overcoming some challenges.
Data privacy and network security With Amazon Bedrock, you are in control of your data, and all your inputs and customizations remain private to your AWS account. Your data remains in the AWS Region where the API call is processed. All data is encrypted in transit and at rest.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
Are you looking to optimize your call center’s efficiency and streamline your business’s data management process? If so, it’s crucial to find the right call center software vendor that integrates with a customer data platform (CDP). Managing customer data is nothing new.
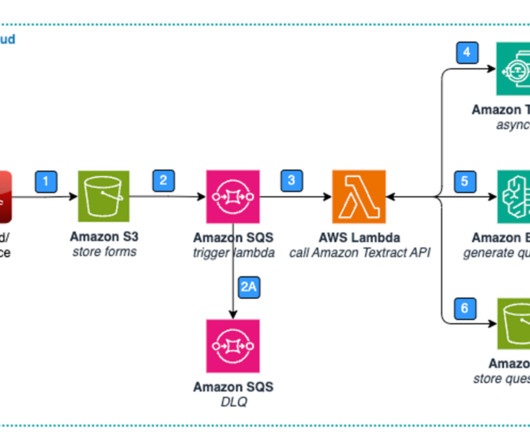
However, there are benefits to building an FM-based classifier using an API service such as Amazon Bedrock, such as the speed to develop the system, the ability to switch between models, rapid experimentation for prompt engineering iterations, and the extensibility into other related classification tasks. Each page is saved as an image.
The Live Call Analytics with Agent Assist (LCA) open-source solution addresses these challenges by providing features such as AI-powered agent assistance, call transcription, call summarization, and much more. Under Available OAuth Scopes , choose Manage user data via APIs (api). We’ve all been there. Choose Save.
In case you think the horror is confined to voice interactions, don’t forget the sense of dread you feel when clicking through 13 webpages on your smartphone while your data charges rack up just to reach the appropriate contact button. Insight technologies that deliver personalization and predictive analytics. Three-quarters of U.S.
Generative artificial intelligence (AI) provides an opportunity for improvements in healthcare by combining and analyzing structured and unstructured data across previously disconnected silos. Figure 1: Architecture – Standard Form – Data Extraction & Storage.
Data-driven decisions fueled by near-real-time insights can enable farmers to close the gap on increased food demand. However, scouting each field on a frequent basis for large fields and farms is not feasible, and successful risk mitigation requires an integrated agronomic data platform that can bring insights at scale.
Forecasting Core Features The Ability to Consume Historical Data Whether it’s from a copy/paste of a spreadsheet or an API connection, your WFM platform must have the ability to consume historical data. However, it’s helpful to capture those events and store them for future use.
However, these models require massive amounts of clean, structured training data to reach their full potential. Most real-world data exists in unstructured formats like PDFs, which requires preprocessing before it can be used effectively. According to IDC , unstructured data accounts for over 80% of all business data today.
Our commitment to innovation led us to a pivotal challenge: how to harness the power of machine learning (ML) to further enhance our competitive edge while balancing this technological advancement with strict data security requirements and the need to streamline access to our existing internal resources.
With the use of cloud computing, big data and machine learning (ML) tools like Amazon Athena or Amazon SageMaker have become available and useable by anyone without much effort in creation and maintenance. This dilemma hampers the creation of efficient models that use data to generate business-relevant insights.
In addition to enabling communications, omnichannel contact center software typically tracks interactions, automates workflows, and provides data insights to improve performance. Data-Driven Insights, Continuous Improvement The integrated nature of an omnichannel contact center provides valuable data insights.
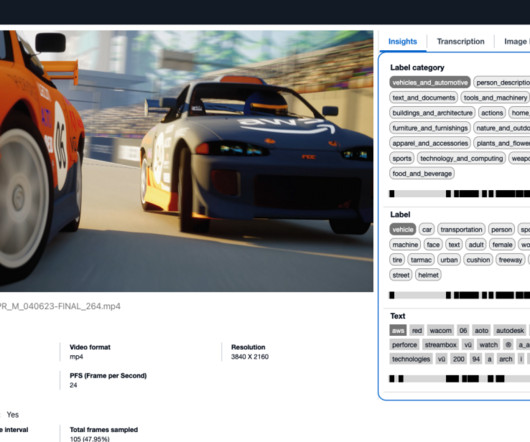
The frontend UI interacts with the extract microservice through a RESTful interface provided by Amazon API Gateway. It offers details of the extracted video information and includes a lightweight analytics UI for dynamic LLM analysis. Detect generic objects and labels using the Amazon Rekognition label detection API.
Twilio enables companies to use communications and data to add intelligence and security to every step of the customer journey, from sales and marketing to growth, customer service, and many more engagement use cases in a flexible, programmatic way. Data is the foundational layer for all generative AI and ML applications.
As organizations incorporate machine learning (ML) and analytics into their applications, using this data can provide insights on how to create more seamless customer experiences. However, the presence of PII information often restricts the use of this data. Let’s review how we can redact this PII data in the transcript.
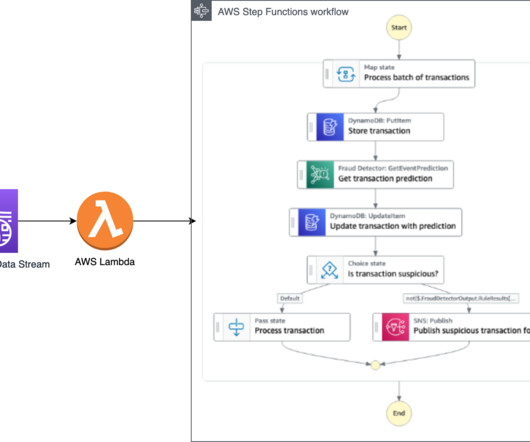
We show how you can apply this approach to various data streaming and event-driven architectures, depending on the desired outcome and actions to take to prevent fraud (such as alert the user about the fraud or flag the transaction for additional review). Call the Amazon Fraud Detector API using the GetEventPrediction action.
Amazon Redshift is the most popular cloud data warehouse that is used by tens of thousands of customers to analyze exabytes of data every day. It provides a single web-based visual interface where you can perform all ML development steps, including preparing data and building, training, and deploying models.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content