This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
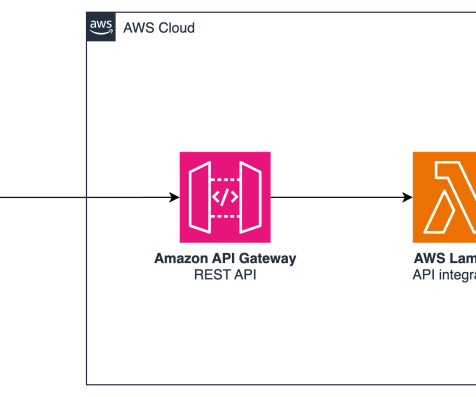
Note that these APIs use objects as namespaces, alleviating the need for explicit imports. API Gateway supports multiple mechanisms for controlling and managing access to an API. AWS Lambda handles the REST API integration, processing the requests and invoking the appropriate AWS services.
Google Drive supports storing documents such as Emails contain a wealth of information found in different places, such as within the subject of an email, the message content, or even attachments. Types of documents Gmail messages can be sorted and stored inside your email inbox using folders and labels.
These insights are stored in a central repository, unlocking the ability for analytics teams to have a single view of interactions and use the data to formulate better sales and support strategies. With Lambda integration, we can create a web API with an endpoint to the Lambda function.
It also uses a number of other AWS services such as Amazon API Gateway , AWS Lambda , and Amazon SageMaker. API Gateway is serverless and hence automatically scales with traffic. API Gateway also provides a WebSocket API. Incoming requests to the gateway go through this point.
Principal wanted to use existing internal FAQs, documentation, and unstructured data and build an intelligent chatbot that could provide quick access to the right information for different roles. As Principal grew, its internal support knowledge base considerably expanded.
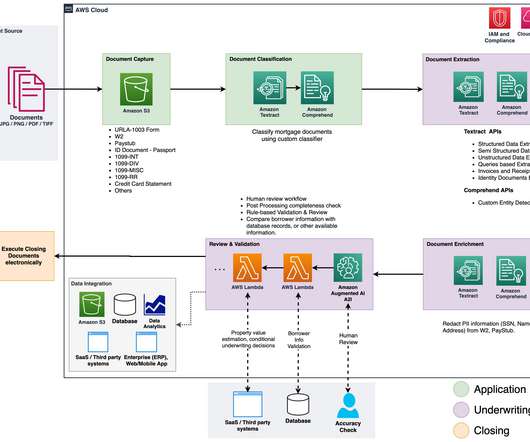
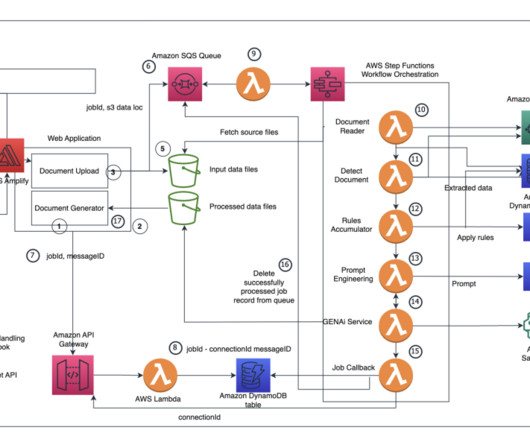
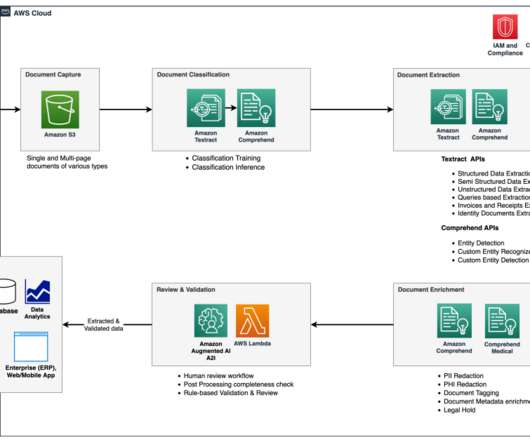
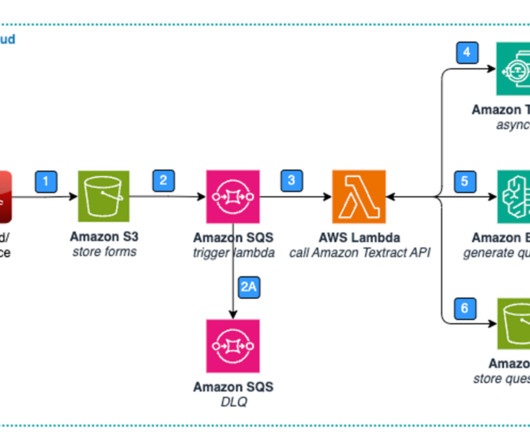
Organizations in the lending and mortgage industry process thousands of documents on a daily basis. From a new mortgage application to mortgage refinance, these business processes involve hundreds of documents per application. At the start of the process, documents are uploaded to an Amazon Simple Storage Service (Amazon S3) bucket.
By narrowing down the search space to the most relevant documents or chunks, metadata filtering reduces noise and irrelevant information, enabling the LLM to focus on the most relevant content. This approach narrows down the search space to the most relevant documents or passages, reducing noise and irrelevant information.
Lets say the task at hand is to predict the root cause categories (Customer Education, Feature Request, Software Defect, Documentation Improvement, Security Awareness, and Billing Inquiry) for customer support cases. We suggest consulting LLM prompt engineering documentation such as Anthropic prompt engineering for experiments.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies such as AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon through a single API, along with a broad set of capabilities you need to build generative AI applications with security, privacy, and responsible AI.
In Part 1 of this series, we discussed intelligent document processing (IDP), and how IDP can accelerate claims processing use cases in the insurance industry. We discussed how we can use AWS AI services to accurately categorize claims documents along with supporting documents. Part 1: Classification and extraction of documents.
By documenting the specific model versions, fine-tuning parameters, and prompt engineering techniques employed, teams can better understand the factors contributing to their AI systems performance. SageMaker is a data, analytics, and AI/ML platform, which we will use in conjunction with FMEval to streamline the evaluation process.
Such data often lacks the specialized knowledge contained in internal documents available in modern businesses, which is typically needed to get accurate answers in domains such as pharmaceutical research, financial investigation, and customer support. This task involves answering analytical reasoning questions.
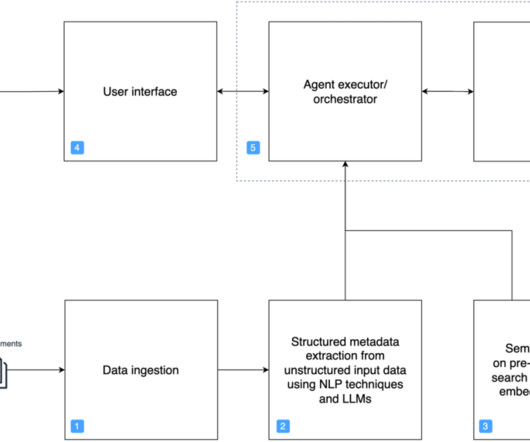
We demonstrate how to harness the power of LLMs to build an intelligent, scalable system that analyzes architecture documents and generates insightful recommendations based on AWS Well-Architected best practices. An interactive chat interface allows deeper exploration of both the original document and generated content.
A key part of the submission process is authoring regulatory documents like the Common Technical Document (CTD), a comprehensive standard formatted document for submitting applications, amendments, supplements, and reports to the FDA. The tedious process of compiling hundreds of documents is also prone to errors.
This is the scenario for companies that rely on manual processes for document generationcaught in a cycle of repetitive data entry, missing critical details, non-compliance, and whatnot. Every document you produce is an opportunity to reinforce your brands identity, tone, and professionalism. What is Document Generation Software?
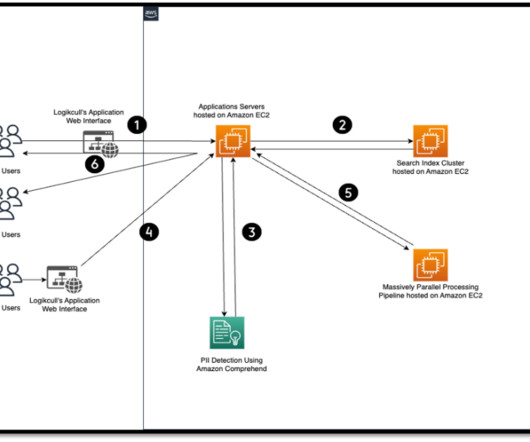
Organizations can search for PII using methods such as keyword searches, pattern matching, data loss prevention tools, machine learning (ML), metadata analysis, data classification software, optical character recognition (OCR), document fingerprinting, and encryption.
In today’s information age, the vast volumes of data housed in countless documents present both a challenge and an opportunity for businesses. Traditional document processing methods often fall short in efficiency and accuracy, leaving room for innovation, cost-efficiency, and optimizations. However, the potential doesn’t end there.
These sessions, featuring Amazon Q Business , Amazon Q Developer , Amazon Q in QuickSight , and Amazon Q Connect , span the AI/ML, DevOps and Developer Productivity, Analytics, and Business Applications topics. Hear from Availity on how 1.5
Question and answering (Q&A) using documents is a commonly used application in various use cases like customer support chatbots, legal research assistants, and healthcare advisors. In this collaboration, the AWS GenAIIC team created a RAG-based solution for Deltek to enable Q&A on single and multiple government solicitation documents.
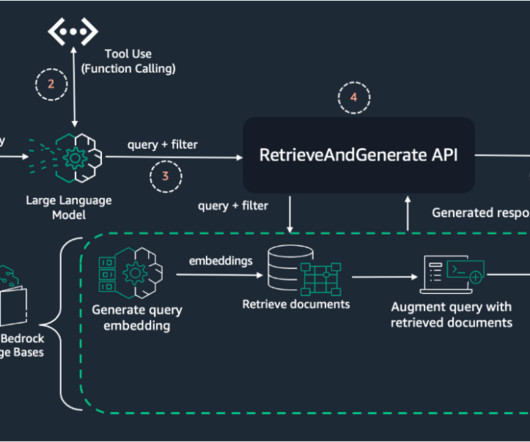
Solution overview Our solution implements a verified semantic cache using the Amazon Bedrock Knowledge Bases Retrieve API to reduce hallucinations in LLM responses while simultaneously improving latency and reducing costs. The function checks the semantic cache (Amazon Bedrock Knowledge Bases) using the Retrieve API.
The goal of intelligent document processing (IDP) is to help your organization make faster and more accurate decisions by applying AI to process your paperwork. Insurance customers can automate this process using AWS AI services to automate the document processing pipeline for claims processing. Part 2: Data enrichment and insights.
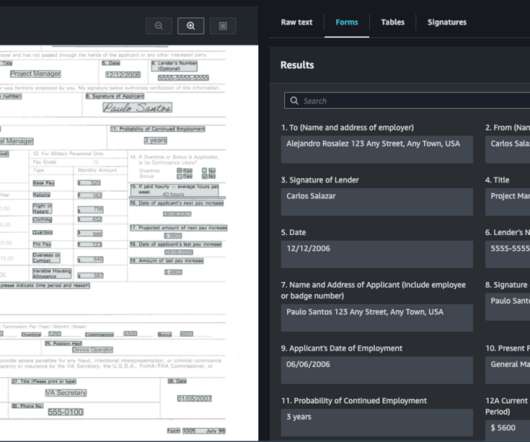
Amazon Textract is a machine learning (ML) service that automatically extracts text, handwriting, and data from any document or image. AnalyzeDocument Signatures is a feature within Amazon Textract that offers the ability to automatically detect signatures on any document. Lastly, we share some best practices for using this feature.
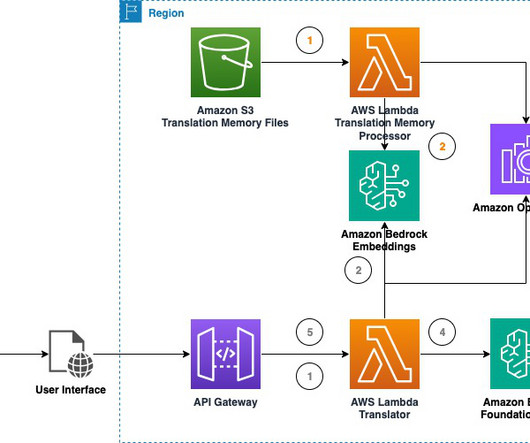
The solution offers two TM retrieval modes for users to choose from: vector and document search. When using the Amazon OpenSearch Service adapter (document search), translation unit groupings are parsed and stored into an index dedicated to the uploaded file. For this post, we use a document store. Choose With Document Store.
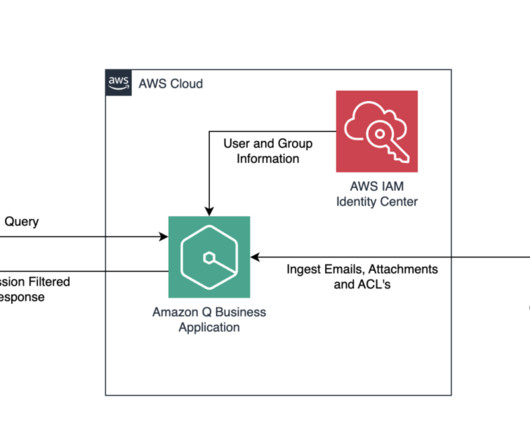
This post shows how to configure an Amazon Q Business custom connector and derive insights by creating a generative AI-powered conversation experience on AWS using Amazon Q Business while using access control lists (ACLs) to restrict access to documents based on user permissions. Who are the data stewards for my proprietary database sources?
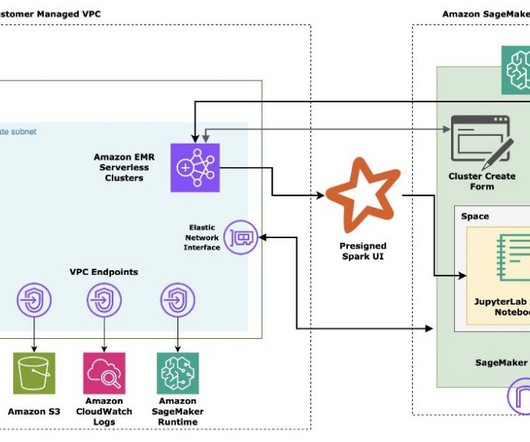
By using the Livy REST APIs , SageMaker Studio users can also extend their interactive analytics workflows beyond just notebook-based scenarios, enabling a more comprehensive and streamlined data science experience within the Amazon SageMaker ecosystem. After conversion, the documents are split into chunks and prepared for embedding.
Organizations across industries such as healthcare, finance and lending, legal, retail, and manufacturing often have to deal with a lot of documents in their day-to-day business processes. There is limited automation available today to process and extract information from these documents.
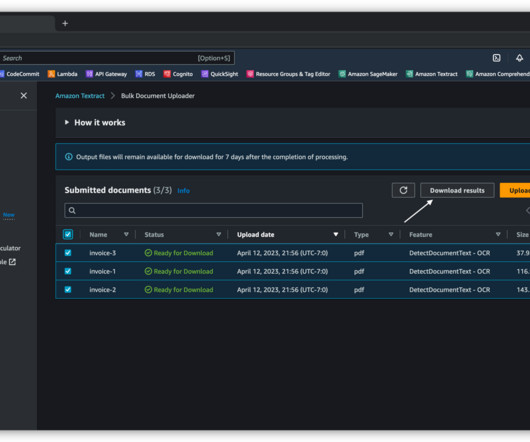
Amazon Textract is a machine learning (ML) service that automatically extracts text, handwriting, and data from any document or image. In this post, we walk through when and how to use the Amazon Textract Bulk Document Uploader to evaluate how Amazon Textract performs on your documents.
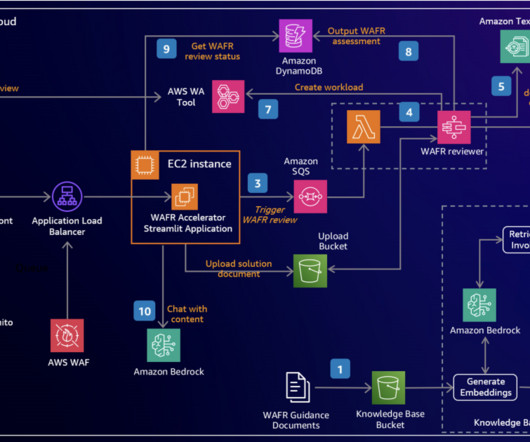
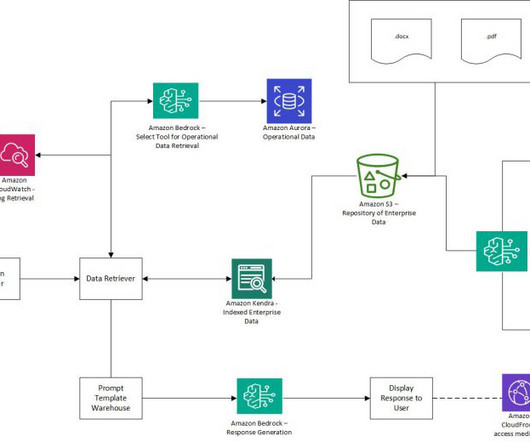
In this post, we review how Aetion is using Amazon Bedrock to help streamline the analytical process toward producing decision-grade real-world evidence and enable users without data science expertise to interact with complex real-world datasets. The following diagram illustrates the solution architecture.
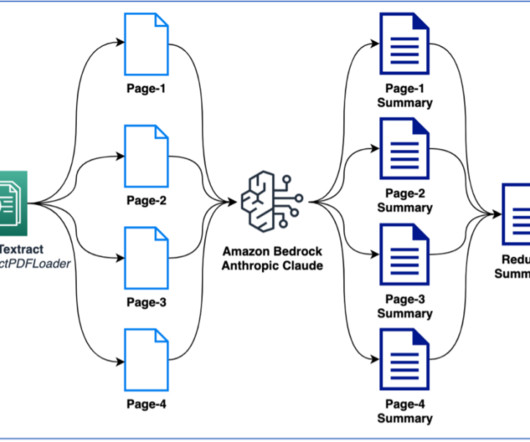
Amazon’s intelligent document processing (IDP) helps you speed up your business decision cycles and reduce costs. Across multiple industries, customers need to process millions of documents per year in the course of their business. The following figure shows the stages that are typically part of an IDP workflow.
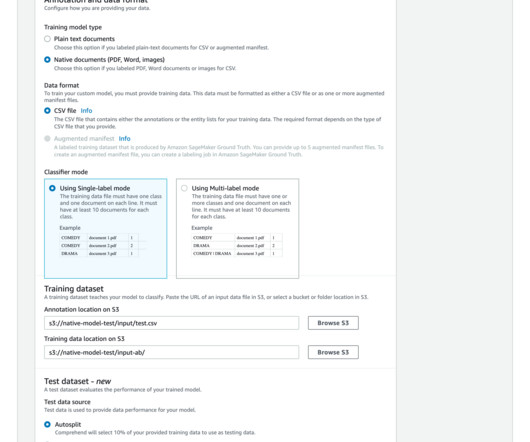
The ability to effectively handle and process enormous amounts of documents has become essential for enterprises in the modern world. Due to the continuous influx of information that all enterprises deal with, manually classifying documents is no longer a viable option.
Current challenges faced by enterprises Modern enterprises face numerous challenges, including: Managing vast amounts of unstructured data: Enterprises deal with immense volumes of data generated from various sources such as emails, documents, and customer interactions.
The Amazon Bedrock single API access, regardless of the models you choose, gives you the flexibility to use different FMs and upgrade to the latest model versions with minimal code changes. Amazon Titan FMs provide customers with a breadth of high-performing image, multimodal, and text model choices, through a fully managed API.
The healthcare industry generates and collects a significant amount of unstructured textual data, including clinical documentation such as patient information, medical history, and test results, as well as non-clinical documentation like administrative records. Lastly, the Lambda function stores the question list in Amazon S3.
“Intelligent document processing (IDP) solutions extract data to support automation of high-volume, repetitive document processing tasks and for analysis and insight. Customers spend a significant amount of time and effort identifying documents and extracting critical information from them for various use cases.
However, there are benefits to building an FM-based classifier using an API service such as Amazon Bedrock, such as the speed to develop the system, the ability to switch between models, rapid experimentation for prompt engineering iterations, and the extensibility into other related classification tasks.
Verisk (Nasdaq: VRSK) is a leading data analytics and technology partner for the global insurance industry. Through advanced analytics, software, research, and industry expertise across over 20 countries, Verisk helps build resilience for individuals, communities, and businesses.
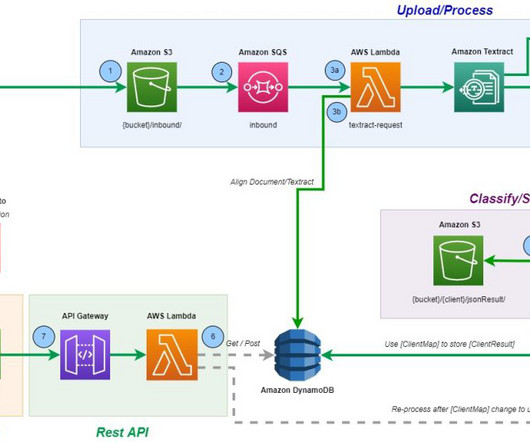
It starts with a document capture stage to securely collect and store scanned invoices and receipts. Approved and rejected documents go to their respective folders within the Amazon Simple Storage Service (Amazon S3) bucket. For approved documents, you can search all the extracted fields and values using Amazon OpenSearch Service.
It is typically helpful when working with lengthy documents such as entire books. on Amazon Bedrock would be equivalent to roughly 150,000 words or over 500 pages of documents. The Amazon Bedrock API returns the output Q&A JSON file to the Lambda function. The JSON file is returned to API Gateway. English characters.
This is because trades involve different counterparties and there is a high degree of variation among documents containing commercial terms (such as trade date, value date, and counterparties). Intelligent document processing (IDP) applies AI/ML techniques to automate data extraction from documents.
It enables searching over both the content of documents and their underlying meaning. This requires searching over large collections of documents with diverse content, such as website data, which can include various topics such as sustainability, leadership, financial results, and more.
Knowledge Bases for Amazon Bedrock automates synchronization of your data with your vector store, including diffing the data when it’s updated, document loading, and chunking, as well as semantic embedding. It then employs a language model to generate a response by considering both the retrieved documents and the original query.
Solution overview Responses are personalized by Amazon Q Business by determining if the user’s query could be enhanced by augmenting the query with known attributes of the user and transparently using the personalized query to retrieve documents from its search index. or OIDC is used for the provider.
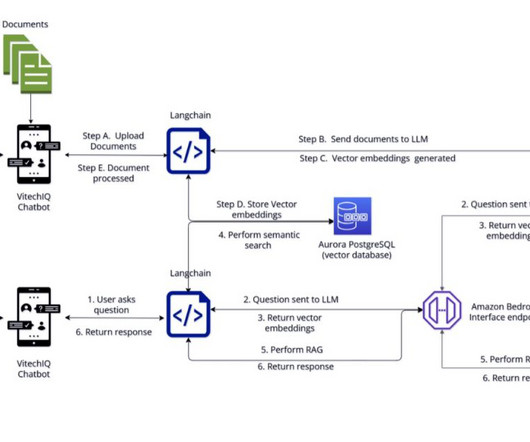
Vitech helps group insurance, pension fund administration, and investment clients expand their offerings and capabilities, streamline their operations, and gain analytical insights. Data store Vitech’s product documentation is largely available in.pdf format, making it the standard format used by VitechIQ.
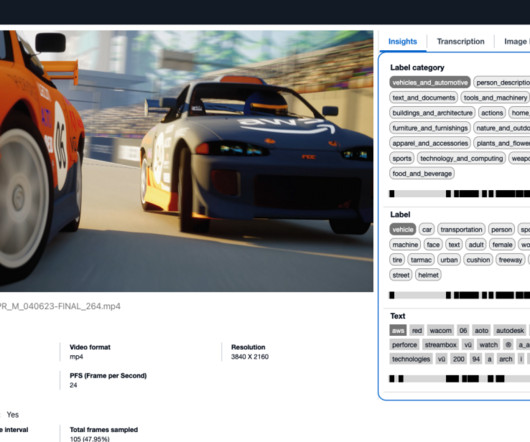
The frontend UI interacts with the extract microservice through a RESTful interface provided by Amazon API Gateway. It offers details of the extracted video information and includes a lightweight analytics UI for dynamic LLM analysis. Detect generic objects and labels using the Amazon Rekognition label detection API.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
































Let's personalize your content