This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this post, we explore how you can use Amazon Bedrock to generate high-quality categorical ground truth data, which is crucial for training machine learning (ML) models in a cost-sensitive environment. This results in an imbalanced class distribution for training and test datasets.
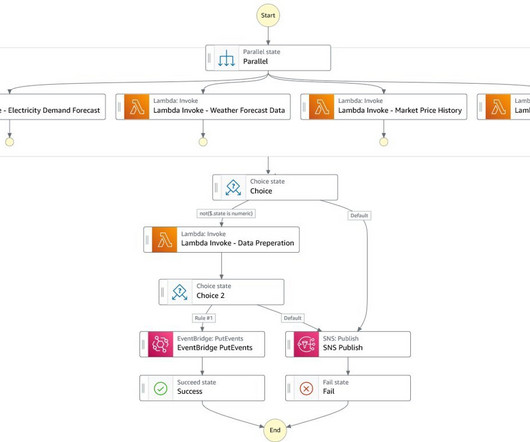
You need trained people and specialized equipment, and you often must shut things down during inspection. Each drone follows predefined routes, with flight waypoints, altitude, and speed configured through an AWS API, using coordinates stored in Amazon DynamoDB. The following diagram outlines how different components interact.
These insights are stored in a central repository, unlocking the ability for analytics teams to have a single view of interactions and use the data to formulate better sales and support strategies. With Lambda integration, we can create a web API with an endpoint to the Lambda function.
It also uses a number of other AWS services such as Amazon API Gateway , AWS Lambda , and Amazon SageMaker. API Gateway is serverless and hence automatically scales with traffic. API Gateway also provides a WebSocket API. Incoming requests to the gateway go through this point.
For their AI training and inference workloads, Adobe uses NVIDIA GPU-accelerated Amazon Elastic Compute Cloud (Amazon EC2) P5en (NVIDIA H200 GPUs), P5 (NVIDIA H100 GPUs), P4de (NVIDIA A100 GPUs), and G5 (NVIDIA A10G GPUs) instances. To train generative AI models at enterprise scale, ServiceNow uses NVIDIA DGX Cloud on AWS.
In this post, we demonstrate how the CQ solution used Amazon Transcribe and other AWS services to improve critical KPIs with AI-powered contact center call auditing and analytics. Additionally, Intact was impressed that Amazon Transcribe could adapt to various post-call analytics use cases across their organization.
Similarly, maintaining detailed information about the datasets used for training and evaluation helps identify potential biases and limitations in the models knowledge base. SageMaker is a data, analytics, and AI/ML platform, which we will use in conjunction with FMEval to streamline the evaluation process.
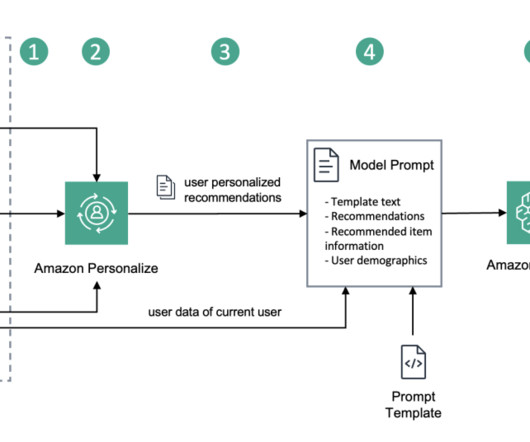
You can get started without any prior machine learning (ML) experience, and Amazon Personalize allows you to use APIs to build sophisticated personalization capabilities. Train an Amazon Personalize Top picks for you recommender. You start by creating your dataset group, loading your data, and then training a recommender.
These sessions, featuring Amazon Q Business , Amazon Q Developer , Amazon Q in QuickSight , and Amazon Q Connect , span the AI/ML, DevOps and Developer Productivity, Analytics, and Business Applications topics. Fourth, we’ll address responsible AI, so you can build generative AI applications with responsible and transparent practices.
To address these issues, we launched a generative artificial intelligence (AI) call summarization feature in Amazon Transcribe Call Analytics. Simply turn the feature on from the Amazon Transcribe console or using the start_call_analytics_job API. You can upload a call recording in Amazon S3 and start a Transcribe Call Analytics job.
In this post, we describe the enhancements to the forecasting capabilities of SageMaker Canvas and guide you on using its user interface (UI) and AutoML APIs for time-series forecasting. While the SageMaker Canvas UI offers a code-free visual interface, the APIs empower developers to interact with these features programmatically.
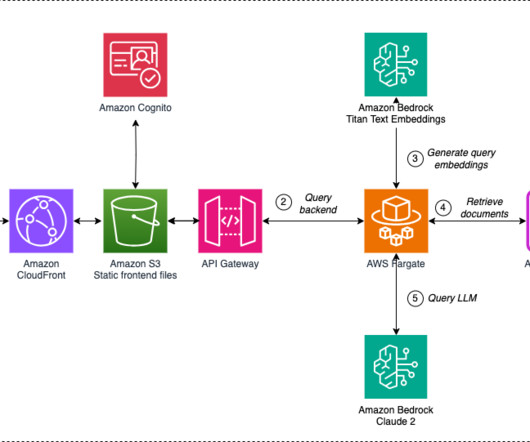
Agent architecture The following diagram illustrates the serverless agent architecture with standard authorization and real-time interaction, and an LLM agent layer using Amazon Bedrock Agents for multi-knowledge base and backend orchestration using API or Python executors. Domain-scoped agents enable code reuse across multiple agents.
While these models are trained on vast amounts of generic data, they often lack the organization-specific context and up-to-date information needed for accurate responses in business settings. The function checks the semantic cache (Amazon Bedrock Knowledge Bases) using the Retrieve API. which is received by the Invoke Agent function.
Increasingly, FMs are completing tasks that were previously solved by supervised learning, which is a subset of machine learning (ML) that involves training algorithms using a labeled dataset. Although we used a pre-trained FM, the problem was formulated as a text classification task.
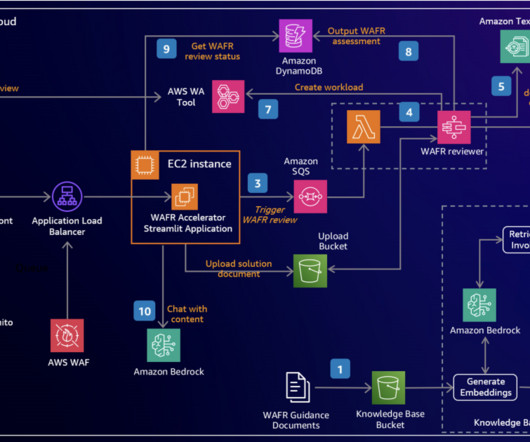
In this post, we review how Aetion is using Amazon Bedrock to help streamline the analytical process toward producing decision-grade real-world evidence and enable users without data science expertise to interact with complex real-world datasets. The following diagram illustrates the solution architecture.
In this blog post and open source project , we show you how you can pre-train a genomics language model, HyenaDNA , using your genomic data in the AWS Cloud. It supports large-scale analysis and collaborative research through HealthOmics storage, analytics, and workflow capabilities.
The Amazon Bedrock single API access, regardless of the models you choose, gives you the flexibility to use different FMs and upgrade to the latest model versions with minimal code changes. Amazon Titan FMs provide customers with a breadth of high-performing image, multimodal, and text model choices, through a fully managed API.
We also look into how to further use the extracted structured information from claims data to get insights using AWS Analytics and visualization services. We highlight on how extracted structured data from IDP can help against fraudulent claims using AWS Analytics services. Amazon Redshift is another service in the Analytics stack.
They provide access to external data and APIs or enable specific actions and computation. To improve accuracy, we tested model fine-tuning, training the model on common queries and context (such as database schemas and their definitions). At RDC, Hendra designs end-to-end analytics solutions within an Agile DevOps framework.
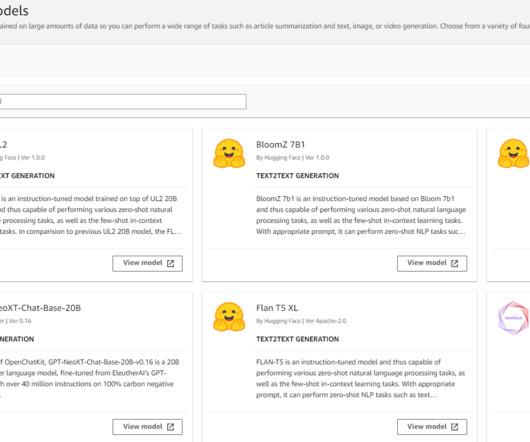
Amazon SageMaker JumpStart is the machine learning (ML) hub of SageMaker that offers over 350 built-in algorithms, pre-trained models, and pre-built solution templates to help you get started with ML fast. Perform the training step to fine-tune the pre-trained model using transfer learning. Create the model. Register the model.
Gen AI offers enormous potential for efficiency, knowledge sharing, and analytical insight in the contact center. There are several ways to work with Gen AI and LLMs, from SaaS applications with embedded Gen AI to custom-built LLMs to applications that bring in Gen AI and LLM capabilities via API. Is it an API model?
Look for a service that has: Encrypted data storage Secure call recording Staff trained in handling PHI (Protected Health Information) Internal audits and compliance reporting 3. Trained Medical Receptionists and Agents Your patients should be speaking with knowledgeable and compassionate representatives.
Key features include: Signed Business Associate Agreement (BAA) Secure data storage Role-based access to patient data Regular staff training on HIPAA policies Ask prospective call center partners: What safeguards are in place to protect patient data? How often do you perform security audits? Do you offer client-specific performance reviews?
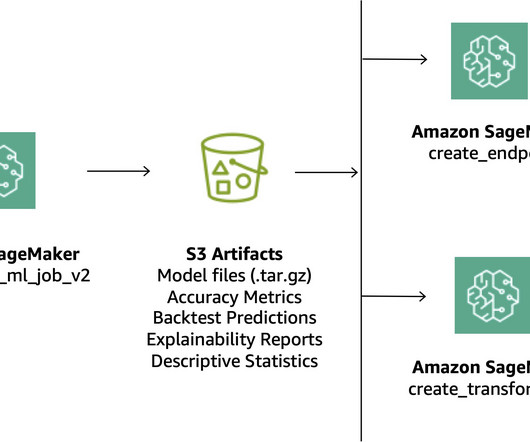
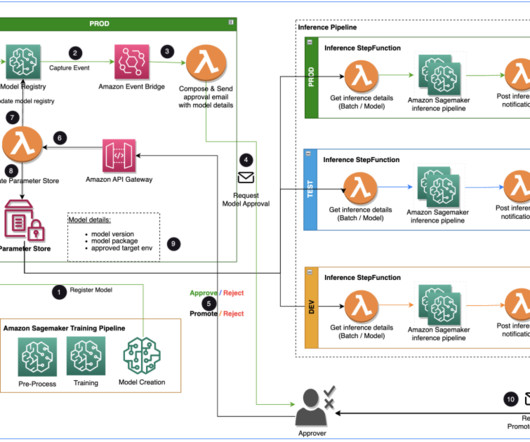
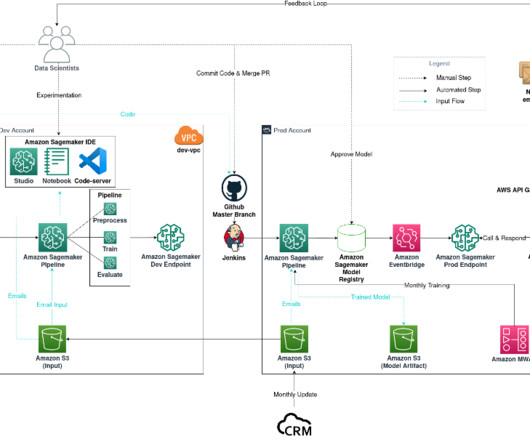
ML Engineer at Tiger Analytics. When a model is trained and ready to be used, it needs to be approved after being registered in the Amazon SageMaker Model Registry. Overview of solution This post focuses on a workflow solution that the ML model development lifecycle can use between the training pipeline and inferencing pipeline.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
In this post, you will learn how Marubeni is optimizing market decisions by using the broad set of AWS analytics and ML services, to build a robust and cost-effective Power Bid Optimization solution. Consolidated and augmented data ready to be used for model training. Data comes from disparate sources in a number of formats.
Your data, such as prompts, completions, custom models, and data used for fine-tuning or continued pre-training, is not used for service improvement and is never shared with third-party model providers. Your data remains in the AWS Region where the API call is processed. All data is encrypted in transit and at rest.
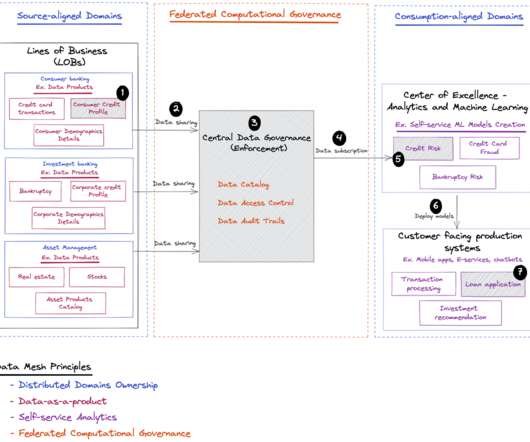
This is the second part of a series that showcases the machine learning (ML) lifecycle with a data mesh design pattern for a large enterprise with multiple lines of business (LOBs) and a Center of Excellence (CoE) for analytics and ML. In this post, we address the analytics and ML platform team as a consumer in the data mesh.
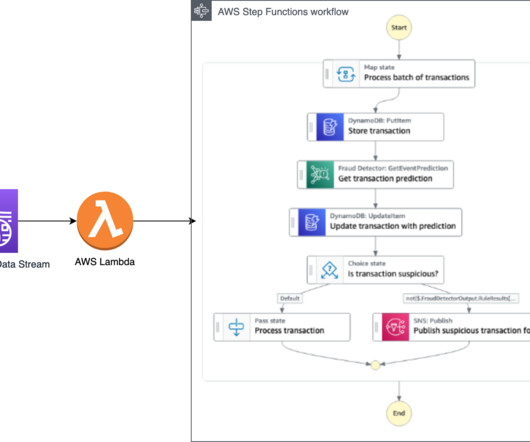
You can also use Amazon SageMaker to train a proprietary fraud detection model. For more information, refer to Train fraudulent payment detection with Amazon SageMaker. Call the Amazon Fraud Detector API using the GetEventPrediction action. The API returns one of the following results: approve, block, or investigate.
Its collaborative capabilities such as real-time coediting and sharing notebooks within the team ensures smooth teamwork, while the scalability and high-performance training caters to large datasets. Each data analytics team is able to request one or multiple SageMaker domains through the company’s internal self-service portal.
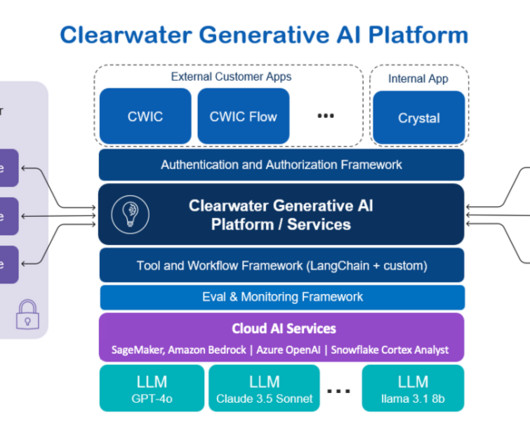
This post was written with Darrel Cherry, Dan Siddall, and Rany ElHousieny of Clearwater Analytics. About Clearwater Analytics Clearwater Analytics (NYSE: CWAN) stands at the forefront of investment management technology. Crystal shares CWICs core functionalities but benefits from broader data sources and API access.
Large enterprises sometimes set up a center of excellence (CoE) to tackle the needs of different lines of business (LoBs) with innovative analytics and ML projects. To generate high-quality and performant ML models at scale, they need to do the following: Provide an easy way to access relevant data to their analytics and ML CoE.
To mitigate these challenges, we propose using an open-source federated learning (FL) framework called FedML , which enables you to analyze sensitive HCLS data by training a global machine learning model from distributed data held locally at different sites. Therefore, it brings analytics to data, rather than moving data to analytics.
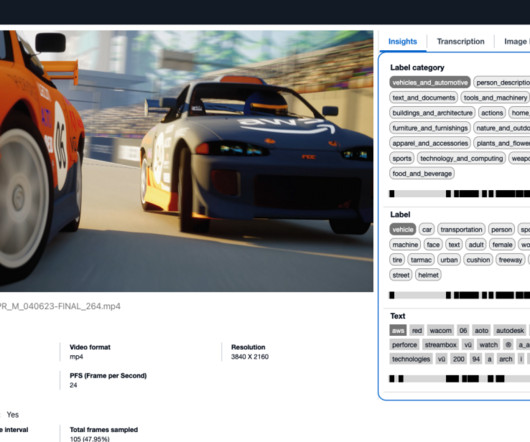
Educational tech companies manage large inventories of training videos. The frontend UI interacts with the extract microservice through a RESTful interface provided by Amazon API Gateway. It offers details of the extracted video information and includes a lightweight analytics UI for dynamic LLM analysis.
From trying to keep up with HR on training, to supporting operations with retention needs, and more, there’s often little time left to talk to IT about the features you need in your next WFM platform. If your platform produces amazing forecasts but no aligned schedules, then you likely have a data analytics platform and not a WFM platform.
The solution focuses on the fundamental principles of developing an AI/ML application workflow of data preparation, model training, model evaluation, and model monitoring. It is already trained on tens of millions of images across many categories. API Gateway calls the Lambda function to obtain the pet attributes.
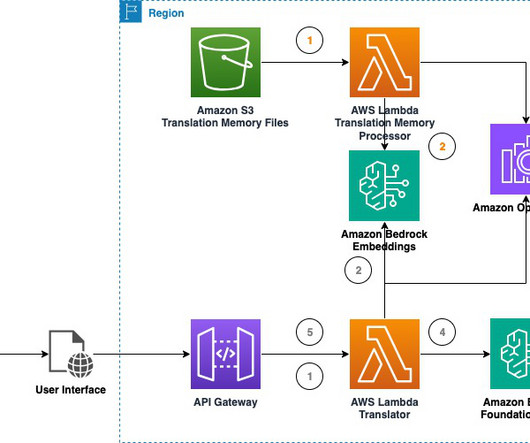
By incorporating these human translations into the LLMs training or inference process, the LLM can learn from and reuse these high-quality translations, potentially improving its overall performance. Amazon Titan Text Embeddings V2 includes multilingual support for over 100 languages in pre-training.
It made it easy to deploy and manage a pre-trained instance of Flan, offering us a solid foundation for our application. In the architecture shown in the following diagram, users input text in the React -based web app, which triggers Amazon API Gateway , which in turn invokes an AWS Lambda function depending on the bias in the user text.
ZOE is a multi-agent LLM application that integrates with multiple data sources to provide a unified view of the customer, simplify analytics queries, and facilitate marketing campaign creation. It simplifies feature access for model training and inference, significantly reducing the time and complexity involved in managing data pipelines.
Frontier large language models (LLMs) like Anthropic Claude on Amazon Bedrock are trained on vast amounts of data, allowing Anthropic Claude to understand and generate human-like text. Solution overview Fine-tuning is a technique in natural language processing (NLP) where a pre-trained language model is customized for a specific task.
In this post, we demonstrate the technical benefits of using Hugging Face transformers deployed with Amazon SageMaker , such as training and experimentation at scale, and increased productivity and cost-efficiency. This merge event now triggers a SageMaker Pipelines job using production data for training purposes.
It’s a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like Anthropic, Cohere, Meta, Mistral AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
Agents for Bedrock are a game changer, allowing LLMs to complete complex tasks based on your own data and APIs, privately, securely, with setup in minutes (no training or fine tuning required). Amazon Bedrock is the first fully managed generative AI service to offer Llama 2, Meta’s next-generation LLM, through a managed API.
This is a guest post co-written with Vicente Cruz Mínguez, Head of Data and Advanced Analytics at Cepsa Química, and Marcos Fernández Díaz, Senior Data Scientist at Keepler. However, their knowledge is static and tied to the data used during the pre-training phase.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content