This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Predictive Analytics takes this a step further by analyzing bigdata to anticipate customer needs, streamline workflows, and deliver personalized responses. These measures ensure customer data is protected, building trust and maintaining the integrity of customer relationships.
Harnessing the power of bigdata has become increasingly critical for businesses looking to gain a competitive edge. However, managing the complex infrastructure required for bigdata workloads has traditionally been a significant challenge, often requiring specialized expertise. latest USER root RUN dnf install python3.11
In Part 1 of this series, we discussed intelligent document processing (IDP), and how IDP can accelerate claims processing use cases in the insurance industry. We discussed how we can use AWS AI services to accurately categorize claims documents along with supporting documents. Part 1: Classification and extraction of documents.
Site monitors conduct on-site visits, interview personnel, and verify documentation to assess adherence to protocols and regulatory requirements. However, this process can be time-consuming and prone to errors, particularly when dealing with extensive audio recordings and voluminous documentation.
A recent Calabrio research study of more than 1,000 C-Suite executives has revealed leaders are missing a key data stream – voice of the customer data. Download the report to learn how executives can find and use VoC data to make more informed business decisions.
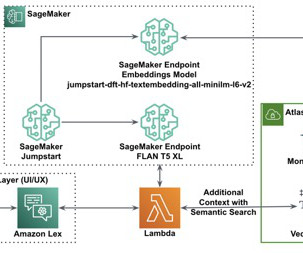
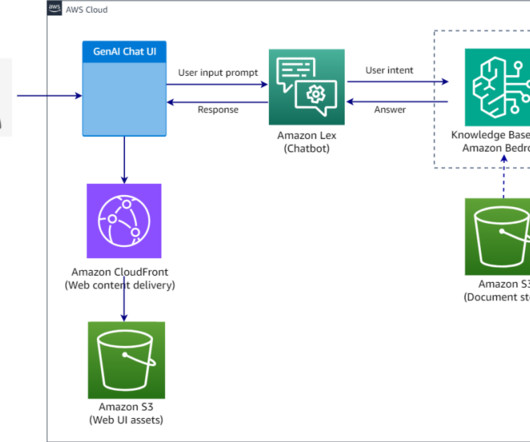
The agent knowledge base stores Amazon Bedrock service documentation, while the cache knowledge base contains curated and verified question-answer pairs. For this example, you will ingest Amazon Bedrock documentation in the form of the User Guide PDF into the Amazon Bedrock knowledge base. This will be the primary dataset.
Amazon’s intelligent document processing (IDP) helps you speed up your business decision cycles and reduce costs. Across multiple industries, customers need to process millions of documents per year in the course of their business. The following figure shows the stages that are typically part of an IDP workflow.
Refer to the Python documentation for an example. About the Authors Bruno Klein is a Senior Machine Learning Engineer with AWS Professional Services Analytics Practice. He helps customers implement bigdata and analytics solutions. He helps customers implement bigdata, machine learning, and analytics solutions.
For instance, to improve key call center metrics such as first call resolution , business analysts may recommend implementing speech analytics solutions to improve agent performance management. Successful call centers use analytics to help aid, streamline and maximize customer service and sales needs…”. AmraBeganovich. Kirk Chewning.
The healthcare industry generates and collects a significant amount of unstructured textual data, including clinical documentation such as patient information, medical history, and test results, as well as non-clinical documentation like administrative records. Data Architect, Data Lake at AWS.
Generative AI models have the potential to revolutionize enterprise operations, but businesses must carefully consider how to harness their power while overcoming challenges such as safeguarding data and ensuring the quality of AI-generated content.
Organizations are similarly challenged by the overflow of BigData from transactions, social media, records, interactions, documents, and sensors. But the ability to correlate and link all of this data, and derive meaningful insights, can offer a great opportunity.
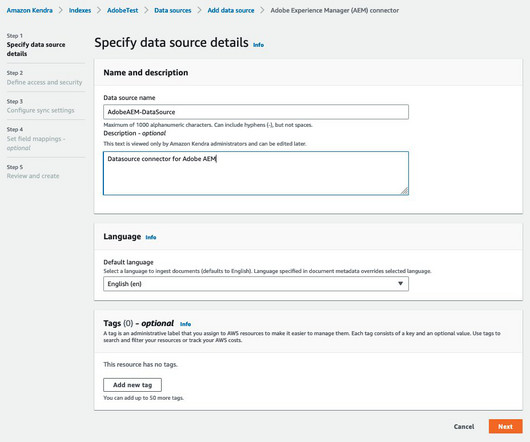
The connector also ingests the access control list (ACL) information for each document. Solution overview In our solution, we configure AEM as a data source for an Amazon Kendra search index using the Amazon Kendra AEM connector. The connector also indexes the Access Control List (ACL) information for each message and document.
Keep the data source location as the same AWS account and choose Browse S3. Select the S3 bucket where you uploaded the Amazon shareholder documents and choose Choose. Select the embedding model to vectorize the documents. Choose Sync to index the documents. Choose Next. Choose Create bot.
Use group sharing engines to share documents with strategies and knowledge across departments. Data can be insightful to all of the roles HR takes on in facilitating the company’s CX goals. 60% of companies are now investing in bigdata and analytics to make HR more data driven. —@tcrawford.
View this document on the publisher’s website. Advancements in artificial intelligence (AI), machine learning, BigDataanalytics, and mobility are all driving contact center innovation. Speech analytics. Customer journey analytics. These 8 Technologies Are Transforming the Contact Center. August 2017.
Machine learning (ML) can help companies make better business decisions through advanced analytics. With faster model training times, you can focus on understanding your data and analyzing the impact of the data, and achieve effective business outcomes. About the Authors Ajjay Govindaram is a Senior Solutions Architect at AWS.
An agile approach brings the full power of bigdataanalytics to bear on customer success. An agile approach to CS management can be broken down into seven steps: Document your client’s requirements. Document Your Client’s Requirements. Standardize your documentation approach by developing a requirements template.
Knowledge Bases for Amazon Bedrock automates synchronization of your data with your vector store, including diffing the data when it’s updated, document loading, and chunking, as well as semantic embedding. RAG is a popular technique that combines the use of private data with large language models (LLMs). txt) Markdown (.md)
Amazon Q returns the response as a JSON object (detailed in the Amazon Q documentation ). sourceAttributions – The source documents used to generate the conversation response. In Retrieval Augmentation Generation (RAG), this always refers to one or more documents from enterprise knowledge bases that are indexed in Amazon Q.
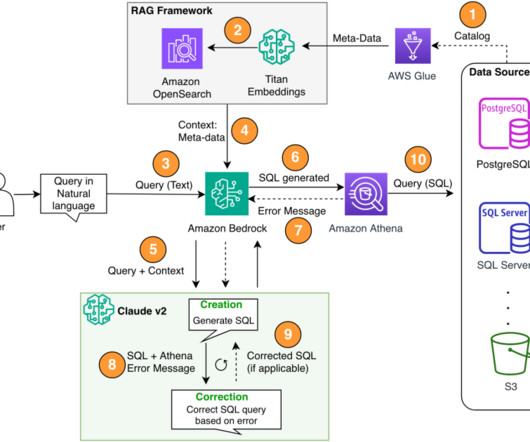
The solution in this post aims to bring enterprise analytics operations to the next level by shortening the path to your data using natural language. Second, you might need to build text-to-SQL features for every database because data is often not stored in a single target. We use Anthropic Claude v2.1
Using Interaction Analytics to Improve the Customer Journey (whitepaper). Sharing speech and text findings with a customer journey analytics (CJA) solution is a great way to expand the benefits and contributions of Interaction Analytics. By Donna Fluss. Introduction. First Name * Last Name Title Company Phone Email Address *.
Imagine the possibilities: Quick and efficient brainstorming sessions, real-time ideation, and even drafting documents or code snippets—all powered by the latest advancements in AI. About the Authors Rushabh Lokhande is a Senior Data & ML Engineer with AWS Professional Services Analytics Practice.
Reality Check: Will Customer Journey Analytics Be the Next CRM? View this document on the publisher’s website. The up-and-comer is customer journey analytics, or CJA, and it’s in the ring with the incumbent, CRM. By Donna Fluss. CJA’S Role in the Market. CJA is Compelling, But Can it Succeed?
We live in an era of bigdata, AI, and automation, and the trends that matter in CX this year begin with the abilities – and pain points – ushered in by this technology. For example, bigdata makes things like hyper-personalized customer service possible, but it also puts enormous stress on data security.
Whether via social media, websites, or online communities, companies can gather a massive amount of digital data on their customers. Companies can then use AI-driven predictive analytics tools to determine customer patterns or trends in order to better target their marketing offers, and enhance their relationship with customers.
Whether via social media, websites, or online communities, companies can gather a massive amount of digital data on their customers. Companies can then use AI-driven predictive analytics tools to determine customer patterns or trends in order to better target their marketing offers, and enhance their relationship with customers.
In other words, the link between data and customer experience can become a virtuous circle. This article focuses on the crucial role of customer dataanalytics in contact center performance and customer experience. Table of Contents show What is Customer dataanalytics?
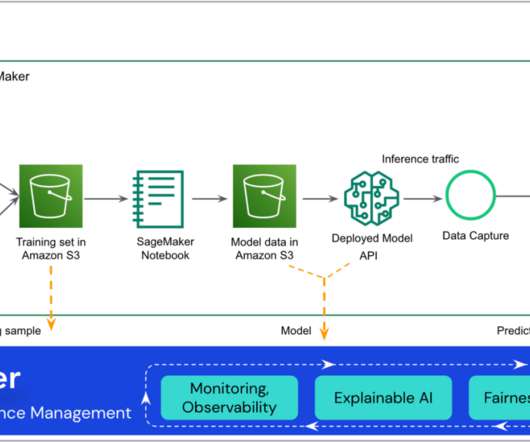
Through model monitoring, model explainability, analytics, and bias detection, Fiddler provides your company with an easy-to-use single pane of glass to ensure your models are behaving as they should. To simplify this further, the code for this Lambda function is publicly available from Fiddler’s documentation site. You’ve done it!
Snowflake is a cloud data platform that provides data solutions for data warehousing to data science. Snowflake is an AWS Partner with multiple AWS accreditations, including AWS competencies in machine learning (ML), retail, and data and analytics. Bosco Albuquerque is a Sr. Matt Marzillo is a Sr.
Most real-world data exists in unstructured formats like PDFs, which requires preprocessing before it can be used effectively. According to IDC , unstructured data accounts for over 80% of all business data today. This includes formats like emails, PDFs, scanned documents, images, audio, video, and more.
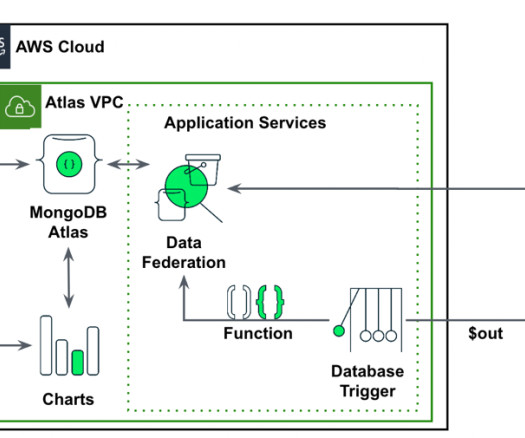
In this post, we will explore the potential of using MongoDB’s time series data and SageMaker Canvas as a comprehensive solution. MongoDB Atlas MongoDB Atlas is a fully managed developer data platform that simplifies the deployment and scaling of MongoDB databases in the cloud.
Companies use advanced technologies like AI, machine learning, and bigdata to anticipate customer needs, optimize operations, and deliver customized experiences. Objective Data conversion for storage and retrieval. Scope Limited to data and documents. Efficiency and automation of existing workflows.
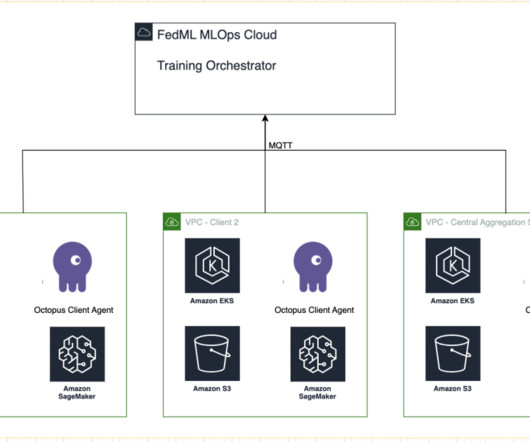
Create an MLOps deployment package As a part of the FedML documentation, we need to create the client and server packages, which the MLOps platform will distribute to the server and clients to begin training. He entered the bigdata space in 2013 and continues to explore that area.
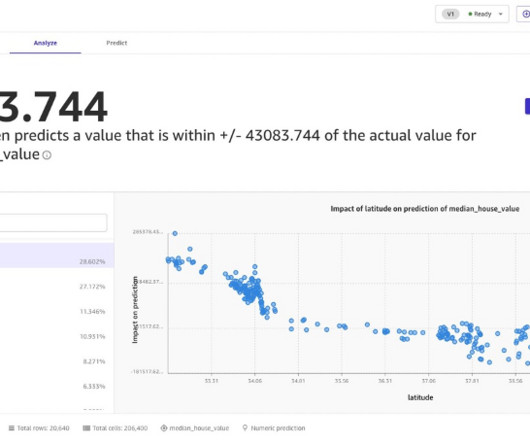
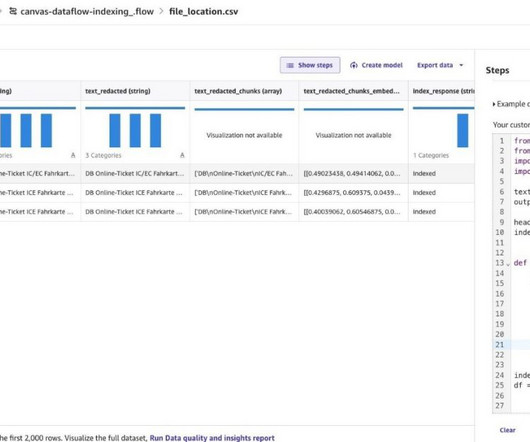
For the dataset in this use case, you should expect a “Very low quick-model score” high priority warning, and very low model efficacy on minority classes (charged off and current), indicating the need to clean up and balance the data. Refer to Canvas documentation to learn more about the data insights report.
Its intelligent knowledge base/self-service platform is powered by artificial intelligence, unified search, rich analytics, and machine learning. TechSee’s technology combines AI with deep machine learning, proprietary algorithms, and BigData to deliver a scalable cognitive system that becomes smarter with every customer support interaction.
This is a story about finding the hidden gems in your customer interaction data. And the good news is you don’t need “BigData” to find them. In the age of bigdata, insights around workflow processes and creating better documentation can be lost. A great place to start is speech analytics.
Amazon Kendra supports a variety of document formats , such as Microsoft Word, PDF, and text from various data sources. In this post, we focus on extending the document support in Amazon Kendra to make images searchable by their displayed content. This means you can manipulate and ingest your data as needed.
Real-time payments have well-documented advantages for both banks and customers, plus this type of technology is already a standard in many financial institutions. . Improving Products and Services Through BigData. In the past, the biggest challenge wasn’t the collection, but the analysis and interpretation of this data.
For example, generative AI models can draw from documents to walk customers through various processes or troubleshoot potential issues to transform help desk capabilities. AI-enabled agent assist technology leverages dataanalytics and bigdata to feed agents with relevant profile information and historical interaction data in real-time.
Customers can also access offline store data using a Spark runtime and perform bigdata processing for ML feature analysis and feature engineering use cases. Table formats provide a way to abstract data files as a table. Apache Iceberg is an open table format for very large analytic datasets.
Gone went giant, word-packed binders of documents, and the faceless training, and mindless programming. Using BigData to Make Leadership Advances in the Workplace. While surveys that lead to these results are historically what we’ve had to understand engagement metrics, analytics are far more important.
Ask any contact center leader for data and you’ll likely end up with a hefty pile of metrics and analytics. Most companies can pull up copious documents, spreadsheets and reports with endless data and analytics. But too often, that data just sits there, gathering digital dust.
For detailed instructions on how to use the DGL-KE, refer to Training knowledge graph embeddings at scale with the Deep Graph Library and DGL-KE Documentation. Mutisya has a strong quantitative and analytical background with over a decade of experience in artificial intelligence, machine learning and bigdataanalytics.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content