This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Using its enterprise software, FloTorch conducted an extensive comparison between Amazon Nova models and OpenAIs GPT-4o models with the Comprehensive Retrieval Augmented Generation (CRAG) benchmark dataset. FloTorch used these queries and their ground truth answers to create a subset benchmark dataset.
Overview of Pixtral 12B Pixtral 12B, Mistrals inaugural VLM, delivers robust performance across a range of benchmarks, surpassing other open models and rivaling larger counterparts, according to Mistrals evaluation. Performance metrics and benchmarks Pixtral 12B is trained to understand both natural images and documents, achieving 52.5%
adds new APIs to customize GraphStorm pipelines: you now only need 12 lines of code to implement a custom node classification training loop. Based on customer feedback for the experimental APIs we released in GraphStorm 0.2, introduces refactored graph ML pipeline APIs. Specifically, GraphStorm 0.3 In addition, GraphStorm 0.3
This post explores these relationships via a comprehensive benchmarking of LLMs available in Amazon SageMaker JumpStart, including Llama 2, Falcon, and Mistral variants. We provide theoretical principles on how accelerator specifications impact LLM benchmarking. Additionally, models are fully sharded on the supported instance.
Consider benchmarking your user experience to find the best latency for your use case, considering that most humans cant read faster than 225 words per minute and therefore extremely fast response can hinder user experience. In such scenarios, you want to optimize for TTFT. Users prefer accurate responses over quick but less reliable ones.
Amazon Bedrock , a fully managed service offering high-performing foundation models from leading AI companies through a single API, has recently introduced two significant evaluation capabilities: LLM-as-a-judge under Amazon Bedrock Model Evaluation and RAG evaluation for Amazon Bedrock Knowledge Bases. 0]}-{evaluator_model.split('.')[0]}-{datetime.now().strftime('%Y-%m-%d-%H-%M-%S')}"
Performance metrics and benchmarks According to Mistral, the instruction-tuned version of the model achieves over 81% accuracy on Massive Multitask Language Understanding (MMLU) with 150 tokens per second latency, making it currently the most efficient model in its category. It doesnt support Converse APIs or other Amazon Bedrock tooling.
Amazon Bedrock is a fully managed service that offers a choice of high-performing Foundation Models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon via a single API, along with a broad set of capabilities you need to build generative AI applications with security, privacy, and responsible AI.
Amazon Bedrock is a fully managed service that makes FMs from leading AI startups and Amazon available through an API, so you can choose from a wide range of FMs to find the model that is best suited for your use case. Solution overview The solution comprises two main steps: Generate synthetic data using the Amazon Bedrock InvokeModel API.
An alternative approach to routing is to use the native tool use capability (also known as function calling) available within the Bedrock Converse API. In this scenario, each category or data source would be defined as a ‘tool’ within the API, enabling the model to select and use these tools as needed.
A common way to select an embedding model (or any model) is to look at public benchmarks; an accepted benchmark for measuring embedding quality is the MTEB leaderboard. The Massive Text Embedding Benchmark (MTEB) evaluates text embedding models across a wide range of tasks and datasets.
Amazon Bedrock is a fully managed service that makes foundation models (FMs) from leading AI startups and Amazon available through an API, so you can choose from a wide range of FMs to find the model that is best suited for your use case. Lastly, the Lambda function stores the question list in Amazon S3.
You can see that for the 45 models we benchmarked, there is a 1.35x latency improvement (geomean for the 45 models). You can see that for the 33 models we benchmarked, there is around 2x performance improvement (geomean for the 33 models). We benchmarked 45 models using the scripts from the TorchBench repo.
They enable applications requiring very low latency or local data processing using familiar APIs and tool sets. Through comparative benchmarking tests, we illustrate how deploying FMs in Local Zones closer to end users can significantly reduce latencya critical factor for real-time applications such as conversational AI assistants.
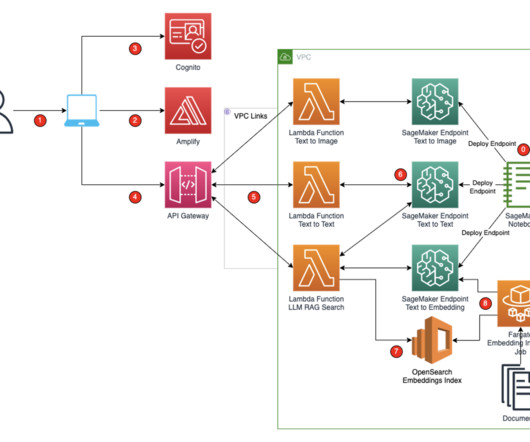
These SageMaker endpoints are consumed in the Amplify React application through Amazon API Gateway and AWS Lambda functions. To protect the application and APIs from inadvertent access, Amazon Cognito is integrated into Amplify React, API Gateway, and Lambda functions. You access the React application from your computer.
Acting as a model hub, JumpStart provided a large selection of foundation models and the team quickly ran their benchmarks on candidate models. Regarding the inference, customers using Amazon Ads now have a new API to receive these generated images. The Amazon API Gateway receives the PUT request (step 1).
Automated API testing stands as a cornerstone in the modern software development cycle, ensuring that applications perform consistently and accurately across diverse systems and technologies. Continuous learning and adaptation are essential, as the landscape of API technology is ever-evolving.
SageMaker makes it easy to deploy models into production directly through API calls to the service. It’s a low-level API available for Java, C++, Go, JavaScript, Node.js, PHP, Ruby, and Python. It’s a low-level API available for Java, C++, Go, JavaScript, Node.js, PHP, Ruby, and Python.
Although you can integrate the model directly into an application, the approach that works well for production-grade applications is to deploy the model behind an endpoint and then invoke the endpoint via a RESTful API call to obtain the inference. However, you can use any other benchmarking tool. large two-core machine.
For more information about Jamba-Instruct, including relevant benchmarks, refer to Built for the Enterprise: Introducing AI21’s Jamba-Instruct Model. Programmatic access You can also access Jamba-Instruct through an API, using Amazon Bedrock and AWS SDK for Python (Boto3).
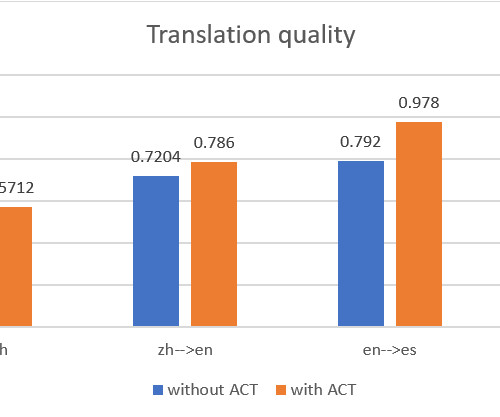
We demonstrate how to use the AWS Management Console and Amazon Translate public API to deliver automatic machine batch translation, and analyze the translations between two language pairs: English and Chinese, and English and Spanish. In this post, we present a solution that D2L.ai
In addition, deployments are now as simple as calling Boto3 SageMaker APIs and attaching the proper auto scaling policies. We already had an API layer on top of our models for model management and inference. In keeping with the instance types we were already using, we did our benchmarking with ml.g4dn.xlarge and ml.g4dn.2xlarge
How to add your competitors’ public reviews to the mix, so you can get a reliable benchmark and win in the market. Lumoa has very clear open APIs and based on your goals, integrations can serve various purposes. How to identify key pain points that you can immediately tackle to increase the score.
With such a rise in popularity of mobile usage around the world, we are delighted to announce that from February 2020, our customers will be able to test the sending of an SMS message to a destination specified by them, via the Spearline API. Access real-time reporting and analytics via Spearline API polling.
Use APIs and middleware to bridge gaps between CPQ and existing enterprise systems, ensuring smooth data flow. Automate Price Calculations and Adjustments Utilize real-time pricing engines within CPQ to dynamically calculate prices based on market trends, cost fluctuations, and competitor benchmarks.
An advanced job is a custom load test job that allows you to perform extensive benchmarks based on your ML application SLA requirements, such as latency, concurrency, and traffic pattern. Inference Recommender uses this information to run a performance benchmark load test. Running Advanced job. sm_client = boto3.client("sagemaker",
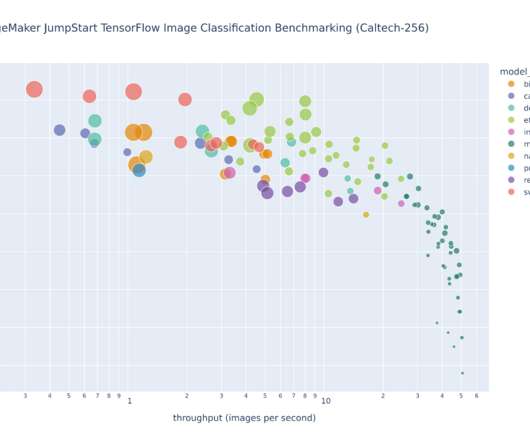
The former question addresses model selection across model architectures, while the latter question concerns benchmarking trained models against a test dataset. This post provides details on how to implement large-scale Amazon SageMaker benchmarking and model selection tasks. swin-large-patch4-window7-224 195.4M efficientnet-b5 29.0M
Jina Embeddings v2 is the preferred choice for experienced ML scientists for the following reasons: State-of-the-art performance – We have shown on various text embedding benchmarks that Jina Embeddings v2 models excel on tasks such as classification, reranking, summarization, and retrieval.
Red-teaming engages human testers to probe an AI system for flaws in an adversarial style, and complements our other testing techniques, which include automated benchmarking against publicly available and proprietary datasets, human evaluation of completions against proprietary datasets, and more.
On Hugging Face, the Massive Text Embedding Benchmark (MTEB) is provided as a leaderboard for diverse text embedding tasks. It currently provides 129 benchmarking datasets across 8 different tasks on 113 languages. medium instance to demonstrate deploying the model as an API endpoint using an SDK through SageMaker JumpStart.
For example, you can immediately start detecting entities such as people, places, commercial items, dates, and quantities via the Amazon Comprehend console , AWS Command Line Interface , or Amazon Comprehend APIs. In this post, we walk you through the benchmarking process and the results we obtained while working on subsampled datasets.
To get started, follow Modify a PyTorch Training Script to adapt SMPs’ APIs in your training script. You can follow the comments in the script and API document to learn more about where SMP APIs are used. Benchmarking performance. We benchmarked sharded data parallelism in the SMP library on both 16 and 32 p4d.24xlarge
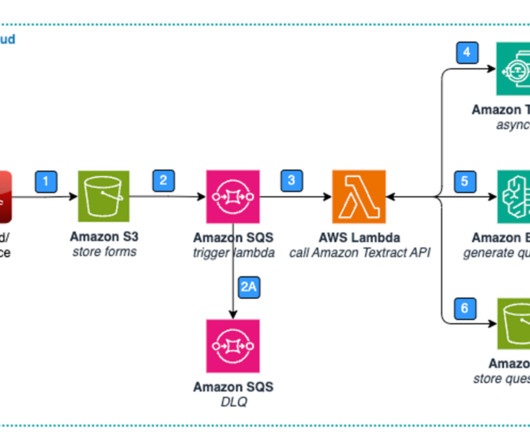
You can save time, money, and labor by implementing classifications in your workflow, and documents go to downstream applications and APIs based on document type. This helps you avoid throttling limits on API calls due to polling the Get* APIs.
Examples of tools you can use to advance sustainability initiatives are: Amazon Bedrock – a fully managed service that provides access to high-performing FMs from leading AI companies through a single API, enabling you to choose the right model for your sustainability use cases.
This is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading artificial intelligence (AI) companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon through a single API. It’s serverless, so you don’t have to manage any infrastructure.
Finally, we’ll benchmark performance of 13B, 50B, and 100B parameter auto-regressive models and wrap up with future work. For training a different model type, you can follow the API document to learn about how to apply SMP APIs. Benchmarking performance. Finally, we benchmark SMP with both of the latest features enabled.
We first benchmark the performance of our model on a single instance to identify the TPS it can handle per our acceptable latency requirements. For example, if you client is making the InvokeEndpoint API call over the internet, from the client’s perspective, the end-to-end latency would be internet + ModelLatency + OverheadLatency.
It’s important for all departments to have benchmarks for success that can be easily measured and tracked. Call center and customer service teams have a variety of KPIs to choose from, but as each company and support department is different, their benchmarks will vary. He leads product management for Nexmo, the Vonage API Platform.
And testingRTC offers multiple ways to export these metrics, from direct collection from webhooks, to downloading results in CSV format using the REST API. You can schedule, customize, and analyze client and server side benchmarks at your own pace and in a manner that suits your deployment needs. Happy days!
When ML models deployed on instances receive API calls from a large number of clients, a random distribution of requests can work very well when there is not a lot of variability in your requests and responses. The endpoint uniformly distributes incoming requests to ML instances using a round-robin algorithm.
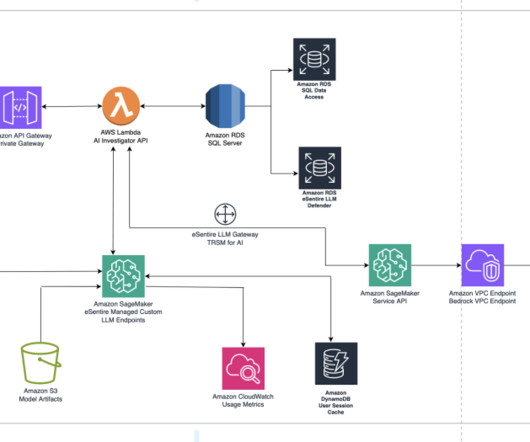
The application’s frontend is accessible through Amazon API Gateway , using both edge and private gateways. Amazon Bedrock offers a practical environment for benchmarking and a cost-effective solution for managing workloads due to its serverless operation. The following diagram visualizes the architecture diagram and workflow.
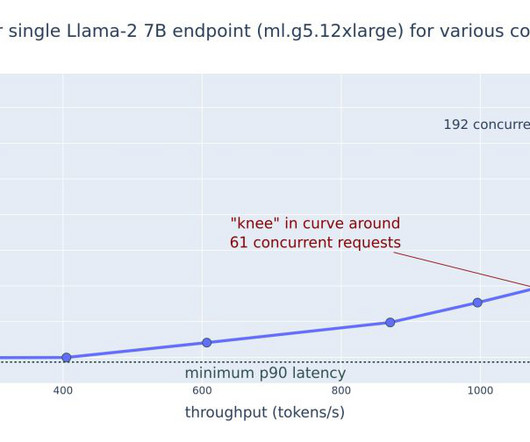
Now, let’s look at latency and throughput performance benchmarking for model serving with the default JumpStart deployment configuration. For more information on how to consider this information and adjust deployment configurations for your specific use case, see Benchmark and optimize endpoint deployment in Amazon SageMaker JumpStart.
Similar to the process of PyTorch integration with C++ code, Neuron CustomOps requires a C++ implementation of an operator via a NeuronCore-ported subset of the Torch C++ API. Finally, the custom library is built by calling the load API. For more information, refer to Custom Operators API Reference Guide [Experimental].
Data and time API. Rest API Testing (Automation) from Scratch-Rest Assured Java. With the Rest API Testing (Automation) from Scratch-Rest Assured Java, you will learn how to design and implement structured API automation, and also generate excellent client reports for API test execution results. . JVM internals.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content