This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
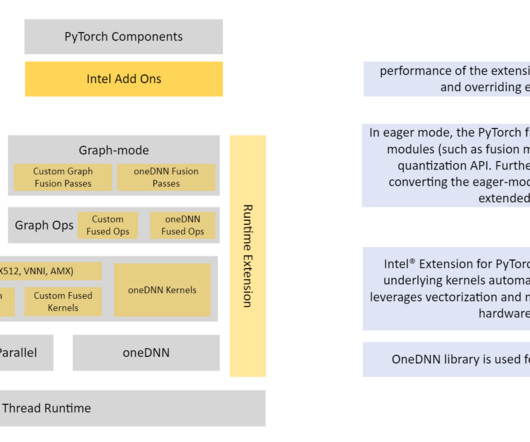
Refer to the appendix for instance details and benchmark data. Import intel extensions for PyTorch to help with quantization and optimization and import torch for array manipulations: import intel_extension_for_pytorch as ipex import torch Apply model calibration for 100 iterations. times greater with INT8 quantization.
In this post, we explore the latest features introduced in this release, examine performance benchmarks, and provide a detailed guide on deploying new LLMs with LMI DLCs at high performance. Be mindful that LLM token probabilities are generally overconfident without calibration.
We explored nearest neighbors, decision trees, neural networks, and also collaborative filtering in terms of algorithms, while trying different sampling strategies (filtering, random, stratified, and time-based sampling) and evaluated performance on Area Under the Curve (AUC) and calibration distribution along with Brier score loss.
Response times across digital channels require different benchmarks: Live chat : 30 seconds or less Email : Under 4 hours Social media : Within 60 minutes Agent performance metrics should balance efficiency with quality. Scorecards combining AHT, FCR, and customer satisfaction create well-rounded performance measurement.
Each trained model needs to be benchmarked against many tasks not only to assess its performances but also to compare it with other existing models, to identify areas that needs improvements and finally, to keep track of advancements in the field. Evaluating these models allows continuous model improvement, calibration and debugging.
Dataset The dataset for this post is manually distilled from the Amazon Science evaluation benchmark dataset called TofuEval. LLM debates need to be calibrated and aligned with human preference for the task and dataset. For this post, 10 meeting transcripts have been curated from the MediaSum repository inside the TofuEval dataset.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














Let's personalize your content