This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
adds new APIs to customize GraphStorm pipelines: you now only need 12 lines of code to implement a custom node classification training loop. Based on customer feedback for the experimental APIs we released in GraphStorm 0.2, introduces refactored graph ML pipeline APIs. Specifically, GraphStorm 0.3 In addition, GraphStorm 0.3
Overview of Pixtral 12B Pixtral 12B, Mistrals inaugural VLM, delivers robust performance across a range of benchmarks, surpassing other open models and rivaling larger counterparts, according to Mistrals evaluation. Performance metrics and benchmarks Pixtral 12B is trained to understand both natural images and documents, achieving 52.5%
These include metrics such as ROUGE or cosine similarity for text similarity, and specific benchmarks for assessing toxicity (Detoxify), prompt stereotyping (cross-entropy loss), or factual knowledge (HELM, LAMA). Refer to Getting started with the API to set up your environment to make Amazon Bedrock requests through the AWS API.
An alternative approach to routing is to use the native tool use capability (also known as function calling) available within the Bedrock Converse API. In this scenario, each category or data source would be defined as a ‘tool’ within the API, enabling the model to select and use these tools as needed.
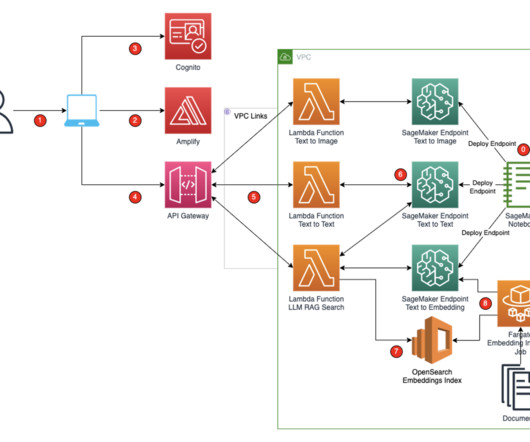
These SageMaker endpoints are consumed in the Amplify React application through Amazon API Gateway and AWS Lambda functions. To protect the application and APIs from inadvertent access, Amazon Cognito is integrated into Amplify React, API Gateway, and Lambda functions. You access the React application from your computer.
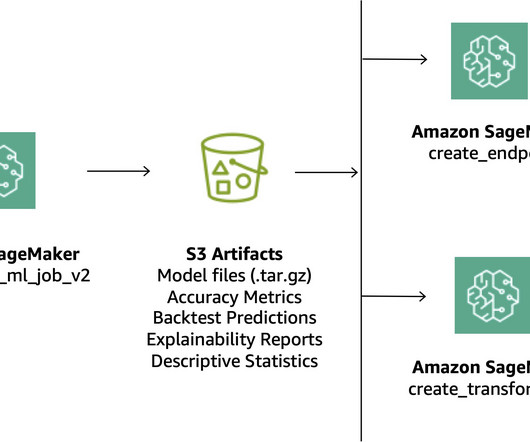
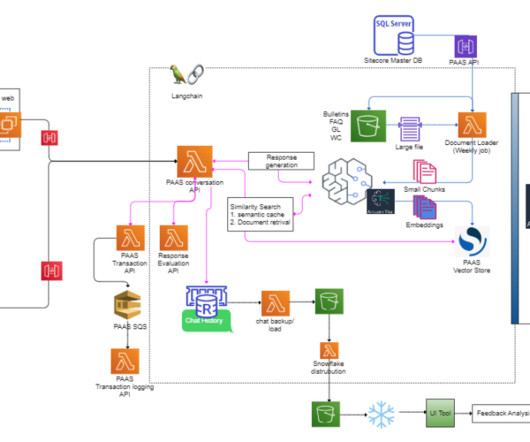
The application’s frontend is accessible through Amazon API Gateway , using both edge and private gateways. When a SageMaker endpoint is constructed, an S3 URI to the bucket containing the model artifact and Docker image is shared using Amazon ECR. The following diagram visualizes the architecture diagram and workflow.
Jina Embeddings v2 is the preferred choice for experienced ML scientists for the following reasons: State-of-the-art performance – We have shown on various text embedding benchmarks that Jina Embeddings v2 models excel on tasks such as classification, reranking, summarization, and retrieval.
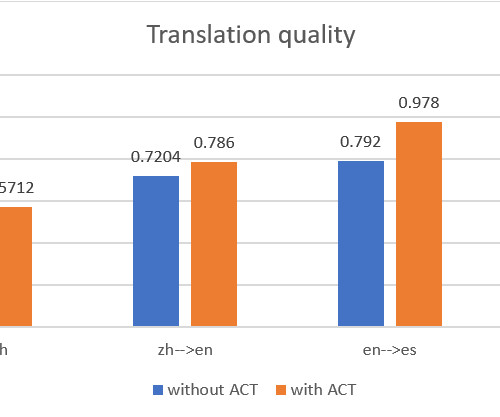
We demonstrate how to use the AWS Management Console and Amazon Translate public API to deliver automatic machine batch translation, and analyze the translations between two language pairs: English and Chinese, and English and Spanish. In this post, we present a solution that D2L.ai
The pre-trained GNN embeddings show a 24% improvement on a shopper activity prediction task over a state-of-the-art BERT- based baseline; it also exceeds benchmark performance in other ads applications.” Basically, by using the API of this layer, you can focus on the model development without worrying about how to scale the model training.
On Hugging Face, the Massive Text Embedding Benchmark (MTEB) is provided as a leaderboard for diverse text embedding tasks. It currently provides 129 benchmarking datasets across 8 different tasks on 113 languages. medium instance to demonstrate deploying the model as an API endpoint using an SDK through SageMaker JumpStart.
You will learn the best practices and coding conventions for writing Java code, and how to program using Java 8 constructs like Lambdas and Streams. Data and time API. Rest API Testing (Automation) from Scratch-Rest Assured Java. Main topics: Rest API basics and terminology. API testing using Postman. Input-output.
One morning, he received an urgent request from a large construction firm that needed a specialized generator setup for a multi-site project. 4- Improving Deal Closure Rates with Real-Time Insights CPQ provides real-time analytics on customer preferences, pricing trends, and competitor benchmarks.
We compile the UNet for one batch (by using input tensors with one batch), then use the torch_neuronx.DataParallel API to load this single batch model onto each core. The directory path for the compiled model is constructed by joining COMPILER_WORKDIR_ROOT with the subdirectory text_encoder : emb = torch.tensor([.])
Customers have to leave their development environment to use academic tools and benchmarking sites, which require highly-specialized knowledge. We surveyed existing open-source evaluation frameworks and designed FMEval evaluation API with extensibility in mind.
A recent initiative is to simplify the difficulty of constructing search expressions by autofilling patent search queries using state-of-the-art text generation models. In this section, we show how to build your own container, deploy your own GPT-2 model, and test with the SageMaker endpoint API. model_fp16.onnx gpt2 and predictor.py
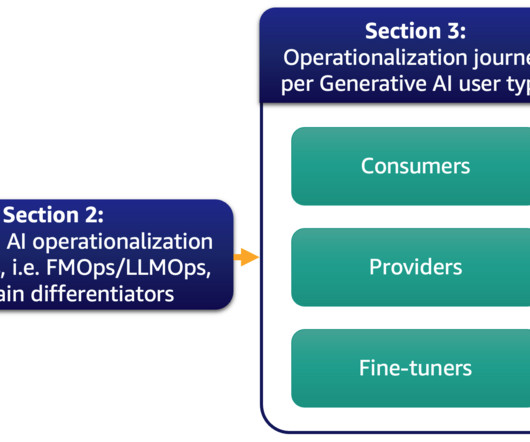
In this scenario, the generative AI application, designed by the consumer, must interact with the fine-tuner backend via APIs to deliver this functionality to the end-users. If an organization has no AI/ML experts in their team, then an API service might be better suited for them. 15K available FM reference Step 1.
We use the Recognizing Textual Entailment dataset from the GLUE benchmarking suite. Phrase 2: A bearded man pulls a rope We load the textual recognizing entailment dataset from the GLUE benchmarking suite via the dataset library from Hugging Face within our training script (./training.py training.py ).
After cycles of research and initial benchmarking efforts, CCC determined SageMaker was a perfect fit to meet a majority of their production requirements, especially the guaranteed uptime SageMaker provides for most of its inference components. Step-by-step solution Step 1 A client makes a request to the AWS API Gateway endpoint.
Our benchmarks show up to 46% price performance benefit after enabling heterogeneous clusters in a CPU-bound TensorFlow computer vision model training. Performance benchmark results. For more information, refer to Using the SageMaker Python SDK and Using the Low-Level SageMaker APIs. Heterogeneous clusters at Mobileye.
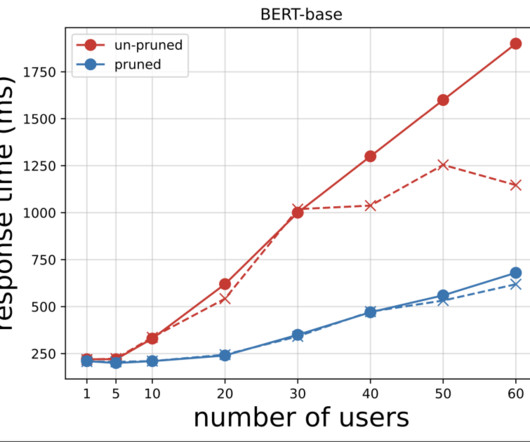
We also share the key technical challenges that were solved during construction of the Face-off Probability model. To make an informed decision, we performed a series of benchmarks to verify SageMaker latency and scalability, and validated that average latency was less than 100 milliseconds under the load, which was within our expectations.
The Trainer class provides an API for feature-complete training in PyTorch. To answer this question, we select an attack recipe from the TextAttack library and use it to construct perturbed adversarial examples to fool our target toxicity filtering model. outputs = 1 * (pred.predictions >= 0.5) Model performance evaluation.
To deploy a model from SageMaker JumpStart, you can use either APIs, as demonstrated in this post, or use the SageMaker Studio UI. The following section details the benchmark’s performance overall, and against each intent. In this example, we use Llama-2-70b-chat, but you might use a different model depending on your use case.
In this post, we describe the enhancements to the forecasting capabilities of SageMaker Canvas and guide you on using its user interface (UI) and AutoML APIs for time-series forecasting. While the SageMaker Canvas UI offers a code-free visual interface, the APIs empower developers to interact with these features programmatically.
Each trained model needs to be benchmarked against many tasks not only to assess its performances but also to compare it with other existing models, to identify areas that needs improvements and finally, to keep track of advancements in the field. These benchmarks have leaderboards that can be used to compare and contrast evaluated models.
We partnered with Keepler , a cloud-centered data services consulting company specialized in the design, construction, deployment, and operation of advanced public cloud analytics custom-made solutions for large organizations, in the creation of the first generative AI solution for one of our corporate teams.
Your application simply needs to include an API call with the target model to this endpoint to achieve low-latency, high-throughput inference. To deploy, use the endpoint_from_production_variant construct to create the endpoint. Deploying an MVE is also very straightforward. This implies each variant receives 50% of the total traffic.
With this capability, you can now optimize your prompts for several use cases with a single API call or a click of a button on the Amazon Bedrock console. In this post, we discuss how you can get started with this new feature using an example use case in addition to discussing some performance benchmarks.
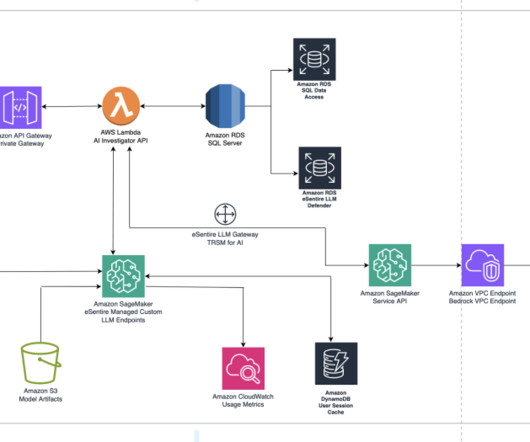
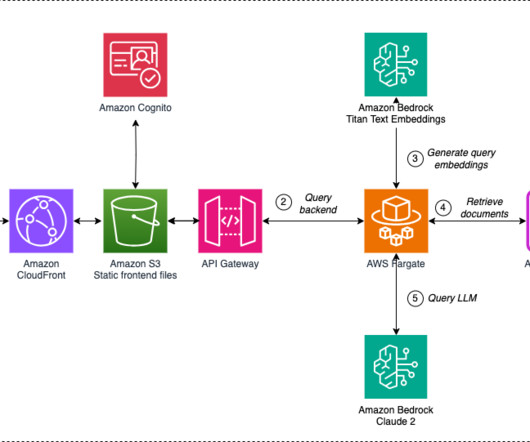
Solution overview The following diagram showcases a high-level architectural data flow that highlights various AWS services used in constructing the solution. The Amazon Bedrock unified API and robust infrastructure provided the ideal platform to develop, test, and deploy LLM solutions at scale.
For example, in a network of agents working on software development, a coordinator agent can manage overall planning, a programming agent can generate correct code and test cases, and a code review agent can provide constructive feedback on the generated code. We refer to this approach as assertion-based benchmarking.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




























Let's personalize your content