This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Using its enterprise software, FloTorch conducted an extensive comparison between Amazon Nova models and OpenAIs GPT-4o models with the Comprehensive Retrieval Augmented Generation (CRAG) benchmark dataset. FloTorch used these queries and their ground truth answers to create a subset benchmark dataset.
In this post, we explore how you can use Amazon Bedrock to generate high-quality categorical ground truth data, which is crucial for training machine learning (ML) models in a cost-sensitive environment. For the multiclass classification problem to label support case data, synthetic data generation can quickly result in overfitting.
Amazon Bedrock is a fully managed service that makes FMs from leading AI startups and Amazon available through an API, so you can choose from a wide range of FMs to find the model that is best suited for your use case. One consistent pain point of fine-tuning is the lack of data to effectively customize these models.
With GraphStorm, you can build solutions that directly take into account the structure of relationships or interactions between billions of entities, which are inherently embedded in most real-world data, including fraud detection scenarios, recommendations, community detection, and search/retrieval problems. Specifically, GraphStorm 0.3
Sonnet currently ranks at the top of S&P AI Benchmarks by Kensho , which assesses large language models (LLMs) for finance and business. For example, there could be leakage of benchmark datasets’ questions and answers into training data. Anthropic Claude 3.5 Kensho is the AI Innovation Hub for S&P Global.
Overview of Pixtral 12B Pixtral 12B, Mistrals inaugural VLM, delivers robust performance across a range of benchmarks, surpassing other open models and rivaling larger counterparts, according to Mistrals evaluation. Performance metrics and benchmarks Pixtral 12B is trained to understand both natural images and documents, achieving 52.5%
Amazon Bedrock , a fully managed service offering high-performing foundation models from leading AI companies through a single API, has recently introduced two significant evaluation capabilities: LLM-as-a-judge under Amazon Bedrock Model Evaluation and RAG evaluation for Amazon Bedrock Knowledge Bases.
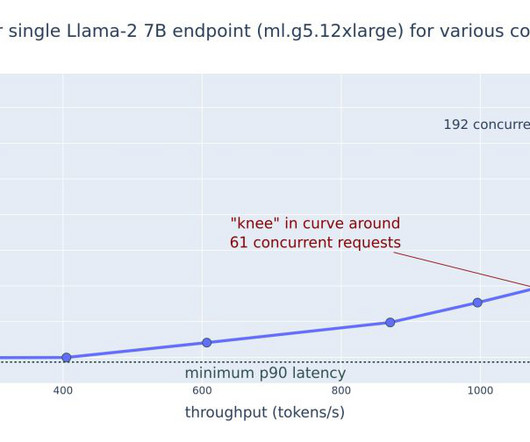
Consider benchmarking your user experience to find the best latency for your use case, considering that most humans cant read faster than 225 words per minute and therefore extremely fast response can hinder user experience. This variation stems from data travel time across networks and geographic distances.
This post focuses on doing RAG on heterogeneous data formats. We first introduce routers, and how they can help managing diverse data sources. We then give tips on how to handle tabular data and will conclude with multimodal RAG, focusing specifically on solutions that handle both text and image data.
This post explores these relationships via a comprehensive benchmarking of LLMs available in Amazon SageMaker JumpStart, including Llama 2, Falcon, and Mistral variants. We provide theoretical principles on how accelerator specifications impact LLM benchmarking. Additionally, models are fully sharded on the supported instance.
In the rapidly evolving landscape of artificial intelligence, Retrieval Augmented Generation (RAG) has emerged as a game-changer, revolutionizing how Foundation Models (FMs) interact with organization-specific data. It provides tools for chaining LLM operations, managing context, and integrating external data sources.
The technical sessions covering generative AI are divided into six areas: First, we’ll spotlight Amazon Q , the generative AI-powered assistant transforming software development and enterprise data utilization. We’ll cover Amazon Bedrock Agents , capable of running complex tasks using your company’s systems and data.
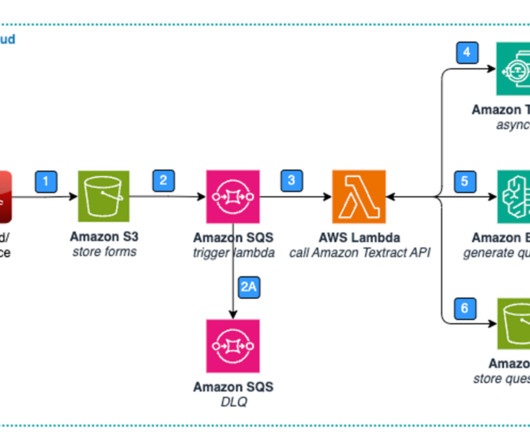
Generative artificial intelligence (AI) provides an opportunity for improvements in healthcare by combining and analyzing structured and unstructured data across previously disconnected silos. Figure 1: Architecture – Standard Form – Data Extraction & Storage.
Performance metrics and benchmarks According to Mistral, the instruction-tuned version of the model achieves over 81% accuracy on Massive Multitask Language Understanding (MMLU) with 150 tokens per second latency, making it currently the most efficient model in its category. It doesnt support Converse APIs or other Amazon Bedrock tooling.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
They are commonly used in knowledge bases to represent textual data as dense vectors, enabling efficient similarity search and retrieval. A common way to select an embedding model (or any model) is to look at public benchmarks; an accepted benchmark for measuring embedding quality is the MTEB leaderboard.
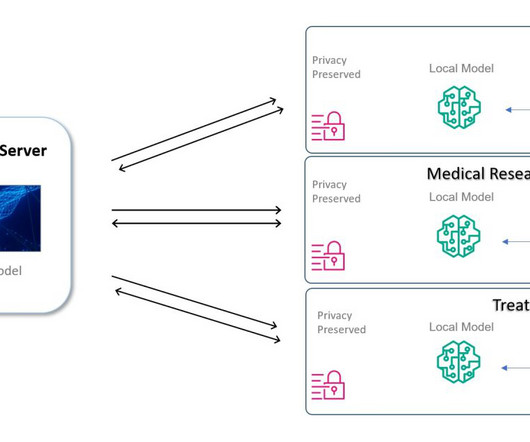
This is a guest blog post written by Nitin Kumar, a Lead Data Scientist at T and T Consulting Services, Inc. Medical data restrictions You can use machine learning (ML) to assist doctors and researchers in diagnosis tasks, thereby speeding up the process. This isolated legacy data has the potential for massive impact if cumulated.
First is the network latency, which is the round-trip time for data transmission between the device and the cloud. They enable applications requiring very low latency or local data processing using familiar APIs and tool sets. TTFT consists of two components. model=meta-llama/Llama-3.2-3B
Data scientists and machine learning engineers are constantly looking for the best way to optimize their training compute, yet are struggling with the communication overhead that can increase along with the overall cluster size. speed up compared to PyTorch’s Fully Sharded Data Parallel (FSDP). on 256 GPUs.
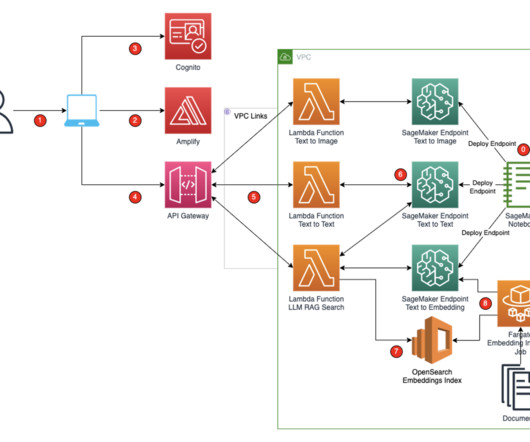
It’s powered by large language models (LLMs) that are pre-trained on vast amounts of data and commonly referred to as foundation models (FMs). These SageMaker endpoints are consumed in the Amplify React application through Amazon API Gateway and AWS Lambda functions. This dataset is a large corpus of legal and administrative data.
The solution focuses on the fundamental principles of developing an AI/ML application workflow of data preparation, model training, model evaluation, and model monitoring. Additionally, it often requires thousands or tens of thousands of hand-labeled images to provide the model with enough data to accurately make decisions.
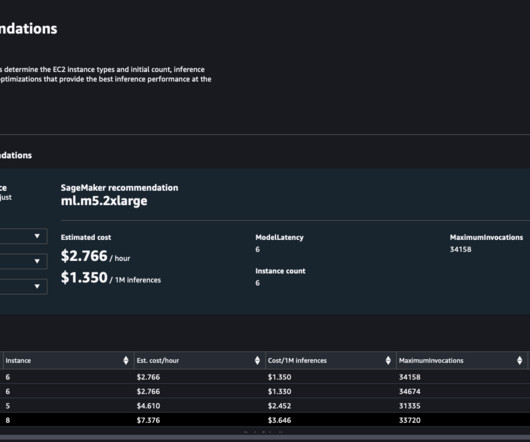
Amazon SageMaker is a fully managed service that enables developers and data scientists to quickly and easily build, train, and deploy machine learning (ML) models at scale. SageMaker makes it easy to deploy models into production directly through API calls to the service. SageMaker provides a variety of options to deploy models.
Integrate CPQ Seamlessly with CRM, ERP, and Contract Management Systems Ensure bidirectional data synchronization between CPQ and CRM so that your sales reps can access the latest customer data and pricing configurations. Use APIs and middleware to bridge gaps between CPQ and existing enterprise systems, ensuring smooth data flow.
Automated API testing stands as a cornerstone in the modern software development cycle, ensuring that applications perform consistently and accurately across diverse systems and technologies. Continuous learning and adaptation are essential, as the landscape of API technology is ever-evolving.
Acting as a model hub, JumpStart provided a large selection of foundation models and the team quickly ran their benchmarks on candidate models. Regarding the inference, customers using Amazon Ads now have a new API to receive these generated images. The Amazon API Gateway receives the PUT request (step 1).
These include the ability to analyze massive amounts of data, identify patterns, summarize documents, perform translations, correct errors, or answer questions. These examples include speeding up market trend analysis, ensuring accurate risk management and compliance, and facilitating data collection or report generation.
With such a rise in popularity of mobile usage around the world, we are delighted to announce that from February 2020, our customers will be able to test the sending of an SMS message to a destination specified by them, via the Spearline API. Access real-time reporting and analytics via Spearline API polling.
Organizations generate vast amounts of data that is proprietary to them, and it’s critical to get insights out of the data for better business outcomes. Generative AI and foundation models (FMs) play an important role in creating applications using an organization’s data that improve customer experiences and employee productivity.
Data contains information, and information can be used to predict future behaviors, from the buying habits of customers to securities returns. Businesses are seeking a competitive advantage by being able to use the data they hold, apply it to their unique understanding of their business domain, and then generate actionable insights from it.
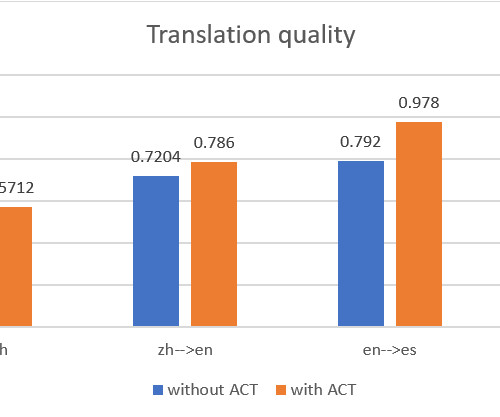
We demonstrate how to use the AWS Management Console and Amazon Translate public API to deliver automatic machine batch translation, and analyze the translations between two language pairs: English and Chinese, and English and Spanish. This results in translations that better match the style and content of the parallel data.
This is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading artificial intelligence (AI) companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon through a single API. We used the MIMIC CXR dataset , which can be accessed through a data use agreement.
Building ML models involves preparing the data for training, extracting features, and then training and fine-tuning the model using the features. Next, the model has to be put to work so that it can generate inference (or predictions) from new data, which can then be used in the application. large two-core machine.
For more information about Jamba-Instruct, including relevant benchmarks, refer to Built for the Enterprise: Introducing AI21’s Jamba-Instruct Model. Programmatic access You can also access Jamba-Instruct through an API, using Amazon Bedrock and AWS SDK for Python (Boto3).
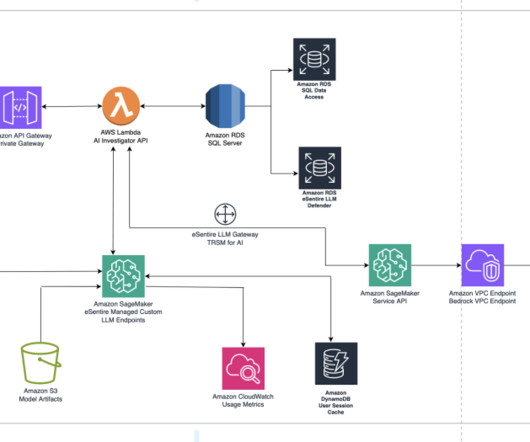
eSentire is an industry-leading provider of Managed Detection & Response (MDR) services protecting users, data, and applications of over 2,000 organizations globally across more than 35 industries. This helps customers quickly and seamlessly explore their security data and accelerate internal investigations.
So much data, so little time. Machine learning (ML) experts, data scientists, engineers and enthusiasts have encountered this problem the world over. SageMaker model training now has support for native PyTorch Distributed Data Parallel with NCCL backend, allowing developers to migrate onto SageMaker easier than ever before.
Consider revisiting the logging design of the telemetry data and adding infrastructure as code (IaC), such as document processing pipelines, to the solution. Rather than requiring your data science and IT teams to build and maintain AI models, you can use pre-trained AI services that can automate tasks for you.
RAG is the process of optimizing the output of a large language model (LLM) so it references an authoritative knowledge base outside of its training data sources before generating a response. With SageMaker JumpStart, the model is deployed in an AWS secure environment and under your VPC controls, helping provide data security.
Because the models are hosted and deployed on AWS, your data, whether used for evaluating the model or using it at scale, is never shared with third parties. Choose the model card to view details about the model such as the license, data used to train, and how to use the model. This looks pretty good!
Snowflake Arctic is a family of enterprise-grade large language models (LLMs) built by Snowflake to cater to the needs of enterprise users, exhibiting exceptional capabilities (as shown in the following benchmarks ) in SQL querying, coding, and accurately following instructions. Snowflake Arctic models are available under an Apache 2.0
The majority of data is non-fraudulent (284,315 samples), with only 492 samples corresponding to fraudulent examples. In the data, Class is the target classification variable (fraudulent vs. non-fraudulent) in the first column, followed by other variables. The class column corresponds to whether or not a transaction is fraudulent.
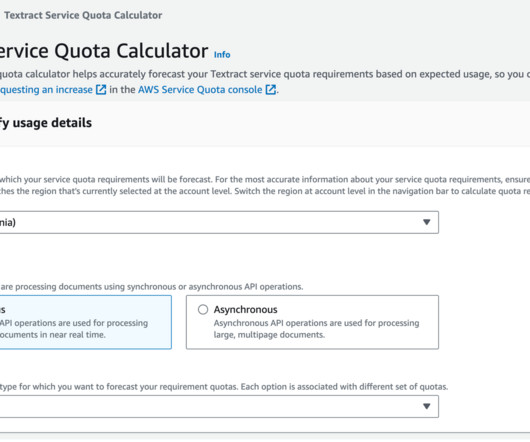
In today’s data-driven business landscape, the ability to efficiently extract and process information from a wide range of documents is crucial for informed decision-making and maintaining a competitive edge. Confidence scores and human review Maintaining data accuracy and quality is paramount in any document processing solution.
And testingRTC offers multiple ways to export these metrics, from direct collection from webhooks, to downloading results in CSV format using the REST API. And all of this data can be broken down further by probe (browser). You can drill down into any of the users for more detailed information as well as check additional channel data.
Summarize thousands of feedback with just one click Use the power of AI to save time and stress Safe and secure – none of your data will be stored anywhere outside of Lumoa If you want to also get access to the new GPT functionality, and be on the waitlist for cutting edge features, contact your CS manager or help@lumoa.me
This hyper-personalization is achieved through fine-tuning embedding models and classifiers on customer data, ensuring accurate information retrieval results and domain knowledge that caters to each client’s unique needs. In addition, deployments are now as simple as calling Boto3 SageMaker APIs and attaching the proper auto scaling policies.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





















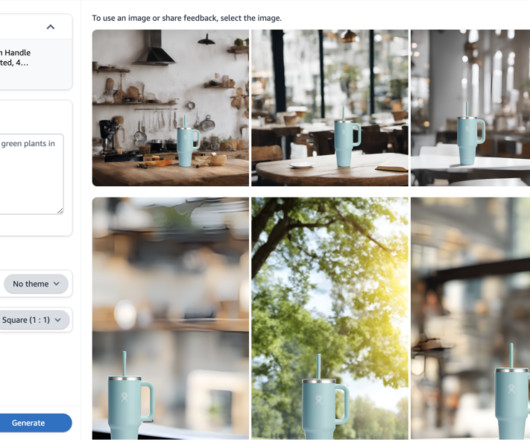























Let's personalize your content