This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
These include metrics such as ROUGE or cosine similarity for text similarity, and specific benchmarks for assessing toxicity (Detoxify), prompt stereotyping (cross-entropy loss), or factual knowledge (HELM, LAMA). Refer to Getting started with the API to set up your environment to make Amazon Bedrock requests through the AWS API.
Together, these AI-driven tools and technologies aren’t just reshaping how brands perform marketing tasks; they’re setting new benchmarks for what’s possible in customer engagement. The following figure shows schema definition and model which reference it. The main parts we use are tracking the server and model registry.
In addition, deployments are now as simple as calling Boto3 SageMaker APIs and attaching the proper auto scaling policies. We already had an API layer on top of our models for model management and inference. The main challenges were integrating a preprocessing step and accommodating two model artifacts per model definition.
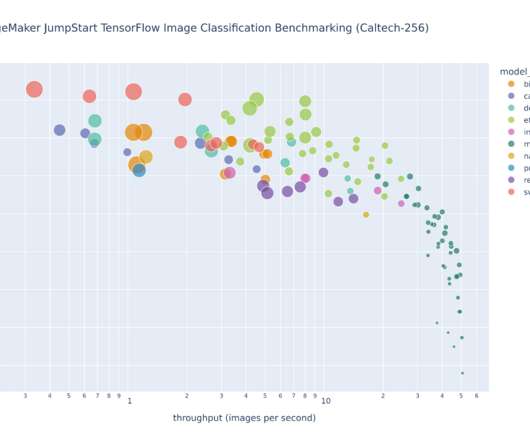
The former question addresses model selection across model architectures, while the latter question concerns benchmarking trained models against a test dataset. This post provides details on how to implement large-scale Amazon SageMaker benchmarking and model selection tasks. swin-large-patch4-window7-224 195.4M efficientnet-b5 29.0M
This is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading artificial intelligence (AI) companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon through a single API. For more details on the definition of various forms of this score, please refer to part 1 of this blog.
In addition, they use the developer-provided instruction to create an orchestration plan and then carry out the plan by invoking company APIs and accessing knowledge bases using Retrieval Augmented Generation (RAG) to provide an answer to the user’s request. In Part 1, we focus on creating accurate and reliable agents.
Establishing customer trust and loyalty is the single most important aspect of customer experience, according to the Dimension Data 2019 Global Customer Experience Benchmarking Report. In the event that we do need to interact with a business, having multiple options for engagement definitely helps.
Because we wanted to track the metrics of an ongoing training job and compare them with previous training jobs, we just had to parse this StdOut by defining the metric definitions through regex to fetch the metrics from StdOut for every epoch. amazonaws.com/tensorflow-training:2.11.0-cpu-py39-ubuntu20.04-sagemaker", cpu-py39-ubuntu20.04-sagemaker",
In terms of resulting speedups, the approximate order is programming hardware, then programming against PBA APIs, then programming in an unmanaged language such as C++, then a managed language such as Python. The CUDA API and SDK were first released by NVIDIA in 2007. GPU PBAs, 4% other PBAs, 4% FPGA, and 0.5%
For more information about regression and classification problem types, refer to Inference container definitions for regression and classification problem types. To launch an Autopilot job using the SageMaker Boto3 libraries, we use the create_auto_ml_job API. Then we send inference requests to these hosted endpoints.
We’ll definitely be writing more about that. Banking giant ING recently switched from an Avaya call center to a system built internally using Twilio APIs. Understanding Industry Benchmarks. Oracle is entering the game with “ Customer Engagement Cloud ”. Talkdesk is making strong gains. Wink wink.). More Reading.
We discuss the important components of fine-tuning, including use case definition, data preparation, model customization, and performance evaluation. Tools and APIs – For example, when you need to teach Anthropic’s Claude 3 Haiku how to use your APIs well. For the learning rate multiplier, the value ranges between 0.1–2.0,
Autotune uses best practices as well as internal benchmarks for selecting the appropriate ranges. Autotune automatically chooses the optimal configurations for your tuning job, helps prevent wasted resources, and accelerates productivity. Autotune will automatically select the hyperparameter ranges on your behalf.
The generated models are stored and benchmarked in the Amazon SageMaker model registry. A SageMaker pipeline is a series of interconnected steps (SageMaker processing jobs, training, HPO) that is defined by a JSON pipeline definition using a Python SDK. This pipeline definition encodes a pipeline using a Directed Acyclic Graph (DAG).
The customer experience management definition extends beyond traditional customer serviceit is an enterprise-wide strategy that integrates AI, automation, and real-time analytics to optimize every interaction across digital and physical touchpoints. Establish benchmarks to track improvements over time.
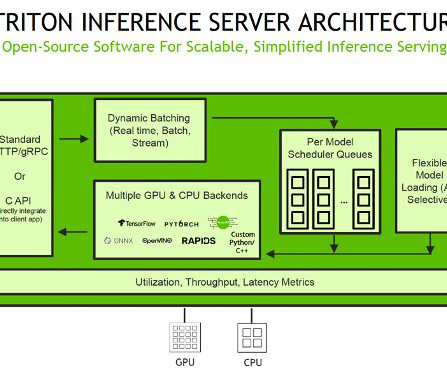
To use TensorRT as a backend for Triton Inference Server, you need to create a TensorRT engine from your trained model using the TensorRT API. The trtexec tool has three main purposes: Benchmarking networks on random or user-provided input data. For this post, we use the trtexec CLI tool. Generating serialized engines from models.
To validate the drawbacks of this existing MVP architecture, Medidata performed some initial benchmarking to understand and prioritize the bottlenecks of this pipeline. The definition of a bulk request here corresponds to a payload that is a collection of operational site data to be processed rather than a single instance of a request.
After cycles of research and initial benchmarking efforts, CCC determined SageMaker was a perfect fit to meet a majority of their production requirements, especially the guaranteed uptime SageMaker provides for most of its inference components. Step-by-step solution Step 1 A client makes a request to the AWS API Gateway endpoint.
Our benchmarks show up to 46% price performance benefit after enabling heterogeneous clusters in a CPU-bound TensorFlow computer vision model training. Performance benchmark results. For more information, refer to Using the SageMaker Python SDK and Using the Low-Level SageMaker APIs. Heterogeneous clusters at Mobileye.
Role context – Start each prompt with a clear role definition. This involves benchmarking new models against our current selections across various metrics, running A/B tests, and gradually incorporating high-performing models into our production pipeline. For example, “You are an AWS Account Manager preparing for a customer meeting.”
To deploy a model from SageMaker JumpStart, you can use either APIs, as demonstrated in this post, or use the SageMaker Studio UI. The trend continued with Jane from Australia, who on Nov 12th requested a shipment of ten high-definition monitors with total of $9000, emphasizing the need for environmentally friendly packaging.
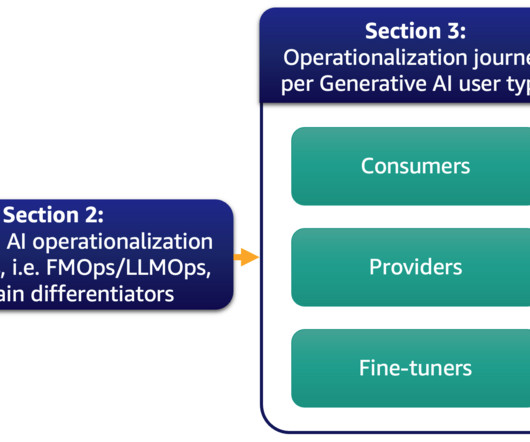
Generative AI definitions and differences to MLOps In classic ML, the preceding combination of people, processes, and technology can help you productize your ML use cases. If an organization has no AI/ML experts in their team, then an API service might be better suited for them. Only prompt engineering is necessary for better results.
Before you start evaluating data sources, you need to establish an internal definition of accuracy for the type of data you’re looking for, then determine how you will measure that accuracy. From there, you’ll know how to benchmark the data sources you’re reviewing. These two qualities can sometimes be at odds (e.g., While the U.S.
And when you think about the range of features the latter offers at $49 per user per month — all 3 dialers, bulk SMS campaigns and workflows, live call monitoring , advanced analytics and reporting, API and webhooks, live call monitoring, and so much more, it is simply astounding. How are JustCall’s Sales Dialer and Mojo Dialer different?
Conversational AI enables the system to perform end-to-end actions through Application Programming Interfaces (API). You can compare your reps’ performance with industry benchmarks across industries and roles. There’s no definite pricing for conversation intelligence software. These features facilitate more autonomous tasks.
Once you have a benchmark that can be decided according to the industry you are in, measuring your NPS frequently will help you to monitor and track progress to avoid a high churn rate and improve retention. However, working towards an NPS between 50-80 is definitely a great achievement for any business.
Each trained model needs to be benchmarked against many tasks not only to assess its performances but also to compare it with other existing models, to identify areas that needs improvements and finally, to keep track of advancements in the field. These benchmarks have leaderboards that can be used to compare and contrast evaluated models.
But, before that, let us look at the definition of conversation intelligence. With any software mentioned in this list, you can run quicker call QA, deliver personalized SDR coaching, and enhance conversation outcomes like improved CSAT, higher NPS, better sales, etc. What is conversation intelligence?
This was accomplished by using foundation models (FMs) to transform natural language into structured queries that are compatible with our products GraphQL API. For example, what if the model generates a filter with a key not supported by our API? Translate it to a GraphQL API request. Validate the JSON schema on the response.
Benchmark comparisons show Amazon Nova Pro matching or even surpassing GPT-4o on complex reasoning tasks, according to section 2.1.1 You can find these benchmark results in section 2.1.2 You need to reframe your use case definition. OpenAIs function calling uses flexible JSON schemas to define and structure API interactions.
Sonnet, along with Nova Micro, Nova Lite, and Nova Pro models, lowers response latency by up to 85% and reduces costs up to 90% by caching frequently used prompts across multiple API calls. By caching the system prompts and complex tool definitions, the time to process each step in the agentic flow can be reduced. Haiku and Claude 3.7
However, as industries require more adaptive, decision-making AI, integrating tools and external APIs has become essential. Expanding LLM capabilities with tool use LLMs excel at natural language tasks but become significantly more powerful with tool integration, such as APIs and computational frameworks.
Dataset The dataset for this post is manually distilled from the Amazon Science evaluation benchmark dataset called TofuEval. Refer to the evaluation metrics section for accuracy definition) This continues for N(=3 in this notebook) rounds. Details on the exact dataset can be found in the GitHub repository.
This approach not only establishes new benchmarks for medical RAG evaluation, but also provides practitioners with practical tools to build more reliable and accurate healthcare AI applications that can be trusted in clinical settings. No definite pneumonia.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content