This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
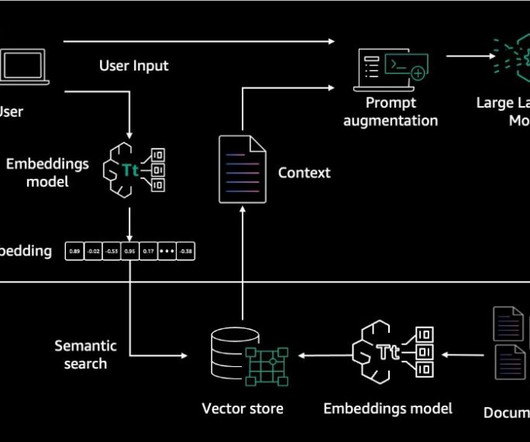
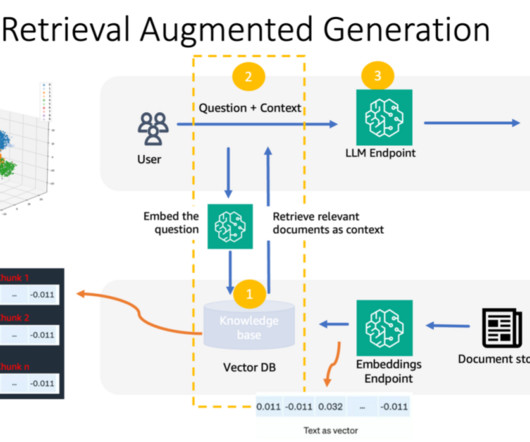
Using its enterprise software, FloTorch conducted an extensive comparison between Amazon Nova models and OpenAIs GPT-4o models with the Comprehensive Retrieval Augmented Generation (CRAG) benchmark dataset. FloTorch used these queries and their ground truth answers to create a subset benchmark dataset.
Overview of Pixtral 12B Pixtral 12B, Mistrals inaugural VLM, delivers robust performance across a range of benchmarks, surpassing other open models and rivaling larger counterparts, according to Mistrals evaluation. Performance metrics and benchmarks Pixtral 12B is trained to understand both natural images and documents, achieving 52.5%
Lets say the task at hand is to predict the root cause categories (Customer Education, Feature Request, Software Defect, Documentation Improvement, Security Awareness, and Billing Inquiry) for customer support cases. For a multiclass classification problem such as support case root cause categorization, this challenge compounds many fold.
In today’s data-driven business landscape, the ability to efficiently extract and process information from a wide range of documents is crucial for informed decision-making and maintaining a competitive edge. The Anthropic Claude 3 Haiku model then processes the documents and returns the desired information, streamlining the entire workflow.
adds new APIs to customize GraphStorm pipelines: you now only need 12 lines of code to implement a custom node classification training loop. For more details about how to run graph multi-task learning with GraphStorm, refer to Multi-task Learning in GraphStorm in our documentation. introduces refactored graph ML pipeline APIs.
Amazon Bedrock is a fully managed service that offers a choice of high-performing Foundation Models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon via a single API, along with a broad set of capabilities you need to build generative AI applications with security, privacy, and responsible AI.
Amazon Bedrock is a fully managed service that makes FMs from leading AI startups and Amazon available through an API, so you can choose from a wide range of FMs to find the model that is best suited for your use case. Solution overview The solution comprises two main steps: Generate synthetic data using the Amazon Bedrock InvokeModel API.
Sonnet currently ranks at the top of S&P AI Benchmarks by Kensho , which assesses large language models (LLMs) for finance and business. For example, there could be leakage of benchmark datasets’ questions and answers into training data. Anthropic Claude 3.5 Kensho is the AI Innovation Hub for S&P Global. Anthropic Claude 3.5
Amazon Bedrock , a fully managed service offering high-performing foundation models from leading AI companies through a single API, has recently introduced two significant evaluation capabilities: LLM-as-a-judge under Amazon Bedrock Model Evaluation and RAG evaluation for Amazon Bedrock Knowledge Bases. 0]}-{evaluator_model.split('.')[0]}-{datetime.now().strftime('%Y-%m-%d-%H-%M-%S')}"
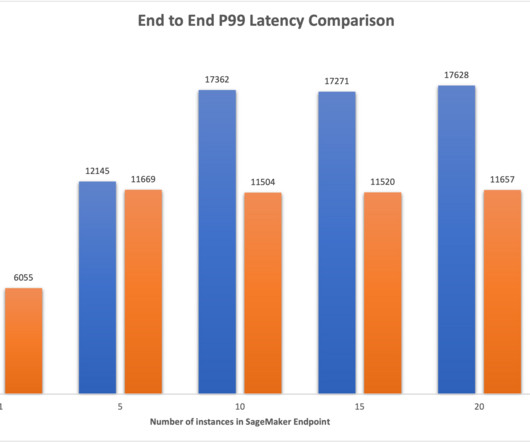
Consider benchmarking your user experience to find the best latency for your use case, considering that most humans cant read faster than 225 words per minute and therefore extremely fast response can hinder user experience. In such scenarios, you want to optimize for TTFT. Users prefer accurate responses over quick but less reliable ones.
This centralized system consolidates a wide range of data sources, including detailed reports, FAQs, and technical documents. The system integrates structured data, such as tables containing product properties and specifications, with unstructured text documents that provide in-depth product descriptions and usage guidelines.
Its agent for software development can solve complex tasks that go beyond code suggestions, such as building entire application features, refactoring code, or generating documentation. Attendees will learn practical applications of generative AI for streamlining and automating document-centric workflows. Hear from Availity on how 1.5
The healthcare industry generates and collects a significant amount of unstructured textual data, including clinical documentation such as patient information, medical history, and test results, as well as non-clinical documentation like administrative records. Lastly, the Lambda function stores the question list in Amazon S3.
In September of 2023, we announced the launch of Amazon Titan Text Embeddings V1, a multilingual text embeddings model that converts text inputs like single words, phrases, or large documents into high-dimensional numerical vector representations. In this benchmark, 33 different text embedding models were evaluated on the MTEB tasks.
Jamba-Instruct is built by AI21 Labs, and most notably supports a 256,000-token context window, making it especially useful for processing large documents and complex Retrieval Augmented Generation (RAG) applications. Prompt guidance for Jamba-Instruct can be found in the AI21 model documentation.
You can use the BGE embedding model to retrieve relevant documents and then use the BGE reranker to obtain final results. On Hugging Face, the Massive Text Embedding Benchmark (MTEB) is provided as a leaderboard for diverse text embedding tasks. It currently provides 129 benchmarking datasets across 8 different tasks on 113 languages.
They enable applications requiring very low latency or local data processing using familiar APIs and tool sets. Through comparative benchmarking tests, we illustrate how deploying FMs in Local Zones closer to end users can significantly reduce latencya critical factor for real-time applications such as conversational AI assistants.
When a customer has a production-ready intelligent document processing (IDP) workload, we often receive requests for a Well-Architected review. To follow along with this post, you should be familiar with the previous posts in this series ( Part 1 and Part 2 ) and the guidelines in Guidance for Intelligent Document Processing on AWS.
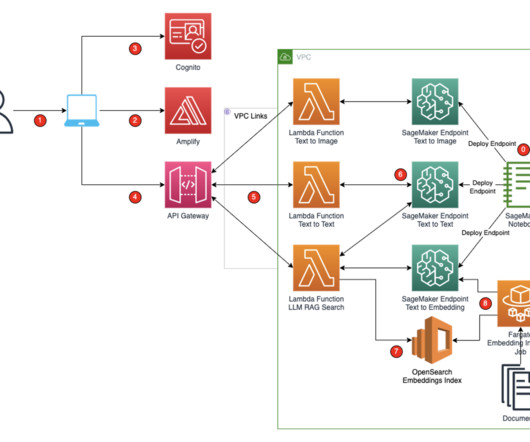
These SageMaker endpoints are consumed in the Amplify React application through Amazon API Gateway and AWS Lambda functions. To protect the application and APIs from inadvertent access, Amazon Cognito is integrated into Amplify React, API Gateway, and Lambda functions. You access the React application from your computer.
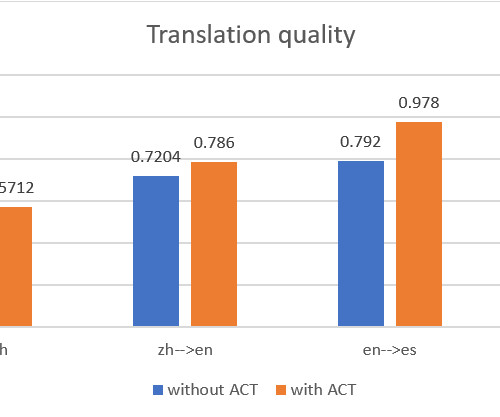
We demonstrate how to use the AWS Management Console and Amazon Translate public API to deliver automatic machine batch translation, and analyze the translations between two language pairs: English and Chinese, and English and Spanish. First, we put the source documents, reference documents, and parallel data training set in an S3 bucket.
You can use this tutorial as a starting point for a variety of chatbot-based solutions for customer service, internal support, and question answering systems based on internal and private documents. This makes the models especially powerful at tasks such as clustering for long documents like legal text or product documentation.
In addition, RAG architecture can lead to potential issues like retrieval collapse , where the retrieval component learns to retrieve the same documents regardless of the input. Lack of standardized benchmarks – There are no widely accepted and standardized benchmarks yet for holistically evaluating different capabilities of RAG systems.
SageMaker makes it easy to deploy models into production directly through API calls to the service. It’s a low-level API available for Java, C++, Go, JavaScript, Node.js, PHP, Ruby, and Python. It’s a low-level API available for Java, C++, Go, JavaScript, Node.js, PHP, Ruby, and Python.
Amazon Comprehend is a natural-language processing (NLP) service you can use to automatically extract entities, key phrases, language, sentiments, and other insights from documents. All you need to do is load your dataset of documents and annotations, and use the Amazon Comprehend console, AWS CLI, or APIs to create the model.
These include the ability to analyze massive amounts of data, identify patterns, summarize documents, perform translations, correct errors, or answer questions. This involves documenting data lineage, data versioning, automating data processing, and monitoring data management costs.
Model choices – SageMaker JumpStart offers a selection of state-of-the-art ML models that consistently rank among the top in industry-recognized HELM benchmarks. For instance, a financial firm might prefer its Q&A bot to source answers from its latest internal documents, ensuring accuracy and compliance with its business rules.
AI Service Cards are a form of responsible AI documentation that provide customers with a single place to find information on the intended use cases and limitations, responsible AI design choices, and deployment and performance optimization best practices for our AI services and models.
What is Mixtral 8x22B Mixtral 8x22B is Mistral AI’s latest open-weights model and sets a new standard for performance and efficiency of available foundation models , as measured by Mistral AI across standard industry benchmarks. making the model available for exploring, testing, and deploying.
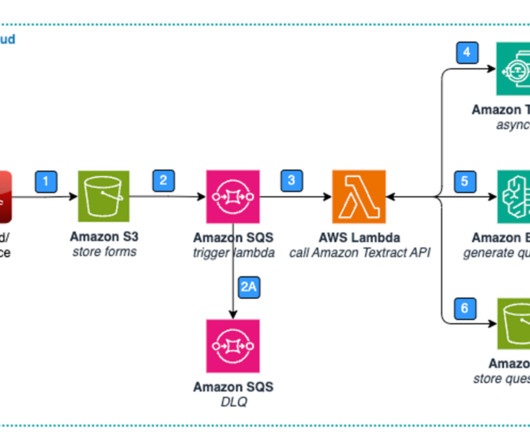
An intelligent document processing (IDP) project usually combines optical character recognition (OCR) and natural language processing (NLP) to read and understand a document and extract specific terms or words. As of this writing, it includes the following values: TABLES , FORMS , QUERIES , SIGNATURES , and LAYOUT.
In addition, they use the developer-provided instruction to create an orchestration plan and then carry out the plan by invoking company APIs and accessing knowledge bases using Retrieval Augmented Generation (RAG) to provide an answer to the user’s request. In Part 1, we focus on creating accurate and reliable agents.
The team’s early benchmarking results show 7.3 The baseline model used in these benchmarking is a multi-layer perceptron neural network with seven dense fully connected layers and over 200 parameters. The following table summarizes the benchmarking result on ml.p3.16xlarge SageMaker training instances. Number of Instances.
And testingRTC offers multiple ways to export these metrics, from direct collection from webhooks, to downloading results in CSV format using the REST API. testingRTC is predominantly a self-service platform, where you write and test any script you want independently of us with our extensive knowledge base documentation as a guide.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
Manually creating customized communication documents like quotes, invoices, contracts, and reports is an inefficient process prone to human error. If you’re considering implementing a document automation solution for your organization, there are several key capabilities to evaluate during your search. What Is Document Automation?
When ML models deployed on instances receive API calls from a large number of clients, a random distribution of requests can work very well when there is not a lot of variability in your requests and responses. To learn more about SageMaker routing features, refer to documentation.
Refer to the appendix for instance details and benchmark data. To access the code and documentation, refer to the GitHub repo. Given a document as an input, the model will answer simple questions based on the learning and contexts from the input document. The following diagram illustrates the high-level flow.
They show the usage of various SageMaker and JumpStart APIs. This notebook demonstrates how to deploy AlexaTM 20B through the JumpStart API and run inference. NTM is most commonly used to discover a user-specified number of topics shared by documents within a text corpus. This is called zero-shot in-context learning.
This is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading artificial intelligence (AI) companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon through a single API. It’s serverless, so you don’t have to manage any infrastructure.
Although existing large language model (LLM) benchmarks like MT-bench evaluate model capabilities, they lack the ability to validate the application layers. Refer to the agent-evaluation target documentation for details. The principal must have the permissions to call the target agent.
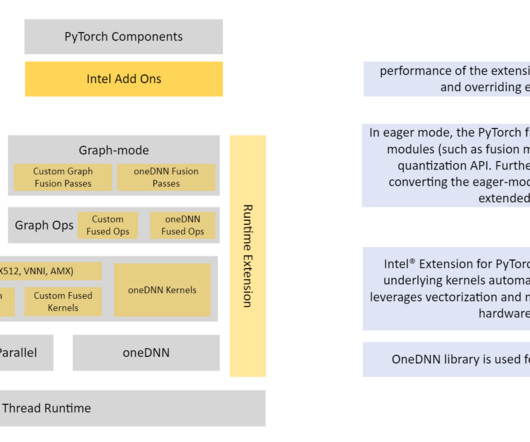
Finally, we’ll benchmark performance of 13B, 50B, and 100B parameter auto-regressive models and wrap up with future work. For training a different model type, you can follow the APIdocument to learn about how to apply SMP APIs. You can refer to this document for supported configurations. Benchmarking performance.
To get started, follow Modify a PyTorch Training Script to adapt SMPs’ APIs in your training script. You can follow the comments in the script and APIdocument to learn more about where SMP APIs are used. Benchmarking performance. We benchmarked sharded data parallelism in the SMP library on both 16 and 32 p4d.24xlarge
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon via a single API. Kojima et al. 2022) introduced an idea of zero-shot CoT by using FMs’ untapped zero-shot capabilities.
Tools and APIs – For example, when you need to teach Anthropic’s Claude 3 Haiku how to use your APIs well. Based on our hyperparameter tuning experiments across different use cases, the API allows a range of 4–256, with a default of 32.
Snowflake Arctic is a family of enterprise-grade large language models (LLMs) built by Snowflake to cater to the needs of enterprise users, exhibiting exceptional capabilities (as shown in the following benchmarks ) in SQL querying, coding, and accurately following instructions. To learn more, refer to APIdocumentation.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content