This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
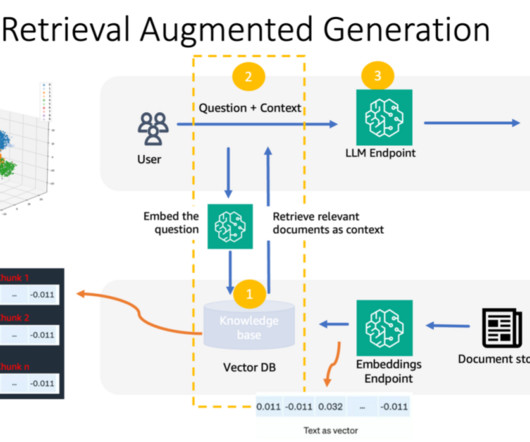
Using its enterprise software, FloTorch conducted an extensive comparison between Amazon Nova models and OpenAIs GPT-4o models with the Comprehensive Retrieval Augmented Generation (CRAG) benchmark dataset. FloTorch used these queries and their ground truth answers to create a subset benchmark dataset.
Consider benchmarking your user experience to find the best latency for your use case, considering that most humans cant read faster than 225 words per minute and therefore extremely fast response can hinder user experience. In such scenarios, you want to optimize for TTFT. Users prefer accurate responses over quick but less reliable ones.
Amazon Bedrock , a fully managed service offering high-performing foundation models from leading AI companies through a single API, has recently introduced two significant evaluation capabilities: LLM-as-a-judge under Amazon Bedrock Model Evaluation and RAG evaluation for Amazon Bedrock Knowledge Bases. 0]}-{evaluator_model.split('.')[0]}-{datetime.now().strftime('%Y-%m-%d-%H-%M-%S')}"
This requirement translates into time and effort investment of trained personnel, who could be support engineers or other technical staff, to review tens of thousands of support cases to arrive at an even distribution of 3,000 per category. Sonnet prediction accuracy through prompt engineering. client = boto3.client("bedrock-runtime",
Amazon Bedrock is a fully managed service that offers a choice of high-performing Foundation Models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon via a single API, along with a broad set of capabilities you need to build generative AI applications with security, privacy, and responsible AI.
Use cases we have worked on include: Technical assistance for field engineers – We built a system that aggregates information about a company’s specific products and field expertise. A chatbot enables field engineers to quickly access relevant information, troubleshoot issues more effectively, and share knowledge across the organization.
Model choices – SageMaker JumpStart offers a selection of state-of-the-art ML models that consistently rank among the top in industry-recognized HELM benchmarks. We also use Vector Engine for Amazon OpenSearch Serverless (currently in preview) as the vector data store to store embeddings. Lewis et al.
Performance metrics and benchmarks According to Mistral, the instruction-tuned version of the model achieves over 81% accuracy on Massive Multitask Language Understanding (MMLU) with 150 tokens per second latency, making it currently the most efficient model in its category. It doesnt support Converse APIs or other Amazon Bedrock tooling.
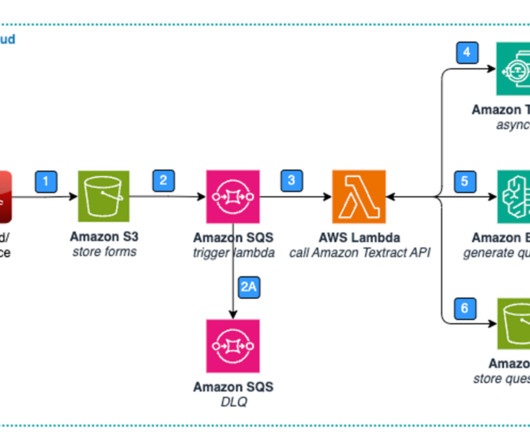
Acting as a model hub, JumpStart provided a large selection of foundation models and the team quickly ran their benchmarks on candidate models. Here, Amazon SageMaker Ground Truth allowed ML engineers to easily build the human-in-the-loop workflow (step v). The Amazon API Gateway receives the PUT request (step 1).
Leave the session inspired to bring Amazon Q Apps to supercharge your teams’ productivity engines. Reserve your seat now AIM405: Learn to securely invoke Amazon Q Business Chat API December Wednesday 4 | 2:30 PM – 3:30 PM Join this code talk to learn how to use the Amazon Q Business identity-aware ChatSync API.
Amazon Bedrock is a fully managed service that makes FMs from leading AI startups and Amazon available through an API, so you can choose from a wide range of FMs to find the model that is best suited for your use case. Solution overview The solution comprises two main steps: Generate synthetic data using the Amazon Bedrock InvokeModel API.
A common way to select an embedding model (or any model) is to look at public benchmarks; an accepted benchmark for measuring embedding quality is the MTEB leaderboard. The Massive Text Embedding Benchmark (MTEB) evaluates text embedding models across a wide range of tasks and datasets.
This is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading artificial intelligence (AI) companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon through a single API. There are many prompt engineering techniques. It is time-consuming but, at the same time, critical.
Amazon Bedrock is a fully managed service that makes foundation models (FMs) from leading AI startups and Amazon available through an API, so you can choose from a wide range of FMs to find the model that is best suited for your use case. Lastly, the Lambda function stores the question list in Amazon S3.
SageMaker makes it easy to deploy models into production directly through API calls to the service. It’s a low-level API available for Java, C++, Go, JavaScript, Node.js, PHP, Ruby, and Python. It’s a low-level API available for Java, C++, Go, JavaScript, Node.js, PHP, Ruby, and Python.
Machine learning (ML) experts, data scientists, engineers and enthusiasts have encountered this problem the world over. The team’s early benchmarking results show 7.3 The baseline model used in these benchmarking is a multi-layer perceptron neural network with seven dense fully connected layers and over 200 parameters.
Although you can integrate the model directly into an application, the approach that works well for production-grade applications is to deploy the model behind an endpoint and then invoke the endpoint via a RESTful API call to obtain the inference. However, you can use any other benchmarking tool. large two-core machine.
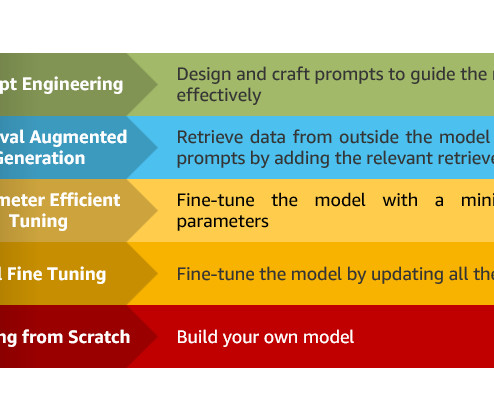
We provide an overview of key generative AI approaches, including prompt engineering, Retrieval Augmented Generation (RAG), and model customization. Building large language models (LLMs) from scratch or customizing pre-trained models requires substantial compute resources, expert data scientists, and months of engineering work.
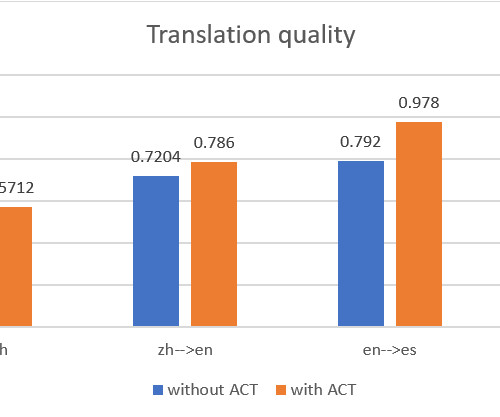
Welocalize benchmarks the performance of using LLMs and machine translations and recommends using LLMs as a post-editing tool. in Mechanical Engineering from the University of Notre Dame. Max Goff is a data scientist/data engineer with over 30 years of software development experience. She received her Ph.D.
The solution uses the following services: Amazon API Gateway is a fully managed service that makes it easy for developers to publish, maintain, monitor, and secure APIs at any scale. Purina’s solution is deployed as an API Gateway HTTP endpoint, which routes the requests to obtain pet attributes.
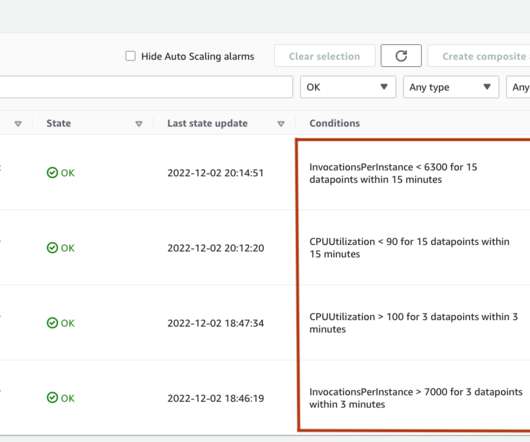
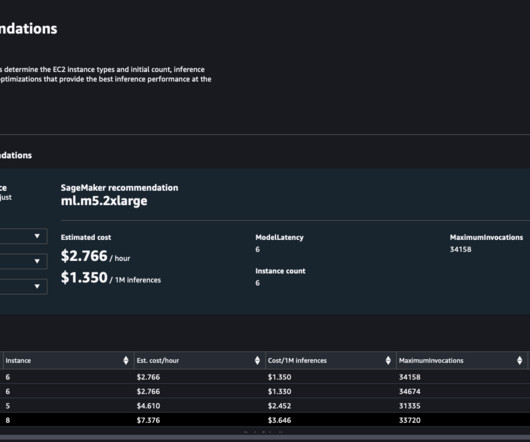
Also, you can build these ML systems with a combination of ML models, tasks, frameworks, libraries, tools, and inference engines, making it important to evaluate the ML system performance for the best possible deployment configurations. Inference Recommender uses this information to run a performance benchmark load test.
This post is co-written with Jad Chamoun, Director of Engineering at Forethought Technologies, Inc. and Salina Wu, Senior ML Engineer at Forethought Technologies, Inc. Forethought had to manage model inference on Amazon EKS ourselves, which was a burden on engineering efficiency.
With such a rise in popularity of mobile usage around the world, we are delighted to announce that from February 2020, our customers will be able to test the sending of an SMS message to a destination specified by them, via the Spearline API. Access real-time reporting and analytics via Spearline API polling. UI REDESIGN.
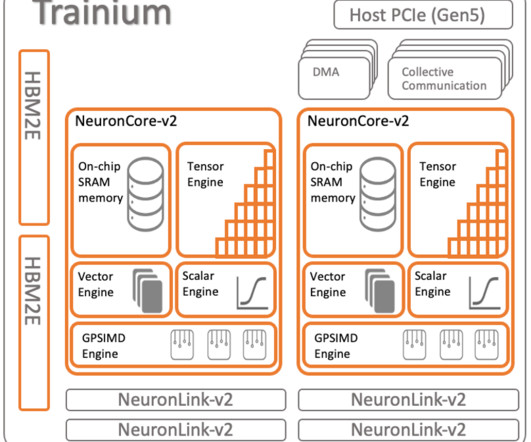
Trainium support for custom operators Trainium (and AWS Inferentia2) supports CustomOps in software through the Neuron SDK and accelerates them in hardware using the GPSIMD engine (General Purpose Single Instruction Multiple Data engine). The scalar and vector engines are highly parallelized and optimized for floating-point operations.
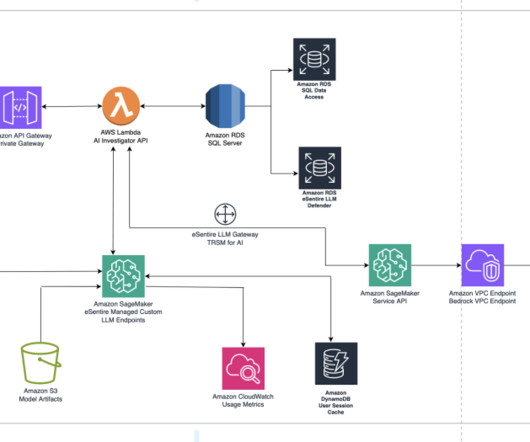
The application’s frontend is accessible through Amazon API Gateway , using both edge and private gateways. To emulate intricate thought processes akin to those of a human investigator, eSentire engineered a system of chained agent actions. He focuses on advancing cybersecurity with expertise in machine learning and data engineering.
Examples of tools you can use to advance sustainability initiatives are: Amazon Bedrock – a fully managed service that provides access to high-performing FMs from leading AI companies through a single API, enabling you to choose the right model for your sustainability use cases.
We demonstrate how to use the AWS Management Console and Amazon Translate public API to deliver automatic machine batch translation, and analyze the translations between two language pairs: English and Chinese, and English and Spanish. In this post, we present a solution that D2L.ai
When ML models deployed on instances receive API calls from a large number of clients, a random distribution of requests can work very well when there is not a lot of variability in your requests and responses. Deepti Ragha is a Software Development Engineer in the Amazon SageMaker team.
It’s important for all departments to have benchmarks for success that can be easily measured and tracked. Call center and customer service teams have a variety of KPIs to choose from, but as each company and support department is different, their benchmarks will vary. He leads product management for Nexmo, the Vonage API Platform.
In this post, we explore the latest features introduced in this release, examine performance benchmarks, and provide a detailed guide on deploying new LLMs with LMI DLCs at high performance. TensorRT-LLM requires models to be compiled into efficient engines before deployment. For more details, refer to the GitHub repo.
Use APIs and middleware to bridge gaps between CPQ and existing enterprise systems, ensuring smooth data flow. Automate Price Calculations and Adjustments Utilize real-time pricing engines within CPQ to dynamically calculate prices based on market trends, cost fluctuations, and competitor benchmarks.
Finally, we’ll benchmark performance of 13B, 50B, and 100B parameter auto-regressive models and wrap up with future work. For training a different model type, you can follow the API document to learn about how to apply SMP APIs. Benchmarking performance. Finally, we benchmark SMP with both of the latest features enabled.
In particular, we provide practical best practices for different customization scenarios, including training models from scratch, fine-tuning with additional data using full or parameter-efficient techniques, Retrieval Augmented Generation (RAG), and prompt engineering.
It has the highest accuracy of any customer service chatbot due to its advanced Natural Language Understanding (NLU) engine. CSML is the first open-source programming language and chatbot engine dedicated to developing powerful and interoperable chatbots. Self-service APIs to help you create, manage, test and publish custom skills.
To overcome this, enterprises needs to shape a clear operating model defining how multiple personas, such as data scientists, data engineers, ML engineers, IT, and business stakeholders, should collaborate and interact; how to separate the concerns, responsibilities, and skills; and how to use AWS services optimally.
In terms of resulting speedups, the approximate order is programming hardware, then programming against PBA APIs, then programming in an unmanaged language such as C++, then a managed language such as Python. Each GPC has a raster engine for graphics and several TPCs. The CUDA API and SDK were first released by NVIDIA in 2007.
Although existing large language model (LLM) benchmarks like MT-bench evaluate model capabilities, they lack the ability to validate the application layers. Evaluator considerations By default, evaluators use the InvokeModel API with On-Demand mode, which will incur AWS charges based on input tokens processed and output tokens generated.
For benchmark performance figures, refer to AWS Neuron Performance. Each NeuronCore-v2 is an independent, heterogenous compute-unit, with four main engines: Tensor, Vector, Scalar, and GPSIMD engines. engine=Python because the handles are implement in python. This is particularly useful for large language models.
You can save time, money, and labor by implementing classifications in your workflow, and documents go to downstream applications and APIs based on document type. This helps you avoid throttling limits on API calls due to polling the Get* APIs.
Rather than requiring extensive feature engineering and dataset labeling, LLMs can be fine-tuned on small amounts of domain-specific data to quickly adapt to new use cases. This post walks through examples of building information extraction use cases by combining LLMs with prompt engineering and frameworks such as LangChain.
On Hugging Face, the Massive Text Embedding Benchmark (MTEB) is provided as a leaderboard for diverse text embedding tasks. It currently provides 129 benchmarking datasets across 8 different tasks on 113 languages. medium instance to demonstrate deploying the model as an API endpoint using an SDK through SageMaker JumpStart.
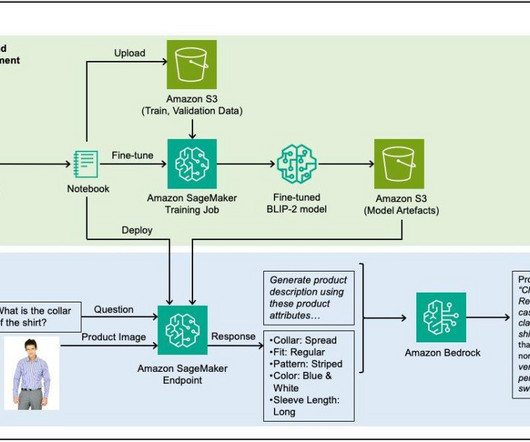
Customers can more easily locate products that have correct descriptions, because it allows the search engine to identify products that match not just the general category but also the specific attributes mentioned in the product description. Lun Yeh is a Machine Learning Engineer at AWS Professional Services.
Data scientists and machine learning engineers are constantly looking for the best way to optimize their training compute, yet are struggling with the communication overhead that can increase along with the overall cluster size. To get started, follow Modify a PyTorch Training Script to adapt SMPs’ APIs in your training script.
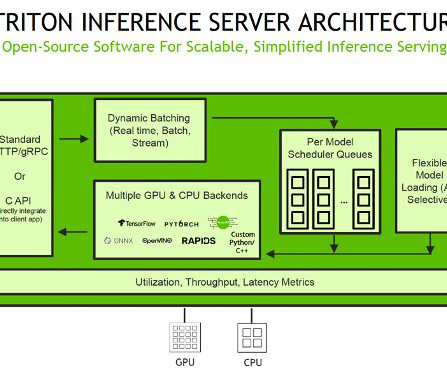
To serve models, Triton supports various backends as engines to support the running and serving of various ML models for inference. With kernel auto-tuning, the engine selects the best algorithm for the target GPU, maximizing hardware utilization. Import the ONNX model into TensorRT and generate the TensorRT engine.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content