This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
These models offer enterprises a range of capabilities, balancing accuracy, speed, and cost-efficiency. Using its enterprise software, FloTorch conducted an extensive comparison between Amazon Nova models and OpenAIs GPT-4o models with the Comprehensive Retrieval Augmented Generation (CRAG) benchmark dataset.
Overview of Pixtral 12B Pixtral 12B, Mistrals inaugural VLM, delivers robust performance across a range of benchmarks, surpassing other open models and rivaling larger counterparts, according to Mistrals evaluation. Performance metrics and benchmarks Pixtral 12B is trained to understand both natural images and documents, achieving 52.5%
GraphStorm is a low-code enterprise graph machine learning (GML) framework to build, train, and deploy graph ML solutions on complex enterprise-scale graphs in days instead of months. adds new APIs to customize GraphStorm pipelines: you now only need 12 lines of code to implement a custom node classification training loop.
This blog post delves into how these innovative tools synergize to elevate the performance of your AI applications, ensuring they not only meet but exceed the exacting standards of enterprise-level deployments. By adopting this holistic evaluation approach, enterprises can fully harness the transformative power of generative AI applications.
Sonnet currently ranks at the top of S&P AI Benchmarks by Kensho , which assesses large language models (LLMs) for finance and business. For example, there could be leakage of benchmark datasets’ questions and answers into training data. Anthropic Claude 3.5 Kensho is the AI Innovation Hub for S&P Global. Anthropic Claude 3.5
Amazon Bedrock , a fully managed service offering high-performing foundation models from leading AI companies through a single API, has recently introduced two significant evaluation capabilities: LLM-as-a-judge under Amazon Bedrock Model Evaluation and RAG evaluation for Amazon Bedrock Knowledge Bases. 0]}-{evaluator_model.split('.')[0]}-{datetime.now().strftime('%Y-%m-%d-%H-%M-%S')}"
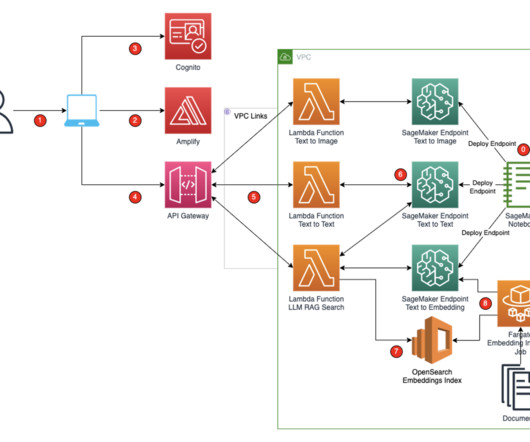
In this post, we build a secure enterprise application using AWS Amplify that invokes an Amazon SageMaker JumpStart foundation model, Amazon SageMaker endpoints, and Amazon OpenSearch Service to explain how to create text-to-text or text-to-image and Retrieval Augmented Generation (RAG). You access the React application from your computer.
This integration provides a powerful multilingual model that excels in reasoning benchmarks. The integration offers enterprise-grade features including model evaluation metrics, fine-tuning and customization capabilities, and collaboration tools, all while giving customers full control of their deployment.
In this post, we describe the enhancements to the forecasting capabilities of SageMaker Canvas and guide you on using its user interface (UI) and AutoML APIs for time-series forecasting. While the SageMaker Canvas UI offers a code-free visual interface, the APIs empower developers to interact with these features programmatically.
The technical sessions covering generative AI are divided into six areas: First, we’ll spotlight Amazon Q , the generative AI-powered assistant transforming software development and enterprise data utilization. Learn how Toyota utilizes analytics to detect emerging themes and unlock insights used by leaders across the enterprise.
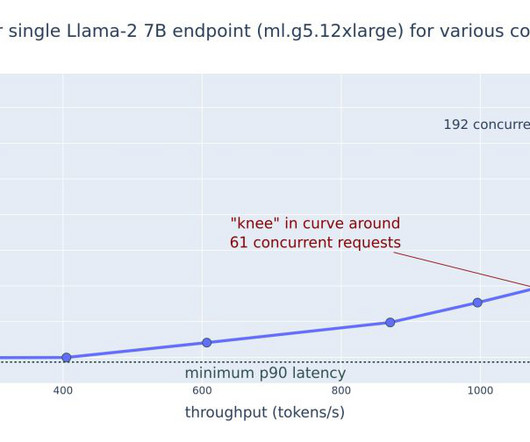
This post explores these relationships via a comprehensive benchmarking of LLMs available in Amazon SageMaker JumpStart, including Llama 2, Falcon, and Mistral variants. We provide theoretical principles on how accelerator specifications impact LLM benchmarking. Additionally, models are fully sharded on the supported instance.
Performance metrics and benchmarks According to Mistral, the instruction-tuned version of the model achieves over 81% accuracy on Massive Multitask Language Understanding (MMLU) with 150 tokens per second latency, making it currently the most efficient model in its category. It doesnt support Converse APIs or other Amazon Bedrock tooling.
These include metrics such as ROUGE or cosine similarity for text similarity, and specific benchmarks for assessing toxicity (Detoxify), prompt stereotyping (cross-entropy loss), or factual knowledge (HELM, LAMA). Refer to Getting started with the API to set up your environment to make Amazon Bedrock requests through the AWS API.
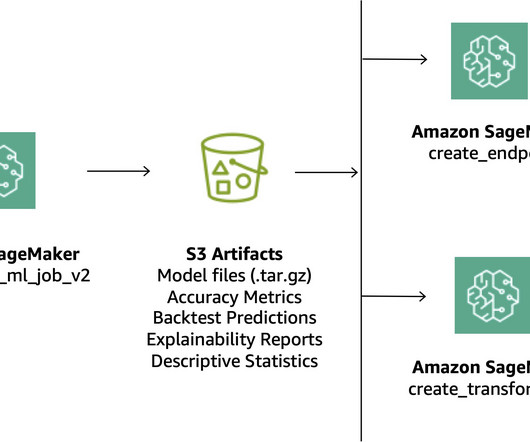
As enterprise businesses embrace machine learning (ML) across their organizations, manual workflows for building, training, and deploying ML models tend to become bottlenecks to innovation. Building an MLOps foundation that can cover the operations, people, and technology needs of enterprise customers is challenging.
A common way to select an embedding model (or any model) is to look at public benchmarks; an accepted benchmark for measuring embedding quality is the MTEB leaderboard. The Massive Text Embedding Benchmark (MTEB) evaluates text embedding models across a wide range of tasks and datasets.
a low-code enterprise graph machine learning (ML) framework to build, train, and deploy graph ML solutions on complex enterprise-scale graphs in days instead of months. Enterprise graphs can require terabytes of memory storage, requiring graph ML scientists to build complex training pipelines. GraphStorm 0.1
For more information about Jamba-Instruct, including relevant benchmarks, refer to Built for the Enterprise: Introducing AI21’s Jamba-Instruct Model. Programmatic access You can also access Jamba-Instruct through an API, using Amazon Bedrock and AWS SDK for Python (Boto3).
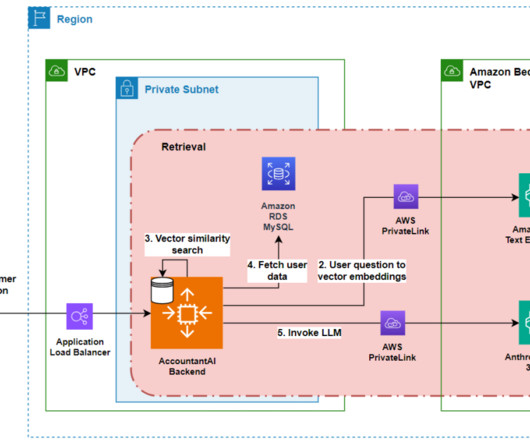
Small business proprietors tend to prioritize the operational aspects of their enterprises over administrative tasks, such as maintaining financial records and accounting. The ingestion workflow transforms these curated questions into vector embeddings using Amazon Titan Text Embeddings model API.
If youre a large enterprise with a team of analysts and a six-figure budget, it might be perfect. Best For Enterprise teams (especially in finance or hospitality) that need visibility into the full customer journey and fast insights from multiple touchpoints. Qualtrics is the industry standard for customer experience surveys.
Snowflake Arctic is a family of enterprise-grade large language models (LLMs) built by Snowflake to cater to the needs of enterprise users, exhibiting exceptional capabilities (as shown in the following benchmarks ) in SQL querying, coding, and accurately following instructions. To learn more, refer to API documentation.
Jina Embeddings v2 is the preferred choice for experienced ML scientists for the following reasons: State-of-the-art performance – We have shown on various text embedding benchmarks that Jina Embeddings v2 models excel on tasks such as classification, reranking, summarization, and retrieval.
With such a rise in popularity of mobile usage around the world, we are delighted to announce that from February 2020, our customers will be able to test the sending of an SMS message to a destination specified by them, via the Spearline API. Access real-time reporting and analytics via Spearline API polling. WORKING TOGETHER. 'Patrick'
To build an enterprise solution, developer resources, cost, time and user-experience have to be balanced to achieve the desired business outcome. You can save time, money, and labor by implementing classifications in your workflow, and documents go to downstream applications and APIs based on document type.
Although you can integrate the model directly into an application, the approach that works well for production-grade applications is to deploy the model behind an endpoint and then invoke the endpoint via a RESTful API call to obtain the inference. However, you can use any other benchmarking tool. large two-core machine.
Use APIs and middleware to bridge gaps between CPQ and existing enterprise systems, ensuring smooth data flow. Apply multi-tier approvals for large enterprise deals, ensuring senior sales leaders can intervene when necessary. Implement event-driven architecture where updates in CRM (e.g.,
Zeta Global is a leading data-driven, cloud-based marketing technology company that empowers enterprises to acquire, grow and retain customers. Together, these AI-driven tools and technologies aren’t just reshaping how brands perform marketing tasks; they’re setting new benchmarks for what’s possible in customer engagement.
In addition, deployments are now as simple as calling Boto3 SageMaker APIs and attaching the proper auto scaling policies. We already had an API layer on top of our models for model management and inference. In keeping with the instance types we were already using, we did our benchmarking with ml.g4dn.xlarge and ml.g4dn.2xlarge
When applying these approaches, we discuss key considerations around potential hallucination, integration with enterprise data, output quality, and cost. Their research indicates that zero-shot CoT, using the same single-prompt template, significantly outperforms zero-shot FM performances on diverse benchmark reasoning tasks.
In this post, we provide a step-by-step guide for creating an enterprise ready RAG application such as a question answering bot. On Hugging Face, the Massive Text Embedding Benchmark (MTEB) is provided as a leaderboard for diverse text embedding tasks. We use the Llama3-8B FM for text generation and the BGE Large EN v1.5
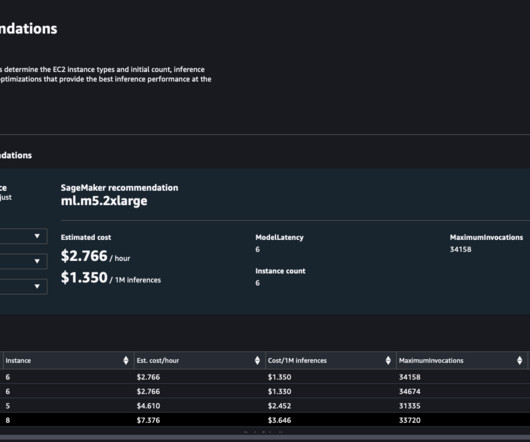
An advanced job is a custom load test job that allows you to perform extensive benchmarks based on your ML application SLA requirements, such as latency, concurrency, and traffic pattern. Inference Recommender uses this information to run a performance benchmark load test. Running Advanced job. sm_client = boto3.client("sagemaker",
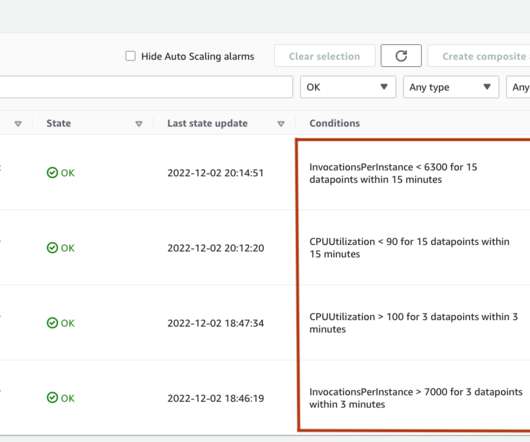
When ML models deployed on instances receive API calls from a large number of clients, a random distribution of requests can work very well when there is not a lot of variability in your requests and responses. The endpoint uniformly distributes incoming requests to ML instances using a round-robin algorithm.
In terms of resulting speedups, the approximate order is programming hardware, then programming against PBA APIs, then programming in an unmanaged language such as C++, then a managed language such as Python. The CUDA API and SDK were first released by NVIDIA in 2007. GPU PBAs, 4% other PBAs, 4% FPGA, and 0.5%
This is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading artificial intelligence (AI) companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon through a single API. A modern healthcare data strategy enables the curation and indexing of enterprise data.
Establishing customer trust and loyalty is the single most important aspect of customer experience, according to the Dimension Data 2019 Global Customer Experience Benchmarking Report. When we speak of Customer Experience (CX) and strategies for improving it, we need to clearly define the inherent business value.
In addition, they use the developer-provided instruction to create an orchestration plan and then carry out the plan by invoking company APIs and accessing knowledge bases using Retrieval Augmented Generation (RAG) to provide an answer to the user’s request. In Part 1, we focus on creating accurate and reliable agents.
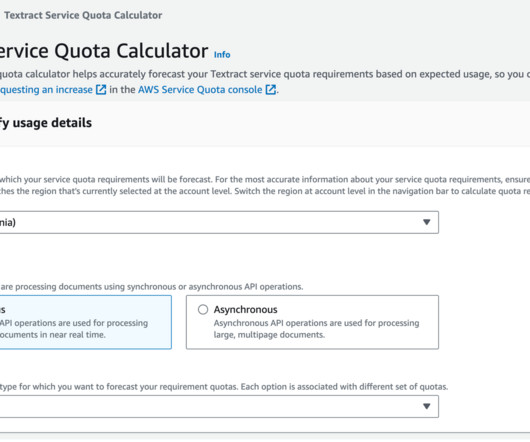
Split documents into single pages for specific FeatureType processing – FeatureType is a parameter for the Document Analysis API calls (both synchronous and asynchronous ) in Amazon Textract. Brijesh Pati is an Enterprise Solutions Architect at AWS. Amazon Textract charges based on the number of pages and images processed.
Pricing for enterprises and businesses: Custom pricing. (c) Enterprise plan at custom prices. (e) Create actionable industry benchmarks spread over the industry, touchpoint, or channels. With Trustpilot’s API, customize review invitations via chat, QR code, and more. Enterprise plan is available with custom pricing. (d)
In this blog post, we will introduce how to use an Amazon EC2 Inf2 instance to cost-effectively deploy multiple industry-leading LLMs on AWS Inferentia2 , a purpose-built AWS AI chip, helping customers to quickly test and open up an API interface to facilitate performance benchmarking and downstream application calls at the same time.
Autotune uses best practices as well as internal benchmarks for selecting the appropriate ranges. Raviteja Yelamanchili is an Enterprise Solutions Architect with Amazon Web Services based in New York. Using the previous example, the hyperparameters that Autotune can choose to be tunable are lr and batch-size.
We compile the UNet for one batch (by using input tensors with one batch), then use the torch_neuronx.DataParallel API to load this single batch model onto each core. Load the UNet model onto two Neuron cores using the torch_neuronx.DataParallel API. Create the SageMaker endpoint We use Boto3 APIs to create a SageMaker endpoint.
Amazon Bedrock is a fully managed service that makes foundation models (FMs) from leading artificial intelligence (AI) startups and Amazon available through an API, so you can choose from a wide range of FMs to find the model that is best suited for your use case.
At the time of this writing, it supports PyTorch and includes 25 techniques—called methods in the MosaicML world—along with standard models, datasets, and benchmarks. Speedup techniques implemented in Composer can be accessed with its functional API. Composer is available via pip : pip install mosaicml.
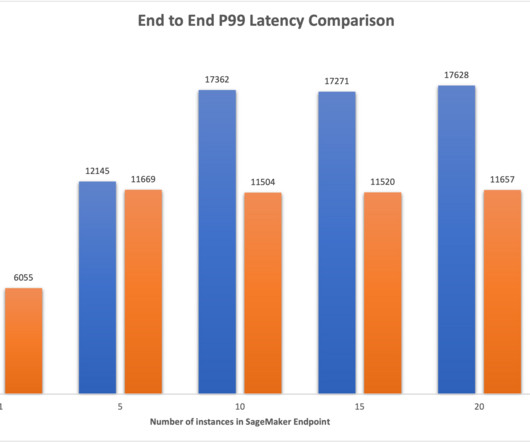
Furthermore, we benchmark the ResNet50 model and see the performance benefits that ONNX provides when compared to PyTorch and TensorRT versions of the same model, using the same input. The testing benchmark results are as follows: PyTorch – 176 milliseconds, cold start 6 seconds TensorRT – 174 milliseconds, cold start 4.5 seconds to 1.61
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content