This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Using its enterprise software, FloTorch conducted an extensive comparison between Amazon Nova models and OpenAIs GPT-4o models with the Comprehensive Retrieval Augmented Generation (CRAG) benchmark dataset. The following table provides example questions with their domain and question type.
Overview of Pixtral 12B Pixtral 12B, Mistrals inaugural VLM, delivers robust performance across a range of benchmarks, surpassing other open models and rivaling larger counterparts, according to Mistrals evaluation. Performance metrics and benchmarks Pixtral 12B is trained to understand both natural images and documents, achieving 52.5%
adds new APIs to customize GraphStorm pipelines: you now only need 12 lines of code to implement a custom node classification training loop. To help you get started with the new API, we have published two Jupyter notebook examples: one for node classification, and one for a link prediction task. Specifically, GraphStorm 0.3
Amazon Bedrock , a fully managed service offering high-performing foundation models from leading AI companies through a single API, has recently introduced two significant evaluation capabilities: LLM-as-a-judge under Amazon Bedrock Model Evaluation and RAG evaluation for Amazon Bedrock Knowledge Bases. 0]}-{evaluator_model.split('.')[0]}-{datetime.now().strftime('%Y-%m-%d-%H-%M-%S')}"
Sonnet currently ranks at the top of S&P AI Benchmarks by Kensho , which assesses large language models (LLMs) for finance and business. For example, there could be leakage of benchmark datasets’ questions and answers into training data. Anthropic Claude 3.5 Kensho is the AI Innovation Hub for S&P Global.
For example, a prompt that generates 100 tokens in one model might generate 150 tokens in another. Consider benchmarking your user experience to find the best latency for your use case, considering that most humans cant read faster than 225 words per minute and therefore extremely fast response can hinder user experience.
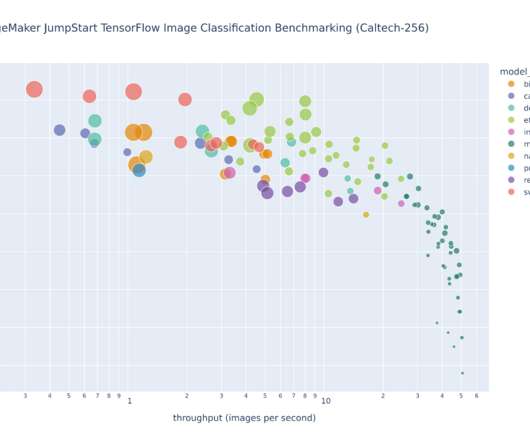
This post explores these relationships via a comprehensive benchmarking of LLMs available in Amazon SageMaker JumpStart, including Llama 2, Falcon, and Mistral variants. We provide theoretical principles on how accelerator specifications impact LLM benchmarking. Additionally, models are fully sharded on the supported instance.
We also showcase a real-world example for predicting the root cause category for support cases. For the use case of labeling the support root cause categories, its often harder to source examples for categories such as Software Defect, Feature Request, and Documentation Improvement for labeling than it is for Customer Education.
As an example, time-series forecasting allows retailers to predict future sales demand and plan for inventory levels, logistics, and marketing campaigns. In this post, we describe the enhancements to the forecasting capabilities of SageMaker Canvas and guide you on using its user interface (UI) and AutoML APIs for time-series forecasting.
Performance metrics and benchmarks According to Mistral, the instruction-tuned version of the model achieves over 81% accuracy on Massive Multitask Language Understanding (MMLU) with 150 tokens per second latency, making it currently the most efficient model in its category. It doesnt support Converse APIs or other Amazon Bedrock tooling.
Here are some examples of these metrics: Retrieval component Context precision Evaluates whether all of the ground-truth relevant items present in the contexts are ranked higher or not. For example, metrics like Answer Relevancy and Faithfulness are typically scored on a scale from 0 to 1.
For example, a technician could query the system about a specific machine part, receiving both textual maintenance history and annotated images showing wear patterns or common failure points, enhancing their ability to diagnose and resolve issues efficiently. has 92% accuracy on the HumanEval code benchmark.
Amazon Bedrock is a fully managed service that makes FMs from leading AI startups and Amazon available through an API, so you can choose from a wide range of FMs to find the model that is best suited for your use case. Solution overview The solution comprises two main steps: Generate synthetic data using the Amazon Bedrock InvokeModel API.
This integration provides a powerful multilingual model that excels in reasoning benchmarks. Use the notebook examples to start your deployment using SageMaker to create the model, configure the endpoint, and deploy the model, and AWS will handle the orchestration of resources, networking, and scaling as needed. or Mixtral.
Hear from customer speakers with real-world examples of how they’ve used data to support a variety of use cases, including generative AI, to create unique customer experiences. Explore examples to estimate the severity and likelihood of potential events that could be harmful.
We published a follow-up post on January 31, 2024, and provided code examples using AWS SDKs and LangChain, showcasing a Streamlit semantic search app. For example, in a recommendation system for a large ecommerce platform, a modest increase in recommendation accuracy could translate into significant additional revenue.
They enable applications requiring very low latency or local data processing using familiar APIs and tool sets. Through comparative benchmarking tests, we illustrate how deploying FMs in Local Zones closer to end users can significantly reduce latencya critical factor for real-time applications such as conversational AI assistants.
Example use cases for Jamba-Instruct Jamba-Instruct’s long context length is particularly well-suited for complex Retrieval Augmented Generation (RAG) workloads, or potentially complex document analysis. For example: You are a curious and novel researcher, who is highly interested in getting all the relevant information on a specific topic.
You can also either use the SageMaker Canvas UI, which provides a visual interface for building and deploying models without needing to write any code or have any ML expertise, or use its automated machine learning (AutoML) APIs for programmatic interactions.
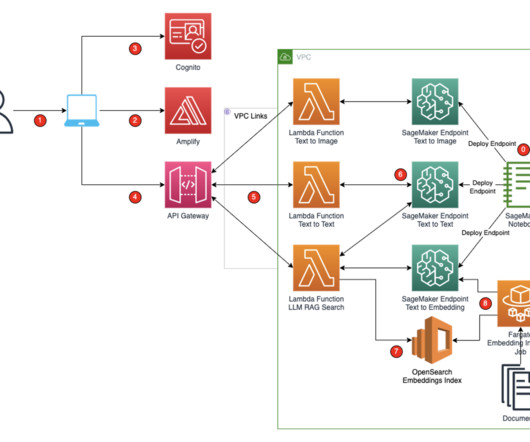
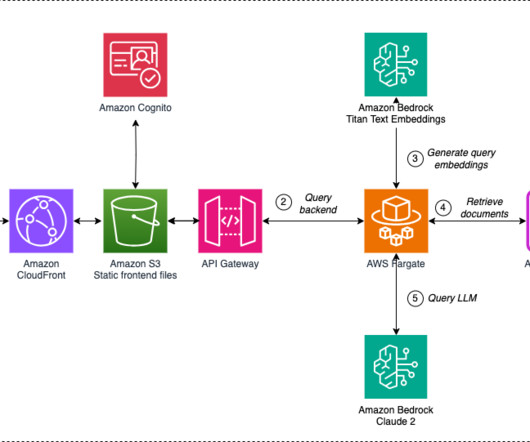
These SageMaker endpoints are consumed in the Amplify React application through Amazon API Gateway and AWS Lambda functions. To protect the application and APIs from inadvertent access, Amazon Cognito is integrated into Amplify React, API Gateway, and Lambda functions. For this example, we use train.cc_casebooks.jsonl.xz
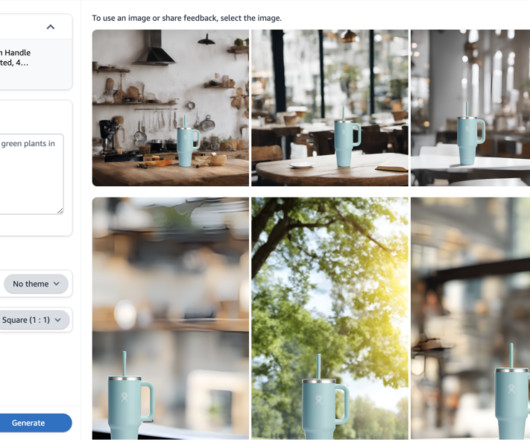
For example, an advertiser might have static images of their product against a white background. An example from the image generation solution showing a hydro flask with various backgrounds. Acting as a model hub, JumpStart provided a large selection of foundation models and the team quickly ran their benchmarks on candidate models.
You can see that for the 45 models we benchmarked, there is a 1.35x latency improvement (geomean for the 45 models). You can see that for the 33 models we benchmarked, there is around 2x performance improvement (geomean for the 33 models). We benchmarked 45 models using the scripts from the TorchBench repo.
SageMaker makes it easy to deploy models into production directly through API calls to the service. It’s a low-level API available for Java, C++, Go, JavaScript, Node.js, PHP, Ruby, and Python. It’s a low-level API available for Java, C++, Go, JavaScript, Node.js, PHP, Ruby, and Python.
Although you can integrate the model directly into an application, the approach that works well for production-grade applications is to deploy the model behind an endpoint and then invoke the endpoint via a RESTful API call to obtain the inference. However, you can use any other benchmarking tool. This value range is 0–100%.
In this example figure, features are extracted from raw historical data, which are then are fed into a neural network (NN). In terms of resulting speedups, the approximate order is programming hardware, then programming against PBA APIs, then programming in an unmanaged language such as C++, then a managed language such as Python.
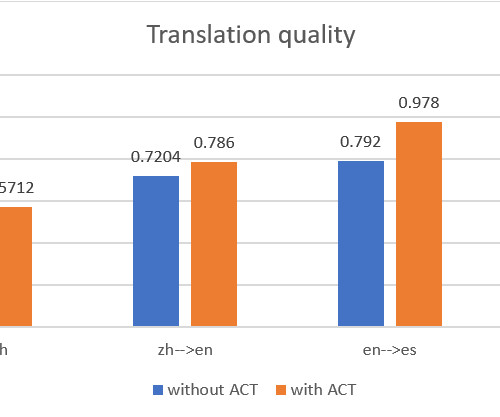
It features interactive Jupyter notebooks with self-contained code in PyTorch, JAX, TensorFlow, and MXNet, as well as real-world examples, exposition figures, and math. ACT allows you to customize translation output on the fly by providing tailored translation examples in the form of parallel data.
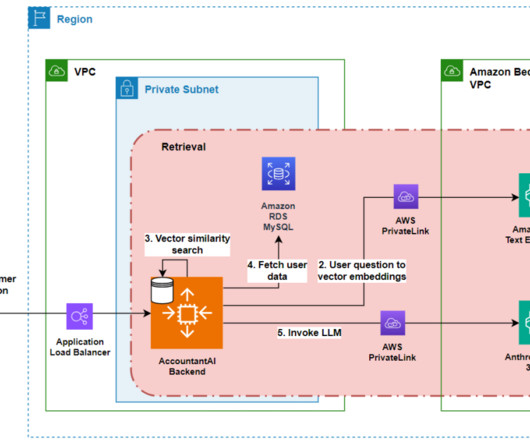
The ingestion workflow transforms these curated questions into vector embeddings using Amazon Titan Text Embeddings model API. Example prompt template Provides context about the agent's role as Lili's AI assistant for financial questions and outlines the general guidelines applied to all queries. Provides details on Lili platform.
This is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading artificial intelligence (AI) companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon through a single API. A prompt has three main types of content: input, context, and examples.
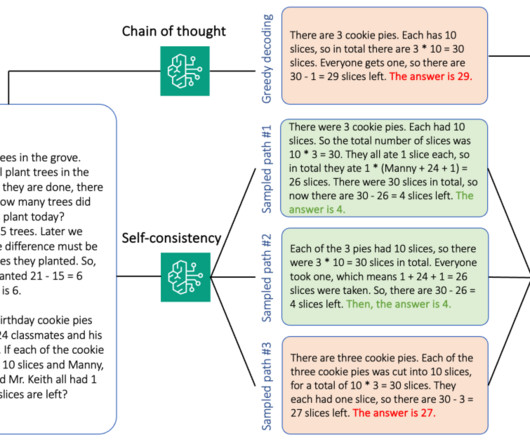
For example, chain-of-thought (CoT) is known to improve a model’s capacity for complex multi-step problems. With the batch inference API, you can use Amazon Bedrock to run inference with foundation models in batches and get responses more efficiently. The service is in preview as of this writing and only available through the API.
The solution uses the following services: Amazon API Gateway is a fully managed service that makes it easy for developers to publish, maintain, monitor, and secure APIs at any scale. Purina’s solution is deployed as an API Gateway HTTP endpoint, which routes the requests to obtain pet attributes.
The former question addresses model selection across model architectures, while the latter question concerns benchmarking trained models against a test dataset. This post provides details on how to implement large-scale Amazon SageMaker benchmarking and model selection tasks. swin-large-patch4-window7-224 195.4M efficientnet-b5 29.0M
Example questions might be “What are the restrictions for CMR substances?”, “How long do I need to keep the documents related to a toluene sale?”, The following screenshot shows an example of the conversational interface. or “What is the reach characterization ratio and how do I calculate it?”
How to add your competitors’ public reviews to the mix, so you can get a reliable benchmark and win in the market. There are many ways to use the integration function, and this is just one example. Lumoa has very clear open APIs and based on your goals, integrations can serve various purposes.
Red-teaming engages human testers to probe an AI system for flaws in an adversarial style, and complements our other testing techniques, which include automated benchmarking against publicly available and proprietary datasets, human evaluation of completions against proprietary datasets, and more.
With such a rise in popularity of mobile usage around the world, we are delighted to announce that from February 2020, our customers will be able to test the sending of an SMS message to a destination specified by them, via the Spearline API. Access real-time reporting and analytics via Spearline API polling.
For example, in order to share expensive GPU resources between multiple models, we were responsible for allocating rigid memory fractions to models that were specified during deployment. In addition, deployments are now as simple as calling Boto3 SageMaker APIs and attaching the proper auto scaling policies.
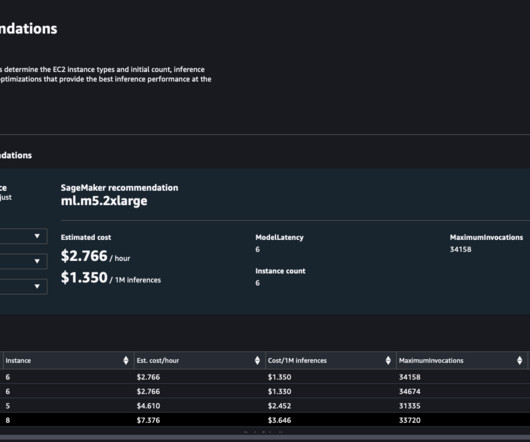
The team’s early benchmarking results show 7.3 The baseline model used in these benchmarking is a multi-layer perceptron neural network with seven dense fully connected layers and over 200 parameters. The following table summarizes the benchmarking result on ml.p3.16xlarge SageMaker training instances. Number of Instances.
The majority of data is non-fraudulent (284,315 samples), with only 492 samples corresponding to fraudulent examples. An advanced job is a custom load test job that allows you to perform extensive benchmarks based on your ML application SLA requirements, such as latency, concurrency, and traffic pattern. Running Advanced job.
It provides examples of use cases and best practices for using generative AI’s potential to accelerate sustainability and ESG initiatives, as well as insights into the main operational challenges of generative AI for sustainability. Figure 1 illustrates selected examples of use cases of generative AI for sustainability across the value chain.
Together, these AI-driven tools and technologies aren’t just reshaping how brands perform marketing tasks; they’re setting new benchmarks for what’s possible in customer engagement. From our experience, artifact server has some limitations, such as limits on artifact size (because of sending it using REST API).
On Hugging Face, the Massive Text Embedding Benchmark (MTEB) is provided as a leaderboard for diverse text embedding tasks. It currently provides 129 benchmarking datasets across 8 different tasks on 113 languages. medium instance to demonstrate deploying the model as an API endpoint using an SDK through SageMaker JumpStart.
Snowflake Arctic is a family of enterprise-grade large language models (LLMs) built by Snowflake to cater to the needs of enterprise users, exhibiting exceptional capabilities (as shown in the following benchmarks ) in SQL querying, coding, and accurately following instructions. To learn more, refer to API documentation.
For example, 8 V100 GPUs (32GB each) are sufficient to hold the model states replica of a 10B-parameter model which needs about 200GB of memory when training with Adam optimizer using mixed-precision. To get started, follow Modify a PyTorch Training Script to adapt SMPs’ APIs in your training script. Benchmarking performance.
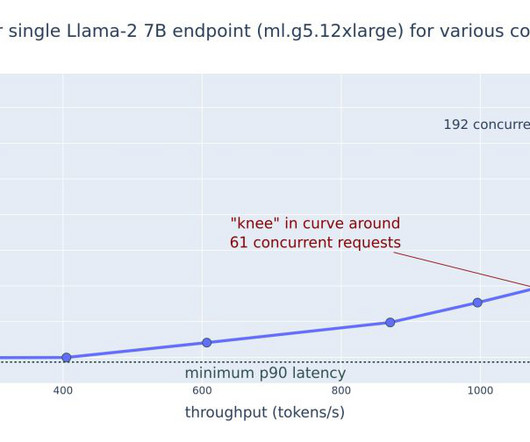
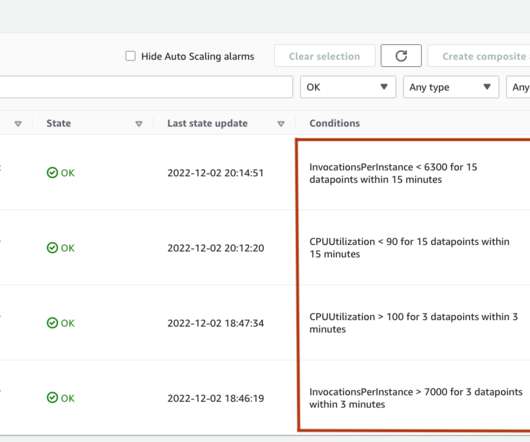
We first benchmark the performance of our model on a single instance to identify the TPS it can handle per our acceptable latency requirements. The entire set of code for the example is available in the following GitHub repository. Overview of solution. For CPUUtilization , you may see percentages above 100% at first in CloudWatch.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content