This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Overview of Pixtral 12B Pixtral 12B, Mistrals inaugural VLM, delivers robust performance across a range of benchmarks, surpassing other open models and rivaling larger counterparts, according to Mistrals evaluation. Performance metrics and benchmarks Pixtral 12B is trained to understand both natural images and documents, achieving 52.5%
adds new APIs to customize GraphStorm pipelines: you now only need 12 lines of code to implement a custom node classification training loop. Based on customer feedback for the experimental APIs we released in GraphStorm 0.2, introduces refactored graph ML pipeline APIs. Specifically, GraphStorm 0.3 GraphStorm 0.3
Amazon Bedrock , a fully managed service offering high-performing foundation models from leading AI companies through a single API, has recently introduced two significant evaluation capabilities: LLM-as-a-judge under Amazon Bedrock Model Evaluation and RAG evaluation for Amazon Bedrock Knowledge Bases. 0]}-{evaluator_model.split('.')[0]}-{datetime.now().strftime('%Y-%m-%d-%H-%M-%S')}"
This includes virtual assistants where users expect immediate feedback and near real-time interactions. At the time of writing this post, you can use the InvokeModel API to invoke the model. It doesnt support Converse APIs or other Amazon Bedrock tooling. You can quickly test the model in the playground through the UI.
Amazon Bedrock is a fully managed service that offers a choice of high-performing Foundation Models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon via a single API, along with a broad set of capabilities you need to build generative AI applications with security, privacy, and responsible AI.
In-app feedback tools help businesses to collect real-time customer feedback , which is essential for a thriving business strategy. In-App feedback mechanisms are convenient, which allow users to share their concerns without disrupting their mobile app experience. What is an In-App Feedback Survey? Include a Progress Bar.
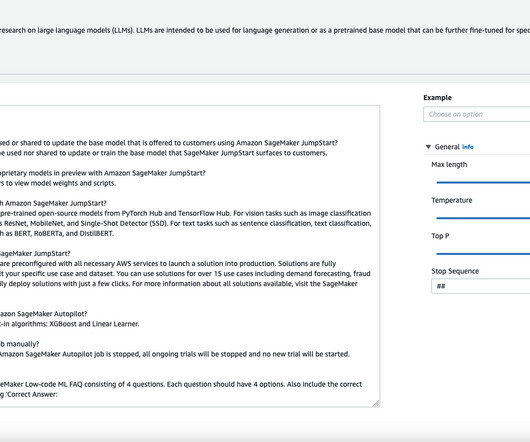
Acting as a model hub, JumpStart provided a large selection of foundation models and the team quickly ran their benchmarks on candidate models. The workflow allowed the Amazon Ads team to experiment with different foundation models and configurations through blind A/B testing to ensure that feedback to the generated images is unbiased.
Automated API testing stands as a cornerstone in the modern software development cycle, ensuring that applications perform consistently and accurately across diverse systems and technologies. Continuous learning and adaptation are essential, as the landscape of API technology is ever-evolving.
Examples of tools you can use to advance sustainability initiatives are: Amazon Bedrock – a fully managed service that provides access to high-performing FMs from leading AI companies through a single API, enabling you to choose the right model for your sustainability use cases.
With such a rise in popularity of mobile usage around the world, we are delighted to announce that from February 2020, our customers will be able to test the sending of an SMS message to a destination specified by them, via the Spearline API. Access real-time reporting and analytics via Spearline API polling. UI REDESIGN.
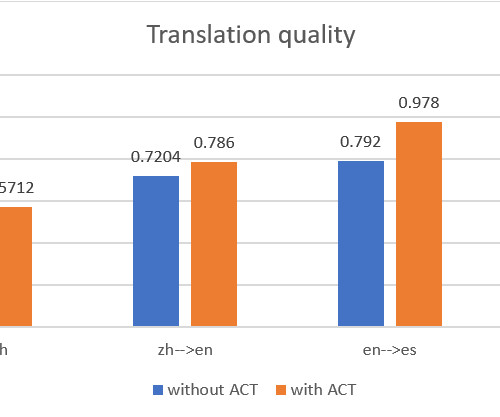
We demonstrate how to use the AWS Management Console and Amazon Translate public API to deliver automatic machine batch translation, and analyze the translations between two language pairs: English and Chinese, and English and Spanish. In this post, we present a solution that D2L.ai
Use APIs and middleware to bridge gaps between CPQ and existing enterprise systems, ensuring smooth data flow. Automate Price Calculations and Adjustments Utilize real-time pricing engines within CPQ to dynamically calculate prices based on market trends, cost fluctuations, and competitor benchmarks.
Summarize thousands of feedback with just one click Use the power of AI to save time and stress Safe and secure – none of your data will be stored anywhere outside of Lumoa If you want to also get access to the new GPT functionality, and be on the waitlist for cutting edge features, contact your CS manager or help@lumoa.me
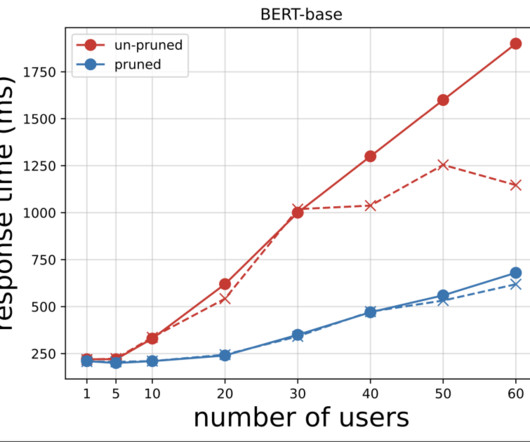
Now, let’s look at latency and throughput performance benchmarking for model serving with the default JumpStart deployment configuration. For more information on how to consider this information and adjust deployment configurations for your specific use case, see Benchmark and optimize endpoint deployment in Amazon SageMaker JumpStart.
You can save time, money, and labor by implementing classifications in your workflow, and documents go to downstream applications and APIs based on document type. This helps you avoid throttling limits on API calls due to polling the Get* APIs. A common approach is using service logs to understand different levels of accuracy.
testingRTC creates faster feedback loops from development to testing. And testingRTC offers multiple ways to export these metrics, from direct collection from webhooks, to downloading results in CSV format using the REST API. Let’s take a look. testingRTC is created specifically for WebRTC. Happy days!
Built on AWS with asynchronous processing, the solution incorporates multiple quality assurance measures and is continually refined through a comprehensive feedback loop, all while maintaining stringent security and privacy standards. As new models become available on Amazon Bedrock, we have a structured evaluation process in place.
In addition, they use the developer-provided instruction to create an orchestration plan and then carry out the plan by invoking company APIs and accessing knowledge bases using Retrieval Augmented Generation (RAG) to provide an answer to the user’s request. In Part 1, we focus on creating accurate and reliable agents.
Banking giant ING recently switched from an Avaya call center to a system built internally using Twilio APIs. Understanding Industry Benchmarks. Making the Most of Customer Feedback. See Five9 Preps for Digital Era. Twilio is gaining ground as an alternative to “traditional” vendors. More Reading. Know What Makes Customers Tick.
In this blog post, we will introduce how to use an Amazon EC2 Inf2 instance to cost-effectively deploy multiple industry-leading LLMs on AWS Inferentia2 , a purpose-built AWS AI chip, helping customers to quickly test and open up an API interface to facilitate performance benchmarking and downstream application calls at the same time.
Although existing large language model (LLM) benchmarks like MT-bench evaluate model capabilities, they lack the ability to validate the application layers. Evaluator considerations By default, evaluators use the InvokeModel API with On-Demand mode, which will incur AWS charges based on input tokens processed and output tokens generated.
Response times across digital channels require different benchmarks: Live chat : 30 seconds or less Email : Under 4 hours Social media : Within 60 minutes Agent performance metrics should balance efficiency with quality. Scorecards combining AHT, FCR, and customer satisfaction create well-rounded performance measurement.
Two key distinctions are the low altitude, oblique perspective of the imagery and disaster-related features, which are rarely featured in computer vision benchmarks and datasets. Give it a whirl and let us know how this solved your use case by leaving feedback in the comments section. Applied AI Specialist Architect at AWS.
Those Users that the Stakeholders trust for unvarnished feedback should have enough hands-on experience to be able to provide meaningful feedback. Pointillist can handle data in all forms, whether it is in tables, excel files, server logs, or 3rd party APIs. Success Metrics for the Project. Getting Data into Pointillist.
Furthermore, we benchmark the ResNet50 model and see the performance benefits that ONNX provides when compared to PyTorch and TensorRT versions of the same model, using the same input. The testing benchmark results are as follows: PyTorch – 176 milliseconds, cold start 6 seconds TensorRT – 174 milliseconds, cold start 4.5 seconds to 1.61
If we’re looking to roll out to an entire team, then we look to more of those API pushes and how we connect one tool to another. . I prefer NPS, but again, it doesn’t matter what method you use to try to incite feedback; it matters if you take action on that insight. It doesn’t provide any real feedback loop there.
At the time of this writing, it supports PyTorch and includes 25 techniques—called methods in the MosaicML world—along with standard models, datasets, and benchmarks. Speedup techniques implemented in Composer can be accessed with its functional API. Composer is available via pip : pip install mosaicml.
For a complete description of Jurassic-1, including benchmarks and quantitative comparisons with other models, refer to the following technical paper. Request access, try out the foundation model in SageMaker today and let us know your feedback! About the authors. Tomer Asida is an algo team lead at AI21 Labs.
In addition, Ventana Research , the leading benchmark research and business technology advisory services firm, named us as a Value Index Leader in the first Ventana Research Value Index for Contact Centres in the Cloud. Alongside these accolades, 2018 saw us appoint previous Aspect President, Chris Koziol, to President and CEO of the company.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
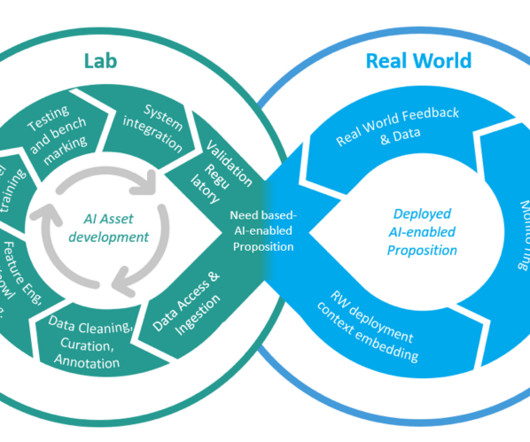
The real-world performance and feedback are eventually used for further model improvements with full automation of the model training and deployment. Enable a data science team to manage a family of classic ML models for benchmarking statistics across multiple medical units. Once deployed, model performance is continuously monitored.
An API (Application Programming Interface) will enhance your utilisation of our platform. Our RESTful API provides your developers with the ability to create campaigns, add numbers, time groups, export data for every test run, every day, every hour, every minute if that’s what you need to put your arms around your business.
One example is an online retailer who deploys a large number of inference endpoints for text summarization, product catalog classification, and product feedback sentiment classification. We use the Recognizing Textual Entailment dataset from the GLUE benchmarking suite. training.py ).
As noted in the 2019 Dimension Data Customer Experience (CX) Benchmarking report: 88% of contact center decision-makers expect self-service volumes to increase over the next 12 months. These interactions will become longer – so traditional productivity measurements and benchmarks will no longer be relevant and will have to be redefined.
They can optimize and monitor the performance of their team with real-time customizable API based wallboards and dashboards. After all, real-time reporting and benchmarking features can assist contact centers in growing their business. Benefits of Real-Time Monitoring. This way it leads to employee workflow effectiveness.
In 2018, BERT-large made its debut with its 340 million parameters and innovative transformer architecture, setting the benchmark for performance on NLP tasks. The endpoint comes pre-loaded with the model and ready to serve queries via an easy-to-use API and Python SDK, so you can hit the ground running.
Abandonment Rates A recent survey reported average abandonment rates between five percent and eight percent, with the benchmark for healthcare being at nearly seven percent. First Contact Resolution Rate The healthcare industry benchmark for first contact resolution ( FCR ) rate in healthcare is 71 percent.
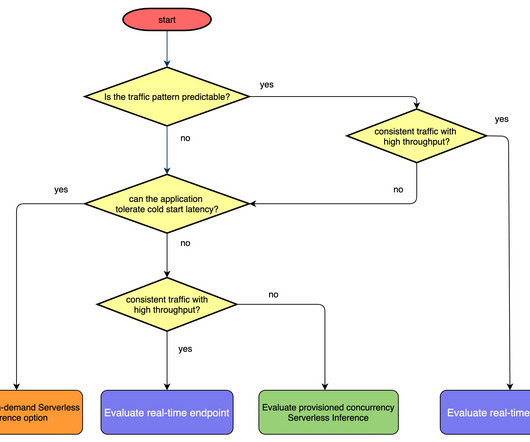
You can then use that text file when invoking the AWS Command Line Interface (AWS CLI) or the Application Auto Scaling API. SageMaker endpoint configuration – Create an endpoint configuration using the CreateEndpointConfig API and the new configuration ServerlessConfig options or by selecting the serverless option on the SageMaker console.
per user, per month Why Use Nextiva As An Alternative to Aircall Provides 360 Degree Feedback (complete customer view) as a feature that AirCall doesn’t. per user, per month Why Use Nextiva As An Alternative to Aircall Provides 360 Degree Feedback (complete customer view) as a feature that AirCall doesn’t. 5 Capterra– 4.4/5
Tasks such as routing support tickets, recognizing customers intents from a chatbot conversation session, extracting key entities from contracts, invoices, and other type of documents, as well as analyzing customer feedback are examples of long-standing needs. Customer feedback for Sunshine Spa, 123 Main St, Anywhere.
Feedback on JustCall from Real-World Users JustCall Pros JustCall Cons Easy to implement and use, with an incredible onboarding and training service. out of 5 stars Feedback on AirCall from Real-World Users AirCall Pros AirCall Cons Admins can easily add numbers from 100+ countries. on the connected CRM. G2 Rating: 4.2
Fortunately, technology has also brought us an open API. Quality assurance – Programs like EvaluAgent and Klaus let business owners view real-time information about calls, so they can offer feedback to sales or support agents quickly, while the call is still fresh in the agent’s mind. .
To learn how ChurnZero helps customers comply with privacy laws, check out our documentation on ChurnZero’s API for privacy laws compliance. Collect user feedback on your Customer Success software For your Customer Success software to deliver results, your team needs to use it – and preferably enjoy using it if you want long-term success.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















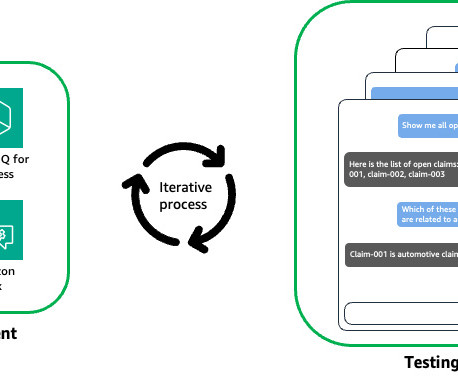

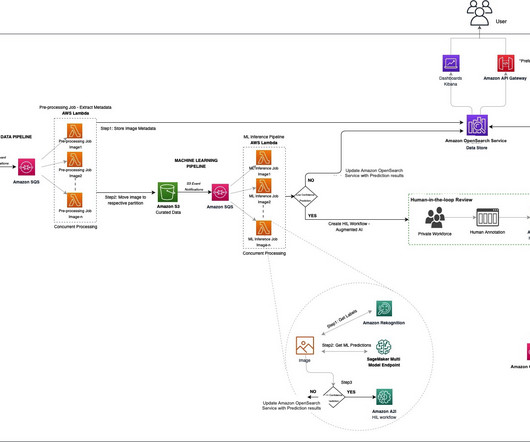

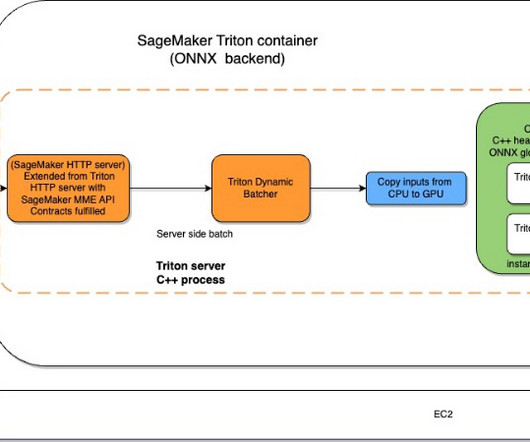




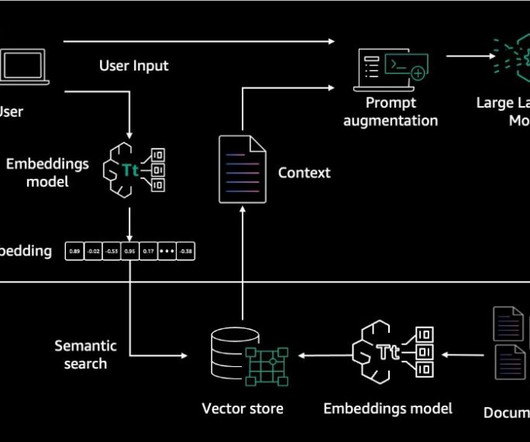


















Let's personalize your content