This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this post, we walk through how to discover, deploy, and use the Pixtral 12B model for a variety of real-world vision use cases. Performance metrics and benchmarks Pixtral 12B is trained to understand both natural images and documents, achieving 52.5% To begin using Pixtral 12B, choose Deploy.
adds new APIs to customize GraphStorm pipelines: you now only need 12 lines of code to implement a custom node classification training loop. For more details about how to run graph multi-task learning with GraphStorm, refer to Multi-task Learning in GraphStorm in our documentation. introduces refactored graph ML pipeline APIs.
This post explores these relationships via a comprehensive benchmarking of LLMs available in Amazon SageMaker JumpStart, including Llama 2, Falcon, and Mistral variants. We provide theoretical principles on how accelerator specifications impact LLM benchmarking. Additionally, models are fully sharded on the supported instance.
Amazon Bedrock , a fully managed service offering high-performing foundation models from leading AI companies through a single API, has recently introduced two significant evaluation capabilities: LLM-as-a-judge under Amazon Bedrock Model Evaluation and RAG evaluation for Amazon Bedrock Knowledge Bases. 0]}-{evaluator_model.split('.')[0]}-{datetime.now().strftime('%Y-%m-%d-%H-%M-%S')}"
As businesses increasingly use large language models (LLMs) for these critical tasks and processes, they face a fundamental challenge: how to maintain the quick, responsive performance users expect while delivering the high-quality outputs these sophisticated models promise. In such scenarios, you want to optimize for TTFT.
Amazon Bedrock is a fully managed service that offers a choice of high-performing Foundation Models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon via a single API, along with a broad set of capabilities you need to build generative AI applications with security, privacy, and responsible AI.
In this post, we describe the enhancements to the forecasting capabilities of SageMaker Canvas and guide you on using its user interface (UI) and AutoML APIs for time-series forecasting. While the SageMaker Canvas UI offers a code-free visual interface, the APIs empower developers to interact with these features programmatically.
We gave practical tips, based on hands-on experience with customer use cases, on how to improve text-only RAG solutions, from optimizing the retriever to mitigating and detecting hallucinations. We first introduce routers, and how they can help managing diverse data sources. has 92% accuracy on the HumanEval code benchmark.
In this post, we walk through how to discover, deploy, and use Mistral-Small-24B-Instruct-2501. At the time of writing this post, you can use the InvokeModel API to invoke the model. It doesnt support Converse APIs or other Amazon Bedrock tooling. In this section, we go over how to discover the models in SageMaker Studio.
Amazon Bedrock is a fully managed service that makes FMs from leading AI startups and Amazon available through an API, so you can choose from a wide range of FMs to find the model that is best suited for your use case. In this post, we explore how to use Amazon Bedrock to generate synthetic training data to fine-tune an LLM.
This integration provides a powerful multilingual model that excels in reasoning benchmarks. We’ll then dive into NVIDIA’s model offerings on SageMaker JumpStart, showcasing how to access and deploy the Nemotron-4 model directly in the JumpStart interface. or Mixtral.
In this talk, you’ll understand how to recognize the latest signals in changing data patterns, and adapt data strategies that flex to changes in consumer behavior and innovations in technology like AI. This session provides practical steps to streamline your model selection process, providing high-quality, reliable AI deployments.
We dive deep into this process on how to use XML tags to structure the prompt and guide Amazon Bedrock in generating a balanced label dataset with high accuracy. In the following sections, we explain how to take an incremental and measured approach to improve Anthropics Claude 3.5 Sonnet prediction accuracy through prompt engineering.
In this blog post, we show how we optimized torch.compile performance on AWS Graviton3-based EC2 instances, how to use the optimizations to improve inference performance, and the resulting speedups. You can see that for the 45 models we benchmarked, there is a 1.35x latency improvement (geomean for the 45 models).
They enable applications requiring very low latency or local data processing using familiar APIs and tool sets. This guide demonstrates how to deploy an open source FM from Hugging Face on Amazon Elastic Compute Cloud (Amazon EC2) instances across three locations: a commercial AWS Region and two AWS Local Zones.
You can also either use the SageMaker Canvas UI, which provides a visual interface for building and deploying models without needing to write any code or have any ML expertise, or use its automated machine learning (AutoML) APIs for programmatic interactions.
Recently, we organized a webinar about how to integrate public reviews using Lumoa where “that cool guy Garen” showed: How to bring public reviews in Lumoa within minutes. How to identify key pain points that you can immediately tackle to increase the score.
In this post, we discuss the benefits of the V2 model, how to conduct your own evaluation of the model, and how to migrate to using the new model. A common way to select an embedding model (or any model) is to look at public benchmarks; an accepted benchmark for measuring embedding quality is the MTEB leaderboard.
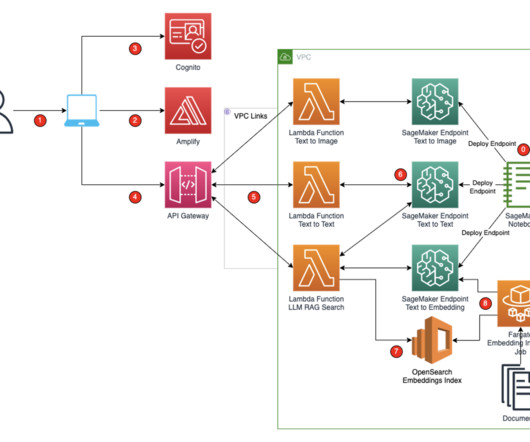
In this post, we build a secure enterprise application using AWS Amplify that invokes an Amazon SageMaker JumpStart foundation model, Amazon SageMaker endpoints, and Amazon OpenSearch Service to explain how to create text-to-text or text-to-image and Retrieval Augmented Generation (RAG). You access the React application from your computer.
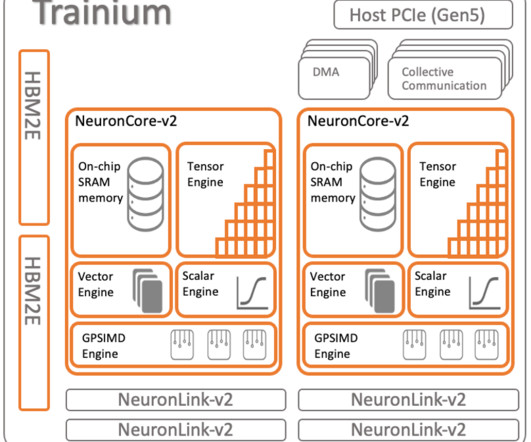
Similar to the process of PyTorch integration with C++ code, Neuron CustomOps requires a C++ implementation of an operator via a NeuronCore-ported subset of the Torch C++ API. Finally, the custom library is built by calling the load API. For more information, refer to Custom Operators API Reference Guide [Experimental].
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models from leading AI companies and Amazon via a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI. A limitation of the approach is its larger computational cost.
Although you can integrate the model directly into an application, the approach that works well for production-grade applications is to deploy the model behind an endpoint and then invoke the endpoint via a RESTful API call to obtain the inference. However, you can use any other benchmarking tool. large two-core machine.
Learning how to choose the best customer journey analytics platform is just the start. Whether you’re just starting to evaluate an investment in a customer journey analytics platform or you’ve already made the decision and have chosen a vendor, it’s time to think about how to implement customer journey analytics in your organization.
The ingestion workflow transforms these curated questions into vector embeddings using Amazon Titan Text Embeddings model API. Provides the core instructions on how to approach answering the question appropriately and meet expectations. The vector embeddings are persisted in the application in-memory vector store.
SageMaker makes it easy to deploy models into production directly through API calls to the service. It’s a low-level API available for Java, C++, Go, JavaScript, Node.js, PHP, Ruby, and Python. It’s a low-level API available for Java, C++, Go, JavaScript, Node.js, PHP, Ruby, and Python.
On Hugging Face, the Massive Text Embedding Benchmark (MTEB) is provided as a leaderboard for diverse text embedding tasks. It currently provides 129 benchmarking datasets across 8 different tasks on 113 languages. medium instance to demonstrate deploying the model as an API endpoint using an SDK through SageMaker JumpStart.
This is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading artificial intelligence (AI) companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon through a single API. It’s serverless, so you don’t have to manage any infrastructure.
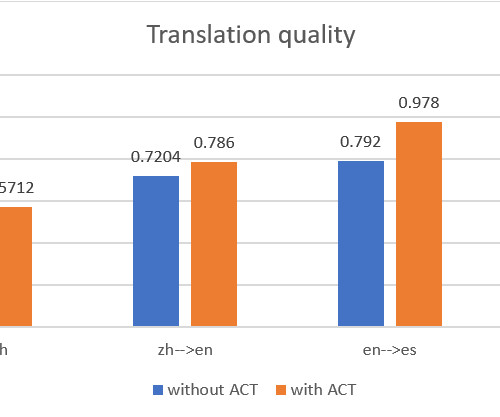
We demonstrate how to use the AWS Management Console and Amazon Translate public API to deliver automatic machine batch translation, and analyze the translations between two language pairs: English and Chinese, and English and Spanish. In this post, we present a solution that D2L.ai
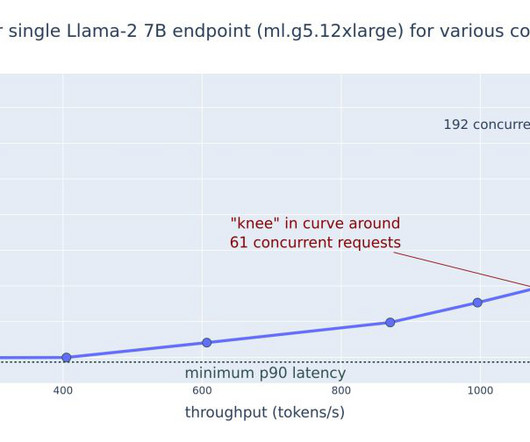
From there, we dive into how you can track and understand the metrics and performance of the SageMaker endpoint utilizing Amazon CloudWatch metrics. We first benchmark the performance of our model on a single instance to identify the TPS it can handle per our acceptable latency requirements. Deploy a real-time endpoint.
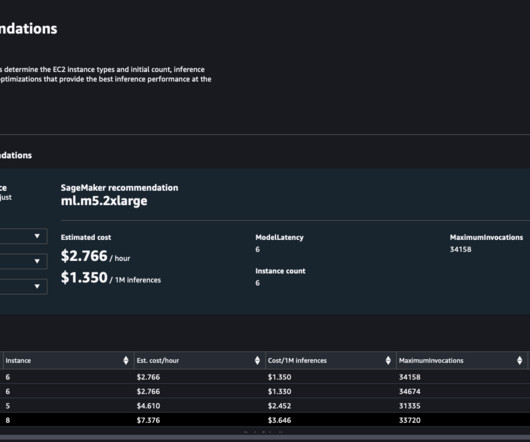
In this post, we discuss a credit card fraud detection use case, and learn how to use Inference Recommender to find the optimal inference instance type and ML system configurations that can detect fraudulent credit card transactions in milliseconds. Inference Recommender uses this information to run a performance benchmark load test.
During our webinar with G2, we shared how modern Customer Success teams maximize insights from customer reviews to drive recurring revenue, including how to: Know when a customer is most primed to leave a raving review – and how to perfectly time your ask. The easiest and fastest way is just an email alert.
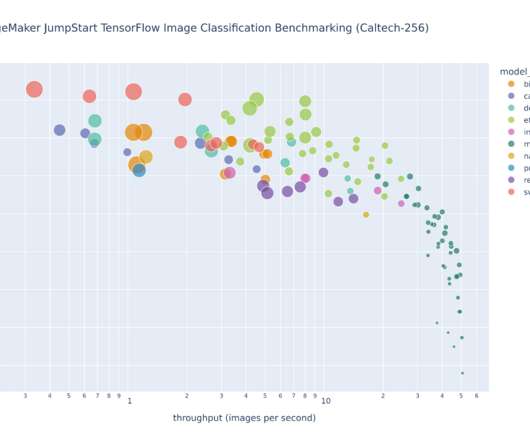
And an ML researcher may ask questions like: “How can I generate my own fair comparison of multiple model architectures against a specified dataset while controlling training hyperparameters and computer specifications, such as GPUs, CPUs, and RAM?” swin-large-patch4-window7-224 195.4M efficientnet-v2-imagenet21k-ft1k-l 118.1M
The team’s early benchmarking results show 7.3 The baseline model used in these benchmarking is a multi-layer perceptron neural network with seven dense fully connected layers and over 200 parameters. The following table summarizes the benchmarking result on ml.p3.16xlarge SageMaker training instances. Number of Instances.
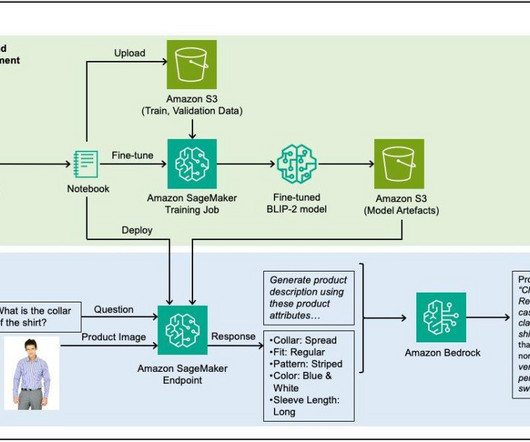
To solve this problem, this post shows you how to predict domain-specific product attributes from product images by fine-tuning a VLM on a fashion dataset using Amazon SageMaker , and then using Amazon Bedrock to generate product descriptions using the predicted attributes as input.
Amazon Bedrock is a fully managed service that makes foundation models (FMs) from leading artificial intelligence (AI) startups and Amazon available through an API, so you can choose from a wide range of FMs to find the model that is best suited for your use case.
In this post, we walk through how to discover and deploy the jina-embeddings-v2 model as part of a Retrieval Augmented Generation (RAG)-based question answering system in SageMaker JumpStart. Long input-context length – Jina Embeddings v2 models support 8,192 input tokens.
In terms of resulting speedups, the approximate order is programming hardware, then programming against PBA APIs, then programming in an unmanaged language such as C++, then a managed language such as Python. The CUDA API and SDK were first released by NVIDIA in 2007. GPU PBAs, 4% other PBAs, 4% FPGA, and 0.5%
Then, you’ll learn how to train a 30B parameter GPT-2 model on SageMaker with ease with this new feature. Let’s now learn how to train a GPT-2 model with sharded data parallel, with SMP encapsulating the complexity for you. To get started, follow Modify a PyTorch Training Script to adapt SMPs’ APIs in your training script.
In this blog post, we will introduce how to use an Amazon EC2 Inf2 instance to cost-effectively deploy multiple industry-leading LLMs on AWS Inferentia2 , a purpose-built AWS AI chip, helping customers to quickly test and open up an API interface to facilitate performance benchmarking and downstream application calls at the same time.
Although existing large language model (LLM) benchmarks like MT-bench evaluate model capabilities, they lack the ability to validate the application layers. Evaluator considerations By default, evaluators use the InvokeModel API with On-Demand mode, which will incur AWS charges based on input tokens processed and output tokens generated.
In the following sections, we discuss how to address common challenges in regards to technical focus areas. You can save time, money, and labor by implementing classifications in your workflow, and documents go to downstream applications and APIs based on document type.
When ML models deployed on instances receive API calls from a large number of clients, a random distribution of requests can work very well when there is not a lot of variability in your requests and responses. We explained how to enable LOR and how it can benefit your model deployments.
Then, we’ll revisit how to train foundational models using sharded data parallel. Finally, we’ll benchmark performance of 13B, 50B, and 100B parameter auto-regressive models and wrap up with future work. For training a different model type, you can follow the API document to learn about how to apply SMP APIs.
Snowflake Arctic is a family of enterprise-grade large language models (LLMs) built by Snowflake to cater to the needs of enterprise users, exhibiting exceptional capabilities (as shown in the following benchmarks ) in SQL querying, coding, and accurately following instructions. To learn more, refer to API documentation.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content