This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Using its enterprise software, FloTorch conducted an extensive comparison between Amazon Nova models and OpenAIs GPT-4o models with the Comprehensive Retrieval Augmented Generation (CRAG) benchmark dataset. How do Amazon Nova Micro and Amazon Nova Lite perform against GPT-4o mini in these same metrics?
This approach allows organizations to assess their AI models effectiveness using pre-defined metrics, making sure that the technology aligns with their specific needs and objectives. The introduction of an LLM-as-a-judge framework represents a significant step forward in simplifying and streamlining the model evaluation process.
Overview of Pixtral 12B Pixtral 12B, Mistrals inaugural VLM, delivers robust performance across a range of benchmarks, surpassing other open models and rivaling larger counterparts, according to Mistrals evaluation. Performance metrics and benchmarks Pixtral 12B is trained to understand both natural images and documents, achieving 52.5%
adds new APIs to customize GraphStorm pipelines: you now only need 12 lines of code to implement a custom node classification training loop. Based on customer feedback for the experimental APIs we released in GraphStorm 0.2, introduces refactored graph ML pipeline APIs. Specifically, GraphStorm 0.3 In addition, GraphStorm 0.3
To effectively optimize AI applications for responsiveness, we need to understand the key metrics that define latency and how they impact user experience. These metrics differ between streaming and nonstreaming modes and understanding them is crucial for building responsive AI applications.
Current RAG pipelines frequently employ similarity-based metrics such as ROUGE , BLEU , and BERTScore to assess the quality of the generated responses, which is essential for refining and enhancing the models capabilities. More sophisticated metrics are needed to evaluate factual alignment and accuracy.
Performance metrics and benchmarks According to Mistral, the instruction-tuned version of the model achieves over 81% accuracy on Massive Multitask Language Understanding (MMLU) with 150 tokens per second latency, making it currently the most efficient model in its category.
As new embedding models are released with incremental quality improvements, organizations must weigh the potential benefits against the associated costs of upgrading, considering factors like computational resources, data reprocessing, integration efforts, and projected performance gains impacting business metrics.
You can see that for the 45 models we benchmarked, there is a 1.35x latency improvement (geomean for the 45 models). You can see that for the 33 models we benchmarked, there is around 2x performance improvement (geomean for the 33 models). We benchmarked 45 models using the scripts from the TorchBench repo.
They enable applications requiring very low latency or local data processing using familiar APIs and tool sets. Through comparative benchmarking tests, we illustrate how deploying FMs in Local Zones closer to end users can significantly reduce latencya critical factor for real-time applications such as conversational AI assistants.
Although you can integrate the model directly into an application, the approach that works well for production-grade applications is to deploy the model behind an endpoint and then invoke the endpoint via a RESTful API call to obtain the inference. However, you can use any other benchmarking tool.
With so many SaaS metrics floating around, and even more opinions on when and how to use them, it can be hard to know if you’re measuring what really matters. Leading SaaS expert, Dave Kellogg, and ChurnZero CEO, You Mon Tsang, sat down to answer all the questions you want to know about SaaS metrics like ARR, NRR, GRR, LTV, and CAC (i.e.,
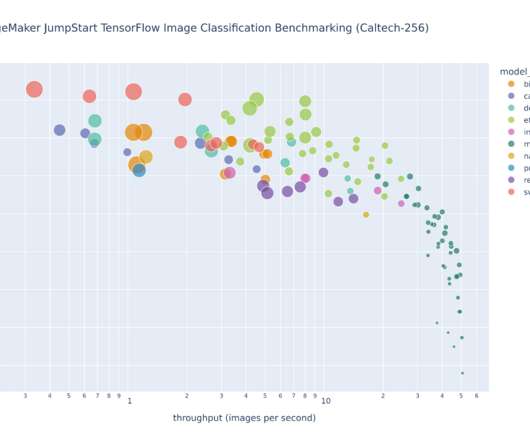
The former question addresses model selection across model architectures, while the latter question concerns benchmarking trained models against a test dataset. This post provides details on how to implement large-scale Amazon SageMaker benchmarking and model selection tasks. swin-large-patch4-window7-224 195.4M efficientnet-b5 29.0M
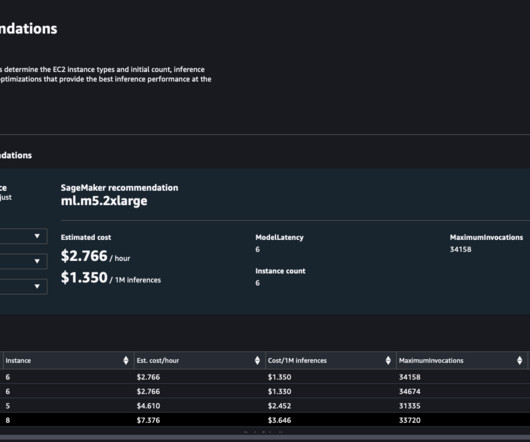
Each machine learning (ML) system has a unique service level agreement (SLA) requirement with respect to latency, throughput, and cost metrics. An advanced job is a custom load test job that allows you to perform extensive benchmarks based on your ML application SLA requirements, such as latency, concurrency, and traffic pattern.
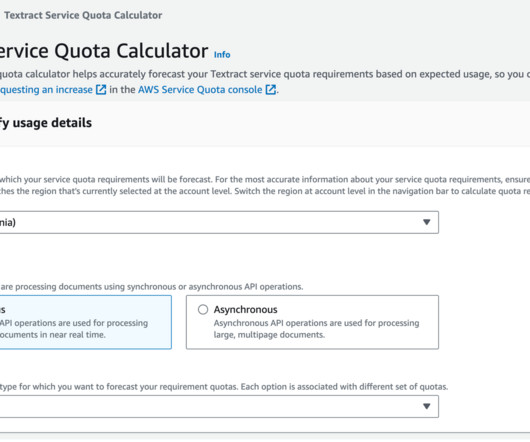
You can save time, money, and labor by implementing classifications in your workflow, and documents go to downstream applications and APIs based on document type. This helps you avoid throttling limits on API calls due to polling the Get* APIs. Model monitoring The performance of ML models is monitored for degradation over time.
From there, we dive into how you can track and understand the metrics and performance of the SageMaker endpoint utilizing Amazon CloudWatch metrics. We first benchmark the performance of our model on a single instance to identify the TPS it can handle per our acceptable latency requirements. Metrics to track.
Consequently, no other testing solution can provide the range and depth of testing metrics and analytics. And testingRTC offers multiple ways to export these metrics, from direct collection from webhooks, to downloading results in CSV format using the REST API. Happy days! You can check framerate information for video here too.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
For example, you can immediately start detecting entities such as people, places, commercial items, dates, and quantities via the Amazon Comprehend console , AWS Command Line Interface , or Amazon Comprehend APIs. In this post, we walk you through the benchmarking process and the results we obtained while working on subsampled datasets.
In addition, all SageMaker real-time endpoints benefit from built-in capabilities to manage and monitor models, such as including shadow variants , auto scaling , and native integration with Amazon CloudWatch (for more information, refer to CloudWatch Metrics for Multi-Model Endpoint Deployments ).
All the training and evaluation metrics were inspected manually from Amazon Simple Storage Service (Amazon S3). For every epoch in our training, we were already sending our training metrics through stdOut in the script. This allows us to compare training metrics like accuracy and precision across multiple runs as shown below.
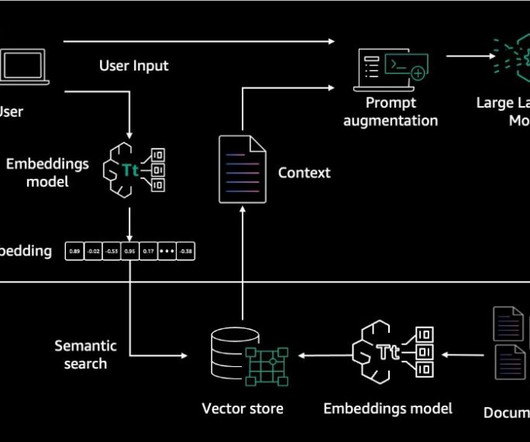
In addition, they use the developer-provided instruction to create an orchestration plan and then carry out the plan by invoking company APIs and accessing knowledge bases using Retrieval Augmented Generation (RAG) to provide an answer to the user’s request. In Part 1, we focus on creating accurate and reliable agents.
This is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading artificial intelligence (AI) companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon through a single API. These metrics will assess how well a machine-generated summary compares to one or more reference summaries.
Its not just about tracking basic metrics anymoreits about gaining comprehensive insights that drive strategic decisions. Key Metrics for Measuring Success Tracking the right performance indicators separates thriving call centers from struggling operations. This metric transforms support from cost center to growth driver.
Examples of tools you can use to advance sustainability initiatives are: Amazon Bedrock – a fully managed service that provides access to high-performing FMs from leading AI companies through a single API, enabling you to choose the right model for your sustainability use cases.
The goal of NAS is to find the optimal architecture for a given problem by searching over a large set of candidate architectures using techniques such as gradient-free optimization or by optimizing the desired metrics. The performance of the architecture is typically measured using metrics such as validation loss. training.py ).
Success Metrics for the Team. Ultimately, the biggest success metric for the Champion is to be able to show the Executive Sponsor and key Stakeholders that real business value has been gained through the use of customer journey analytics. Success Metrics for the Project. Success Metrics for the Business. Churn Rate.
We also provide insights on how to achieve optimal results for different dataset sizes and use cases, backed by experimental data and performance metrics. Tools and APIs – For example, when you need to teach Anthropic’s Claude 3 Haiku how to use your APIs well. We focus on the task of answering questions about the table.
Syne Tune allows us to find a better hyperparameter configuration that achieves a relative improvement between 1-4% compared to default hyperparameters on popular GLUE benchmark datasets. Furthermore, we add another callback function to Hugging Face’s Trainer API that reports the validation performance after each epoch back to Syne Tune.
This involves benchmarking new models against our current selections across various metrics, running A/B tests, and gradually incorporating high-performing models into our production pipeline. API design Account summary generation requests are handled asynchronously to eliminate client wait times for responses.
Define goals and metrics – The function needs to deliver value to the organization in different ways. Establish regular cadence – The group should come together regularly to review their goals and metrics. This allows the workload to be implemented to achieve the desired goals of the organization.
Desired target metrics, improvement monitoring, and convergence detection monitors the performance of the model and assists with early stopping if the models don’t improve after a defined number of training jobs. Autotune uses best practices as well as internal benchmarks for selecting the appropriate ranges.
Ensure you find benchmarks and determine prompt response times for your business for the asynchronous communication channels like Facebook, SMS, and email. You can make your customers feel special through controlled APIs, customer segmentation, and user metrics mapping. Personalize Customer Experience.
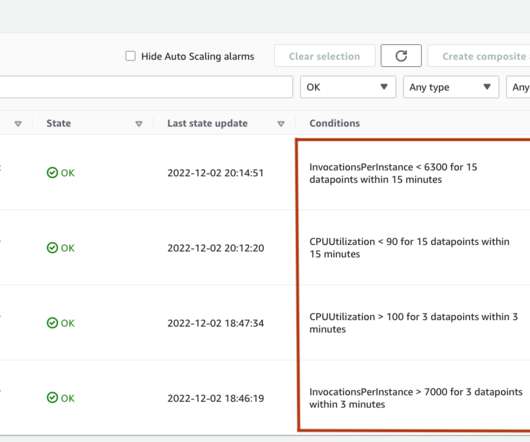
In addition, you can now use Application Auto Scaling with provisioned concurrency to address inference traffic dynamically based on target metrics or a schedule. To specify the metrics and target values for a scaling policy, you can configure a target-tracking scaling policy. Define the scaling policy as a JSON block in a text file.
With so many SaaS metrics floating around, and even more opinions on when and how to use them, it can be hard to know if youre measuring what really matters. all the metrics your CEO and CFO care about) and set the context for their usage. all the metrics your CEO and CFO care about) and set the context for their usage.
Our benchmarks show up to 46% price performance benefit after enabling heterogeneous clusters in a CPU-bound TensorFlow computer vision model training. Performance benchmark results. The quick way to identify a CPU bottleneck is to monitor CPU and GPU utilization metrics for SageMaker training jobs in Amazon CloudWatch.
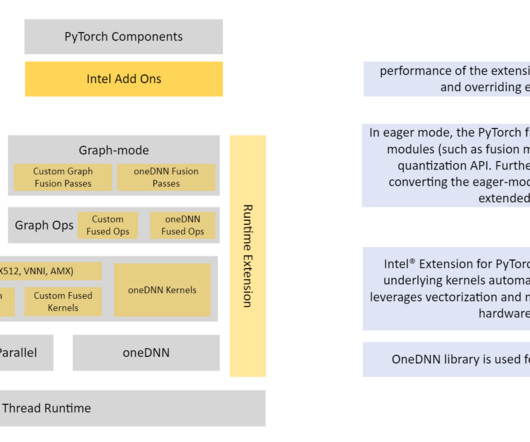
Refer to the appendix for instance details and benchmark data. Quantizing the model in PyTorch is possible with a few APIs from Intel PyTorch extensions. Benchmark data The following table compares the cost and relative performance between c5 and c6 instances. times greater with INT8 quantization. Refer to invoke-INT8.py
as_trt_engine(output_fpath=trt_path, profiles=profiles) gpt2_trt = GPT2TRTDecoder(gpt2_engine, metadata, config, max_sequence_length=42, batch_size=10) Latency comparison: PyTorch vs. TensorRT JMeter is used for performance benchmarking in this project. implement the model and the inference API. model_fp16.onnx gpt2 and predictor.py
If your website has a lot of indexed public facing pages, then this metric might matter a lot more. Site load can vary from pages loading, resources downloading, videos buffering, API calls or requests being made, etc. Audience > Benchmarking > Devices. Audience > Benchmarking > Channels.
Training and validation loss is just one of the metrics needed to pick the best model for the use case. We trained this model from scratch with the default hyperparameters, so we could have a benchmark to evaluate the rest of the models. Automatic model tuning will monitor the log and parse the objective metrics.
Furthermore, we benchmark the ResNet50 model and see the performance benefits that ONNX provides when compared to PyTorch and TensorRT versions of the same model, using the same input. The testing benchmark results are as follows: PyTorch – 176 milliseconds, cold start 6 seconds TensorRT – 174 milliseconds, cold start 4.5 seconds to 1.61
In this post, we explore the latest features introduced in this release, examine performance benchmarks, and provide a detailed guide on deploying new LLMs with LMI DLCs at high performance. Before introducing this API, the KV cache was recomputed for any newly added requests.
As is explained in the post Amazon SageMaker JumpStart models and algorithms now available via API , the following artifacts are required to train a pre-built algorithm via the SageMaker SDK: Its framework-specific container image, containing all the required dependencies for training and inference. . Benchmarking the trained models.
After cycles of research and initial benchmarking efforts, CCC determined SageMaker was a perfect fit to meet a majority of their production requirements, especially the guaranteed uptime SageMaker provides for most of its inference components. Step-by-step solution Step 1 A client makes a request to the AWS API Gateway endpoint.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content