This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Overview of Pixtral 12B Pixtral 12B, Mistrals inaugural VLM, delivers robust performance across a range of benchmarks, surpassing other open models and rivaling larger counterparts, according to Mistrals evaluation. Performance metrics and benchmarks Pixtral 12B is trained to understand both natural images and documents, achieving 52.5%
adds new APIs to customize GraphStorm pipelines: you now only need 12 lines of code to implement a custom node classification training loop. Based on customer feedback for the experimental APIs we released in GraphStorm 0.2, introduces refactored graph ML pipeline APIs. Specifically, GraphStorm 0.3 In addition, GraphStorm 0.3
This post explores these relationships via a comprehensive benchmarking of LLMs available in Amazon SageMaker JumpStart, including Llama 2, Falcon, and Mistral variants. We provide theoretical principles on how accelerator specifications impact LLM benchmarking. Additionally, models are fully sharded on the supported instance.
Here are some examples of these metrics: Retrieval component Context precision Evaluates whether all of the ground-truth relevant items present in the contexts are ranked higher or not. Evaluate RAG components with Foundation models We can also use a Foundation Model as a judge to compute various metrics for both retrieval and generation.
As attendees circulate through the GAIZ, subject matter experts and Generative AI Innovation Center strategists will be on-hand to share insights, answer questions, present customer stories from an extensive catalog of reference demos, and provide personalized guidance for moving generative AI applications into production.
The device further processes this response, including text-to-speech (TTS) conversion for voice agents, before presenting it to the user. They enable applications requiring very low latency or local data processing using familiar APIs and tool sets.
An alternative approach to routing is to use the native tool use capability (also known as function calling) available within the Bedrock Converse API. In this scenario, each category or data source would be defined as a ‘tool’ within the API, enabling the model to select and use these tools as needed.
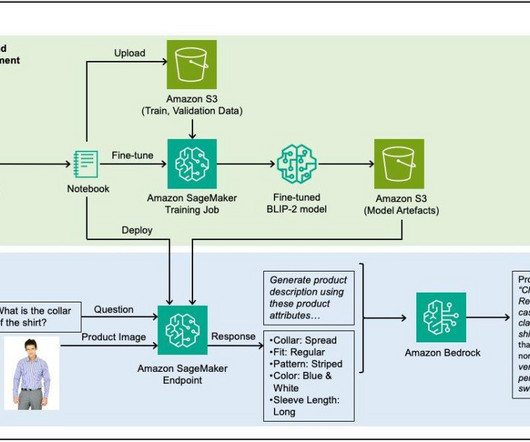
Next, we present the solution architecture and process flows for machine learning (ML) model building, deployment, and inferencing. Acting as a model hub, JumpStart provided a large selection of foundation models and the team quickly ran their benchmarks on candidate models. The Amazon API Gateway receives the PUT request (step 1).
These include metrics such as ROUGE or cosine similarity for text similarity, and specific benchmarks for assessing toxicity (Detoxify), prompt stereotyping (cross-entropy loss), or factual knowledge (HELM, LAMA). Refer to Getting started with the API to set up your environment to make Amazon Bedrock requests through the AWS API.
Together, these AI-driven tools and technologies aren’t just reshaping how brands perform marketing tasks; they’re setting new benchmarks for what’s possible in customer engagement. From our experience, artifact server has some limitations, such as limits on artifact size (because of sending it using REST API).
Automated API testing stands as a cornerstone in the modern software development cycle, ensuring that applications perform consistently and accurately across diverse systems and technologies. Continuous learning and adaptation are essential, as the landscape of API technology is ever-evolving.
Jina Embeddings v2 is the preferred choice for experienced ML scientists for the following reasons: State-of-the-art performance – We have shown on various text embedding benchmarks that Jina Embeddings v2 models excel on tasks such as classification, reranking, summarization, and retrieval. The answer should only use the presented context.
This is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading artificial intelligence (AI) companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon through a single API. 4525) attained with the fine-tuned FLAN-T5 XL model presented in part 1 of this blog series.
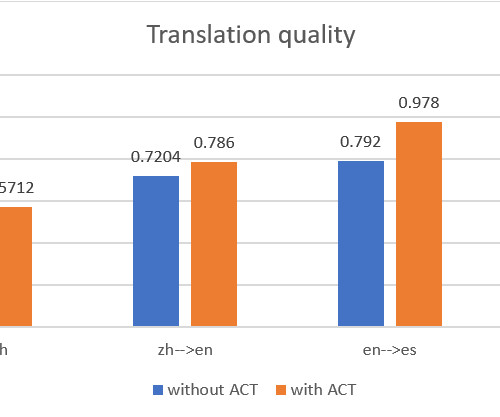
In this post, we present a solution that D2L.ai We demonstrate how to use the AWS Management Console and Amazon Translate public API to deliver automatic machine batch translation, and analyze the translations between two language pairs: English and Chinese, and English and Spanish.
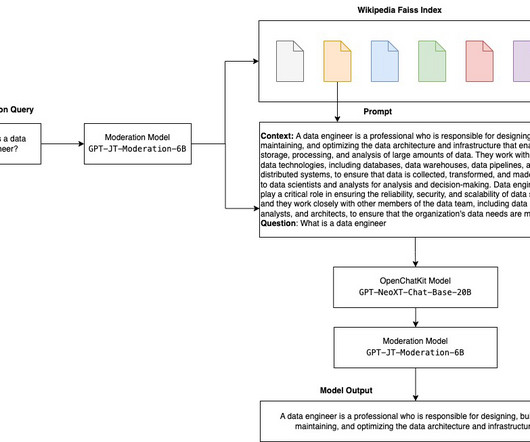
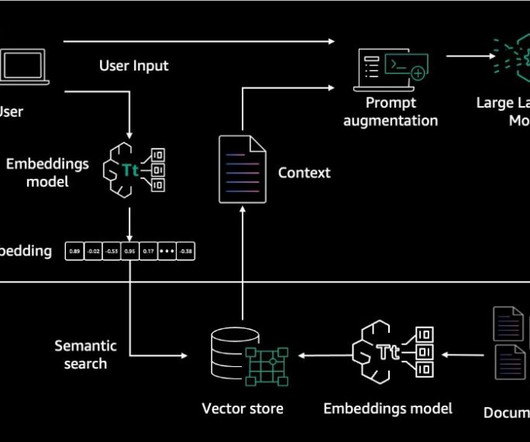
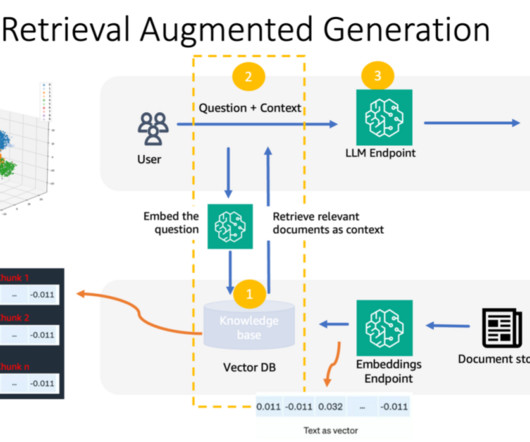
To overcome this limitation and provide dynamism and adaptability to knowledge base changes, we decided to follow a Retrieval Augmented Generation (RAG) approach, in which the LLMs are presented with relevant information extracted from external data sources to provide up-to-date data without the need to retrain the models.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models from leading AI companies and Amazon via a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI. A limitation of the approach is its larger computational cost.
In addition, deployments are now as simple as calling Boto3 SageMaker APIs and attaching the proper auto scaling policies. We already had an API layer on top of our models for model management and inference. Autocomplete The autocomplete models (sequence to sequence) presented a distinct set of requirements. 2xlarge instances.
On Hugging Face, the Massive Text Embedding Benchmark (MTEB) is provided as a leaderboard for diverse text embedding tasks. It currently provides 129 benchmarking datasets across 8 different tasks on 113 languages. medium instance to demonstrate deploying the model as an API endpoint using an SDK through SageMaker JumpStart.
For example, you can immediately start detecting entities such as people, places, commercial items, dates, and quantities via the Amazon Comprehend console , AWS Command Line Interface , or Amazon Comprehend APIs. In this post, we walk you through the benchmarking process and the results we obtained while working on subsampled datasets.
In terms of resulting speedups, the approximate order is programming hardware, then programming against PBA APIs, then programming in an unmanaged language such as C++, then a managed language such as Python. The CUDA API and SDK were first released by NVIDIA in 2007. GPU PBAs, 4% other PBAs, 4% FPGA, and 0.5%
When ML models deployed on instances receive API calls from a large number of clients, a random distribution of requests can work very well when there is not a lot of variability in your requests and responses. Finally, we present a comparative analysis of latency improvements with LOR over the default routing strategy of random routing.
In this blog post, we’ll first present our latest performance improvements in the SageMaker model parallel library. Finally, we’ll benchmark performance of 13B, 50B, and 100B parameter auto-regressive models and wrap up with future work. Benchmarking performance. . — Emad Mostaque, Founder and CEO of Stability AI.
The application’s frontend is accessible through Amazon API Gateway , using both edge and private gateways. Amazon Bedrock offers a practical environment for benchmarking and a cost-effective solution for managing workloads due to its serverless operation. The tool is able to correlate multiple datasets and present a response.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
The typical ESG workflow consists of multiple phases, each presenting unique pain points. Consider the following guidelines: Implement real-time monitoring – Set up monitoring systems to track generative AI performance against sustainability benchmarks, focusing on efficiency and environmental impact.
Similar to the process of PyTorch integration with C++ code, Neuron CustomOps requires a C++ implementation of an operator via a NeuronCore-ported subset of the Torch C++ API. Finally, the custom library is built by calling the load API. It only defines the shape of the output tensor but not the actual values.
An extensible retrieval system enabling you to augment bot responses with information from a document repository, API, or other live-updating information source at inference time. The increasing scale and size of deep learning models present obstacles to successfully deploy these models in generative AI applications.
In addition, they use the developer-provided instruction to create an orchestration plan and then carry out the plan by invoking company APIs and accessing knowledge bases using Retrieval Augmented Generation (RAG) to provide an answer to the user’s request. In Part 1, we focus on creating accurate and reliable agents.
Amazon Bedrock is a fully managed service that makes foundation models (FMs) from leading artificial intelligence (AI) startups and Amazon available through an API, so you can choose from a wide range of FMs to find the model that is best suited for your use case. For example, you can look for specific keys in the document.
This notebook presents an end-to-end example of how to compile a Stable Diffusion model, save the compiled Neuron models, and load it into the runtime for inference. We compile the UNet for one batch (by using input tensors with one batch), then use the torch_neuronx.DataParallel API to load this single batch model onto each core.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon through a single API, along with a broad set of capabilities you need to build generative AI applications with security, privacy, and responsible AI.
Prospecting, opportunity progression, and customer engagement present exciting opportunities to utilize generative AI, using historical data, to drive efficiency and effectiveness. It focuses on precision, measuring how much of the generated content is present in the reference data. The following diagram illustrates this architecture.
They show the usage of various SageMaker and JumpStart APIs. This notebook demonstrates how to deploy AlexaTM 20B through the JumpStart API and run inference. This notebook presents how to overcome this problem by using SageMaker and fair algorithms in the context of linear learners. This is called zero-shot in-context learning.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
As part of this post, we first introduce general best practices for fine-tuning Anthropic’s Claude 3 Haiku on Amazon Bedrock, and then present specific examples with the TAT- QA dataset (Tabular And Textual dataset for Question Answering).
as_trt_engine(output_fpath=trt_path, profiles=profiles) gpt2_trt = GPT2TRTDecoder(gpt2_engine, metadata, config, max_sequence_length=42, batch_size=10) Latency comparison: PyTorch vs. TensorRT JMeter is used for performance benchmarking in this project. implement the model and the inference API. model_fp16.onnx gpt2 and predictor.py
In this post, we explore the latest features introduced in this release, examine performance benchmarks, and provide a detailed guide on deploying new LLMs with LMI DLCs at high performance. Before introducing this API, the KV cache was recomputed for any newly added requests. get('text') !=
In this post, we present a new open-source library that takes a different stand on DL training: MosaicML Composer is a speed-centric library whose primary objective is to make neural network training scripts faster via algorithmic innovation. Speedup techniques implemented in Composer can be accessed with its functional API.
Model choices – SageMaker JumpStart offers a selection of state-of-the-art ML models that consistently rank among the top in industry-recognized HELM benchmarks. However, off-the-shelf LLMs present limitations: Their offline training renders them unaware of up-to-date information. Lewis et al.
Solution overview In this section, we present the overall workflow and explain the approach. We use the Recognizing Textual Entailment dataset from the GLUE benchmarking suite. Then the payload is passed to the SageMaker endpoint invoke API via the BotoClient to simulate real user requests. training.py ).
Customers have to leave their development environment to use academic tools and benchmarking sites, which require highly-specialized knowledge. We surveyed existing open-source evaluation frameworks and designed FMEval evaluation API with extensibility in mind. We use datasets such as BoolQ , NaturalQuestions , and TriviaQA.
In this post, we provide an overview of how to deploy and run inference with the AlexaTM 20B model programmatically through JumpStart APIs, available in the SageMaker Python SDK. Note that we need to pass Predictor class when we deploy model through Model class, #for being able to run inference through the sagemaker API.
As noted in the 2019 Dimension Data Customer Experience (CX) Benchmarking report: 88% of contact center decision-makers expect self-service volumes to increase over the next 12 months. Agents will be presented with increasingly more complex situations which will require more engagement, insight and analysis.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content