This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Using its enterprise software, FloTorch conducted an extensive comparison between Amazon Nova models and OpenAIs GPT-4o models with the Comprehensive Retrieval Augmented Generation (CRAG) benchmark dataset. FloTorch used these queries and their ground truth answers to create a subset benchmark dataset.
You can see that for the 45 models we benchmarked, there is a 1.35x latency improvement (geomean for the 45 models). You can see that for the 33 models we benchmarked, there is around 2x performance improvement (geomean for the 33 models). We benchmarked 45 models using the scripts from the TorchBench repo.
You can also either use the SageMaker Canvas UI, which provides a visual interface for building and deploying models without needing to write any code or have any ML expertise, or use its automated machine learning (AutoML) APIs for programmatic interactions.
Amazon Bedrock is a fully managed service that makes FMs from leading AI startups and Amazon available through an API, so you can choose from a wide range of FMs to find the model that is best suited for your use case. Solution overview The solution comprises two main steps: Generate synthetic data using the Amazon Bedrock InvokeModel API.
These include metrics such as ROUGE or cosine similarity for text similarity, and specific benchmarks for assessing toxicity (Detoxify), prompt stereotyping (cross-entropy loss), or factual knowledge (HELM, LAMA). Refer to Getting started with the API to set up your environment to make Amazon Bedrock requests through the AWS API.
The team’s early benchmarking results show 7.3 The baseline model used in these benchmarking is a multi-layer perceptron neural network with seven dense fully connected layers and over 200 parameters. The following table summarizes the benchmarking result on ml.p3.16xlarge SageMaker training instances. Number of Instances.
SageMaker makes it easy to deploy models into production directly through API calls to the service. It’s a low-level API available for Java, C++, Go, JavaScript, Node.js, PHP, Ruby, and Python. It’s a low-level API available for Java, C++, Go, JavaScript, Node.js, PHP, Ruby, and Python.
And testingRTC offers multiple ways to export these metrics, from direct collection from webhooks, to downloading results in CSV format using the REST API. Flip the script With testingRTC, you only need to write scripts once, you can then run them multiple times and scale them up or down as you see fit. Happy days!
The former question addresses model selection across model architectures, while the latter question concerns benchmarking trained models against a test dataset. This post provides details on how to implement large-scale Amazon SageMaker benchmarking and model selection tasks. swin-large-patch4-window7-224 195.4M efficientnet-b5 29.0M
We first benchmark the performance of our model on a single instance to identify the TPS it can handle per our acceptable latency requirements. Note that the model container also includes any custom inference code or scripts that you have passed for inference. Any issues related to end-to-end latency can then be isolated separately.
The code to invoke the pipeline script is available in the Studio notebooks, and we can change the hyperparameters and input/output when invoking the pipeline. This is quite different from our earlier method where we had all the parameters hard coded within the scripts and all the processes were inextricably linked.
To get started, follow Modify a PyTorch Training Script to adapt SMPs’ APIs in your training script. In this section, we only call out a few main steps with code snippets from the ready-to-use training script train_gpt_simple.py. The notebook uses the script data_prep_512.py Benchmarking performance.
We compile the UNet for one batch (by using input tensors with one batch), then use the torch_neuronx.DataParallel API to load this single batch model onto each core. Load the UNet model onto two Neuron cores using the torch_neuronx.DataParallel API. If you have a custom inference script, you need to provide that instead.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon through a single API, along with a broad set of capabilities you need to build generative AI applications with security, privacy, and responsible AI.
Similar to the process of PyTorch integration with C++ code, Neuron CustomOps requires a C++ implementation of an operator via a NeuronCore-ported subset of the Torch C++ API. Finally, the custom library is built by calling the load API. For more information, refer to Custom Operators API Reference Guide [Experimental].
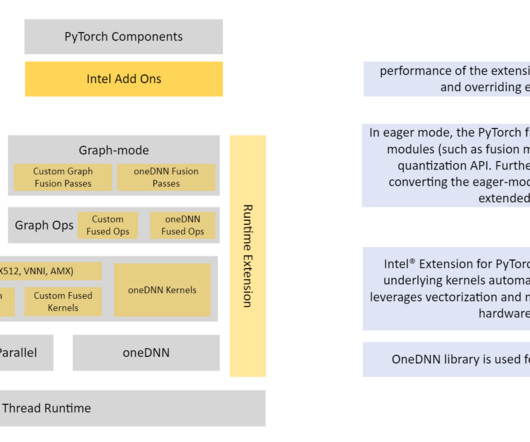
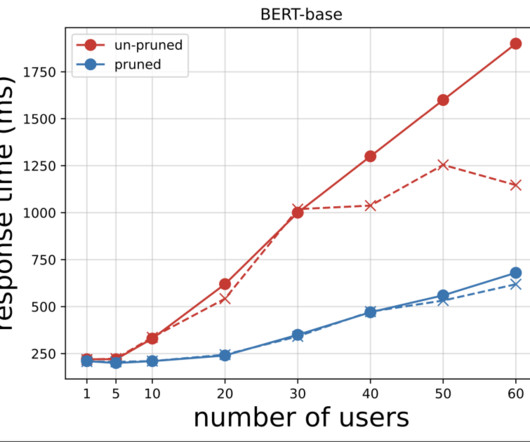
Refer to the appendix for instance details and benchmark data. Use the supplied Python scripts for quantization. Run the provided Python test scripts to invoke the SageMaker endpoint for both INT8 and FP32 versions. Quantizing the model in PyTorch is possible with a few APIs from Intel PyTorch extensions.
Finally, we’ll benchmark performance of 13B, 50B, and 100B parameter auto-regressive models and wrap up with future work. A ready-to-use training script for GPT-2 model can be found at train_gpt_simple.py. For training a different model type, you can follow the API document to learn about how to apply SMP APIs.
Our benchmarks show up to 46% price performance benefit after enabling heterogeneous clusters in a CPU-bound TensorFlow computer vision model training. Performance benchmark results. For more information, refer to Using the SageMaker Python SDK and Using the Low-Level SageMaker APIs. Heterogeneous clusters at Mobileye.
The following figure shows a performance benchmark of fine-tuning a RoBERTa model on Amazon EC2 p4d.24xlarge inference with AWS Graviton processors for details on AWS Graviton-based instance inference performance benchmarks for PyTorch 2.0. Run your DLC container with a model training script to fine-tune the RoBERTa model.
This text-to-video API generates high-quality, realistic videos quickly from text and images. Customizable environment – SageMaker HyperPod offers the flexibility to customize your cluster environment using lifecycle scripts. Video generation has become the latest frontier in AI research, following the success of text-to-image models.
For example, you can immediately start detecting entities such as people, places, commercial items, dates, and quantities via the Amazon Comprehend console , AWS Command Line Interface , or Amazon Comprehend APIs. In this post, we walk you through the benchmarking process and the results we obtained while working on subsampled datasets.
In this post, we provide an overview of how to deploy and run inference with the AlexaTM 20B model programmatically through JumpStart APIs, available in the SageMaker Python SDK. To use a large language model in SageMaker, you need an inferencing script specific for the model, which includes steps like model loading, parallelization and more.
Briefly, this is made possible by an installation script specified by CustomActions in the YAML file used for creating the ParallelCluster (see Create ParallelCluster ). You can invoke neuron-top during the training script run to inspect NeuronCore utilization at each node. Complete instructions can be found on GitHub.
Snowflake Arctic is a family of enterprise-grade large language models (LLMs) built by Snowflake to cater to the needs of enterprise users, exhibiting exceptional capabilities (as shown in the following benchmarks ) in SQL querying, coding, and accurately following instructions. To learn more, refer to API documentation.
We use the Recognizing Textual Entailment dataset from the GLUE benchmarking suite. Phrase 2: A bearded man pulls a rope We load the textual recognizing entailment dataset from the GLUE benchmarking suite via the dataset library from Hugging Face within our training script (./training.py training.py ).
DL scripts often require boilerplate code, notably the aforementioned double for loop structure that splits the dataset into minibatches and the training into epochs. At the time of this writing, it supports PyTorch and includes 25 techniques—called methods in the MosaicML world—along with standard models, datasets, and benchmarks.
In addition, they use the developer-provided instruction to create an orchestration plan and then carry out the plan by invoking company APIs and accessing knowledge bases using Retrieval Augmented Generation (RAG) to provide an answer to the user’s request. In Part 1, we focus on creating accurate and reliable agents.
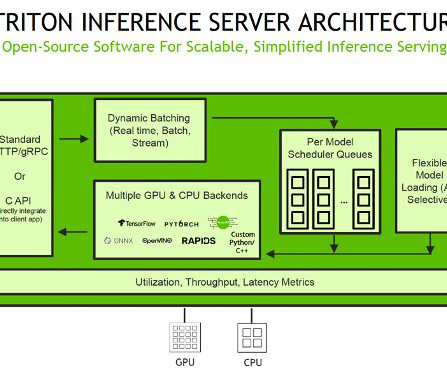
To use TensorRT as a backend for Triton Inference Server, you need to create a TensorRT engine from your trained model using the TensorRT API. The trtexec tool has three main purposes: Benchmarking networks on random or user-provided input data. script from the following cell. For this post, we use the trtexec CLI tool.
Syne Tune allows us to find a better hyperparameter configuration that achieves a relative improvement between 1-4% compared to default hyperparameters on popular GLUE benchmark datasets. training script. On a text classification problem, this leads to an additional boost in accuracy of approximately 5% compared to the default model.
Welocalize benchmarks the performance of using LLMs and machine translations and recommends using LLMs as a post-editing tool. We use the custom terminology dictionary to compile frequently used terms within video transcription scripts. Amazon Translate has various unique benefits. Here’s an example.
Even if you already have a pre-trained model, it may still be easier to use its corollary in SageMaker and input the hyperparameters you already know rather than port it over and write a training script yourself. The training and inference scripts for the selected model or algorithm. Benchmarking the trained models.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon via a single API. Kojima et al. 2022) introduced an idea of zero-shot CoT by using FMs’ untapped zero-shot capabilities.
Pointillist can handle data in all forms, whether it is in tables, excel files, server logs, or 3rd party APIs. During onboarding, the data will remain on your Pointillist-hosted SFTP server until the customer success team has created and quality-checked the requisite ingestion script. Getting Data into Pointillist.
In 2018, BERT-large made its debut with its 340 million parameters and innovative transformer architecture, setting the benchmark for performance on NLP tasks. The endpoint comes pre-loaded with the model and ready to serve queries via an easy-to-use API and Python SDK, so you can hit the ground running.
As noted in the 2019 Dimension Data Customer Experience (CX) Benchmarking report: 88% of contact center decision-makers expect self-service volumes to increase over the next 12 months. These interactions will become longer – so traditional productivity measurements and benchmarks will no longer be relevant and will have to be redefined.
The Trainer class provides an API for feature-complete training in PyTorch. We observe that the adversarial trained model has a lower ASR, with an 62.21% decrease using the original model ASR as the benchmark. For more information about this up-and-coming topic, we encourage you to explore and test our script on your own.
In this scenario, the generative AI application, designed by the consumer, must interact with the fine-tuner backend via APIs to deliver this functionality to the end-users. Some models may be trained on diverse text datasets like internet data, coding scripts, instructions, or human feedback. 15K available FM reference Step 1.
Provides additional features like calendar management and benchmarking. month for up to 40k emails WhatsApp Business API – Starting at $0.0042 per WhatsApp Template message and $0.005 for session messages SMS, WhatsApp, Chat, and MMS – Starting at $0.05 Call monitoring and scripting are possible with 8×8.
And when you think about the range of features the latter offers at $49 per user per month — all 3 dialers, bulk SMS campaigns and workflows, live call monitoring , advanced analytics and reporting, API and webhooks, live call monitoring, and so much more, it is simply astounding. How are JustCall’s Sales Dialer and Mojo Dialer different?
Key Points CCaaS is paramount to successfully add a new communication channel You must consider the tone, scripts and pace of new channels Your Call Center must track the right KPIs for every new channel How to add a new communication channel in a call center? Integration with your current software (CRM, API etc.)
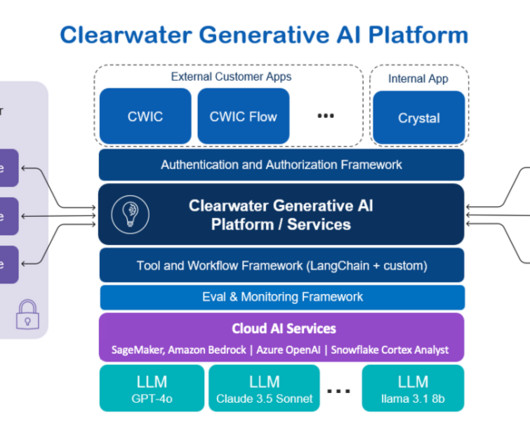
Crystal shares CWICs core functionalities but benefits from broader data sources and API access. Previously, it required a data scientist to write over 100 lines of code within an Amazon SageMaker Notebook to identify and retrieve the proper image, set the right training script, and import the right hyperparameters.
JustCall IQ is a key proposition of JustCall, enabling call centers with AI capabilities that fuel their sales metrics and set newer benchmarks. Five9’s call center software boasts features like – a live chat option, outbound dialer, call recording, and agent scripting. Recommended Read: What is Conversation Intelligence?
Call Recording and Analytics Software Call recordings are analyzed for important moments that indicate whether reps are following or deviating from their call plan/script. Dialogue Scripting for a Seamless User Experience and Empathy Good conversations require so much more than just a simple response.
Employee Engagement Analytics isnt just for customers; it benefits employee satisfaction too: Clear Feedback Loops : Metrics like average handle time (AHT) provide agents with clear performance benchmarks. API Strategies: Use API integration to connect disparate systems, ensuring smooth data flow. Absolutely.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content